Deakin MIS772: Predictive Analytics Assignment A2 Data Exploration
VerifiedAdded on 2022/12/16
|5
|1458
|253
Report
AI Summary
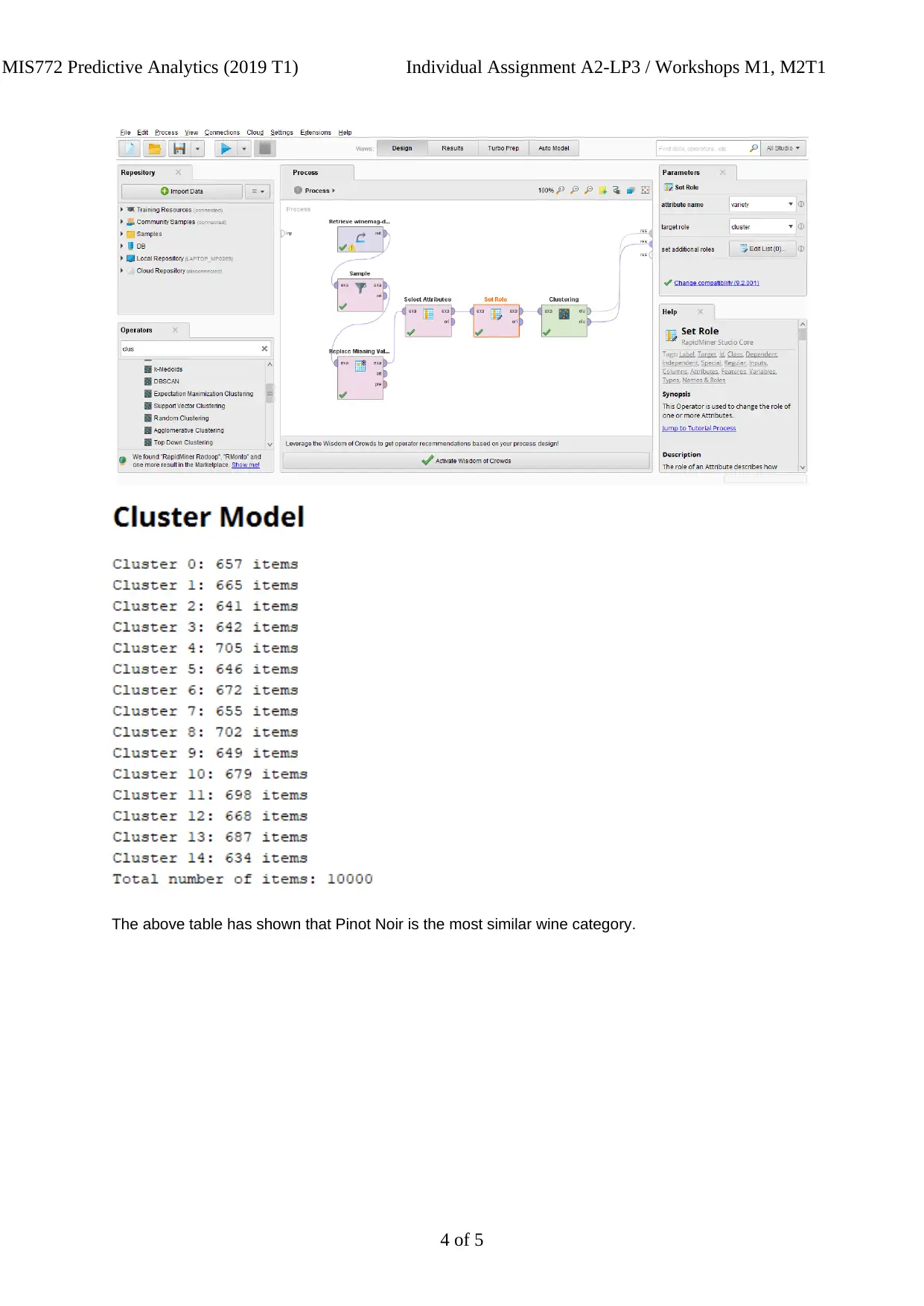
This report details the data exploration and preparation process undertaken for MIS772 Predictive Analytics Assignment A2. The assignment focuses on analyzing wine data using RapidMiner. The student begins by addressing the problem statement, which involves exploring wine tasting data to identify similarities between wines and estimate ratings. The report describes the steps taken to downsize the sample data and handle missing values, followed by the application of clustering techniques to group wine varieties and wineries. The executive summary provides context on the Australian wine market and the client's need to predict market demand. The data exploration section outlines the use of RapidMiner operators for data cleaning and attribute selection. The analysis focuses on identifying similar wine categories using clustering, with Pinot Noir being identified as the most similar. The report includes references to relevant research papers and demonstrates the student's ability to apply data mining techniques to address a business problem.



1 out of 5
Related Documents






Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Copyright © 2020–2026 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.