University of Hertfordshire Data Classification Project 7COM1073
VerifiedAdded on 2022/09/02
|10
|1545
|17
Project
AI Summary
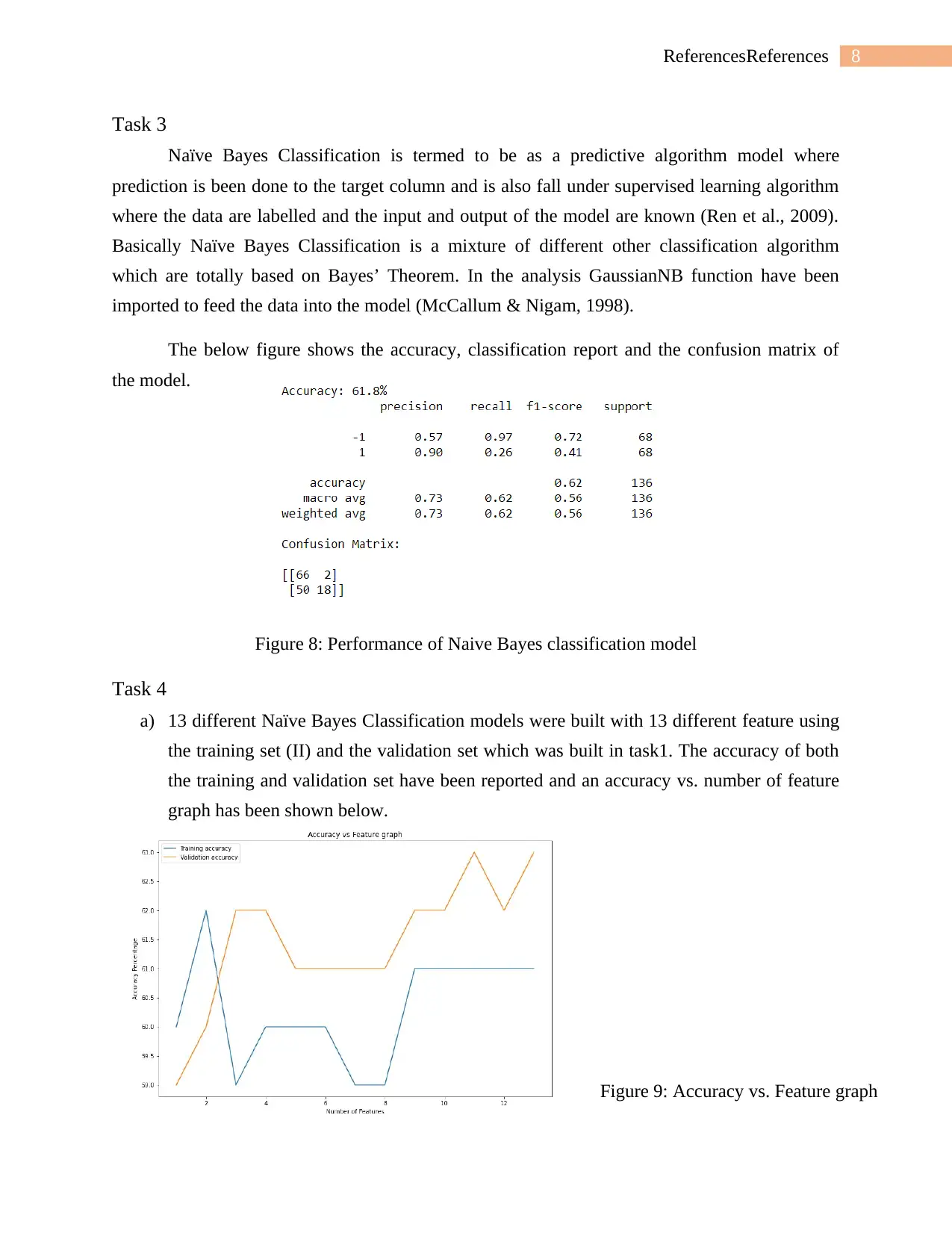
This project focuses on data classification for software defect prediction using machine learning techniques. The student implemented and evaluated a Naive Bayes classification model on a provided dataset containing static code metrics. The analysis involved data preprocessing, including handling of missing values and feature scaling. The project explored Principal Component Analysis (PCA) for dimensionality reduction and visualization of the data. The student built and evaluated multiple Naive Bayes models with different feature sets. The results, including accuracy, classification reports, and confusion matrices, were presented and discussed. The project concluded with an analysis of the model's performance and suggestions for future improvements, such as exploring other machine learning models and addressing data outliers. The student used Python with libraries like NumPy, Pandas, Matplotlib, Seaborn, and Scikit-learn to perform the analysis and present the findings. The goal was to assess the feasibility of an automated software defect prediction system.





1 out of 10
Related Documents






Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Copyright © 2020–2026 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.