Data Handling and Business Intelligence Analysis Report - Semester 1
VerifiedAdded on 2023/01/12
|17
|3399
|81
Report
AI Summary
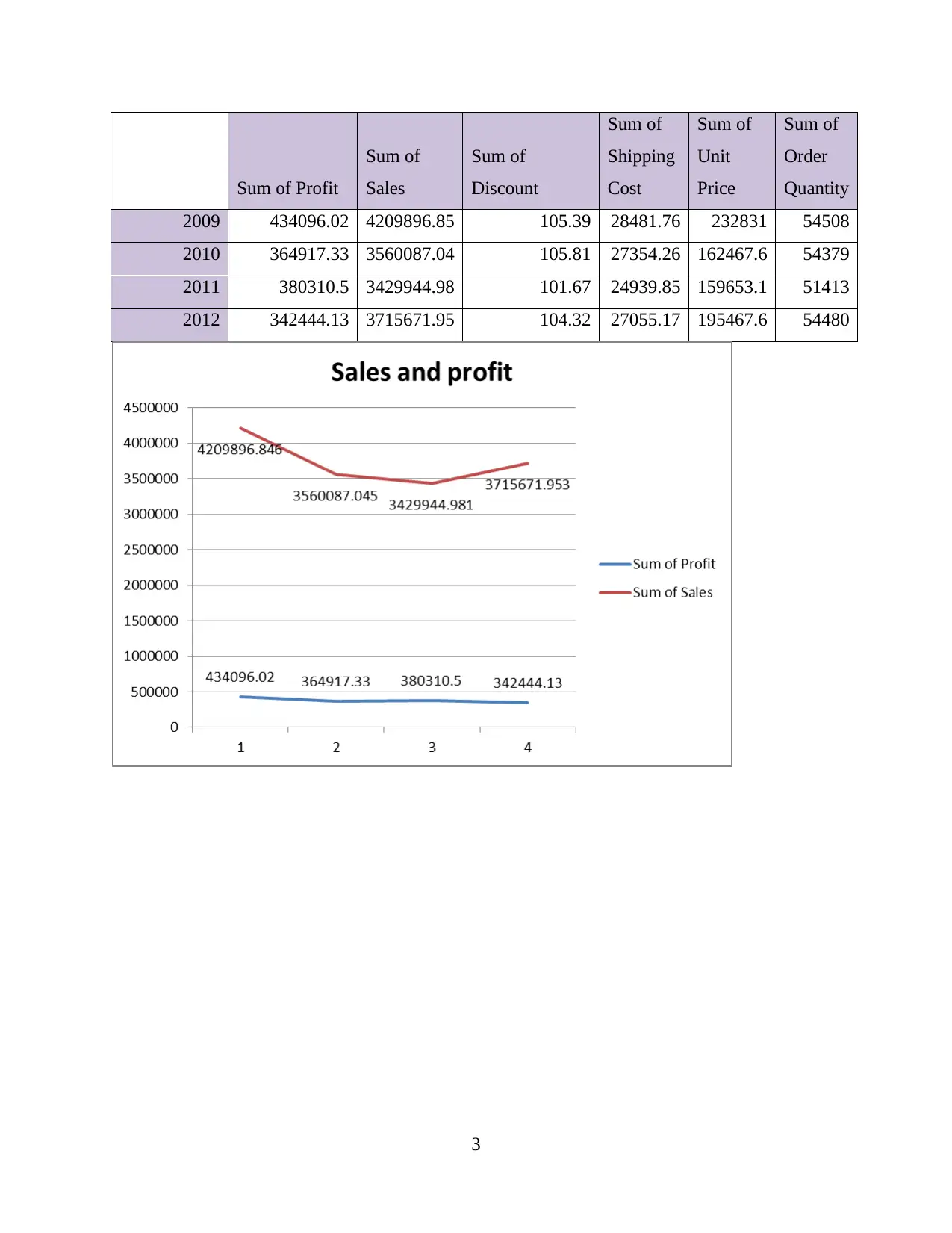
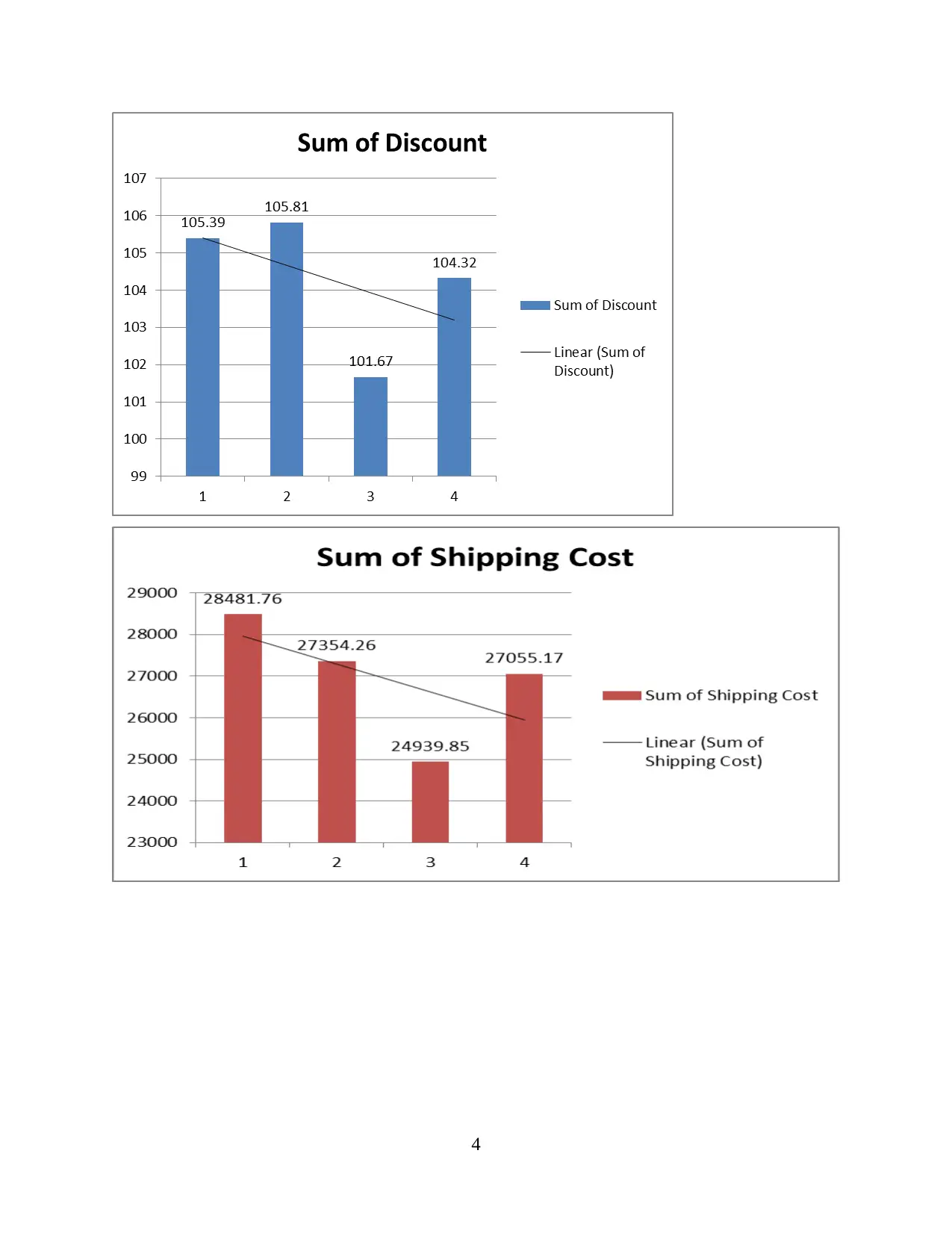
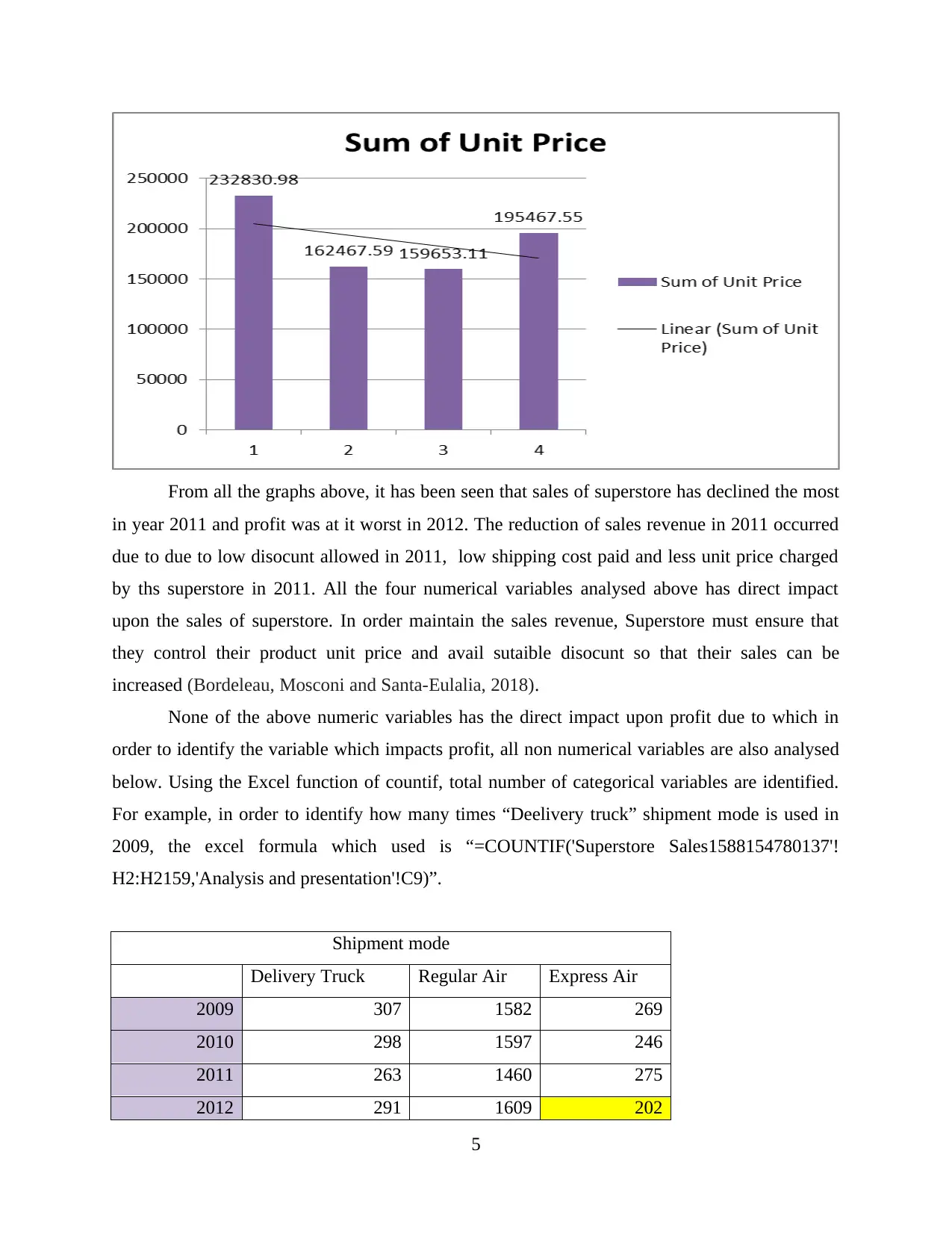
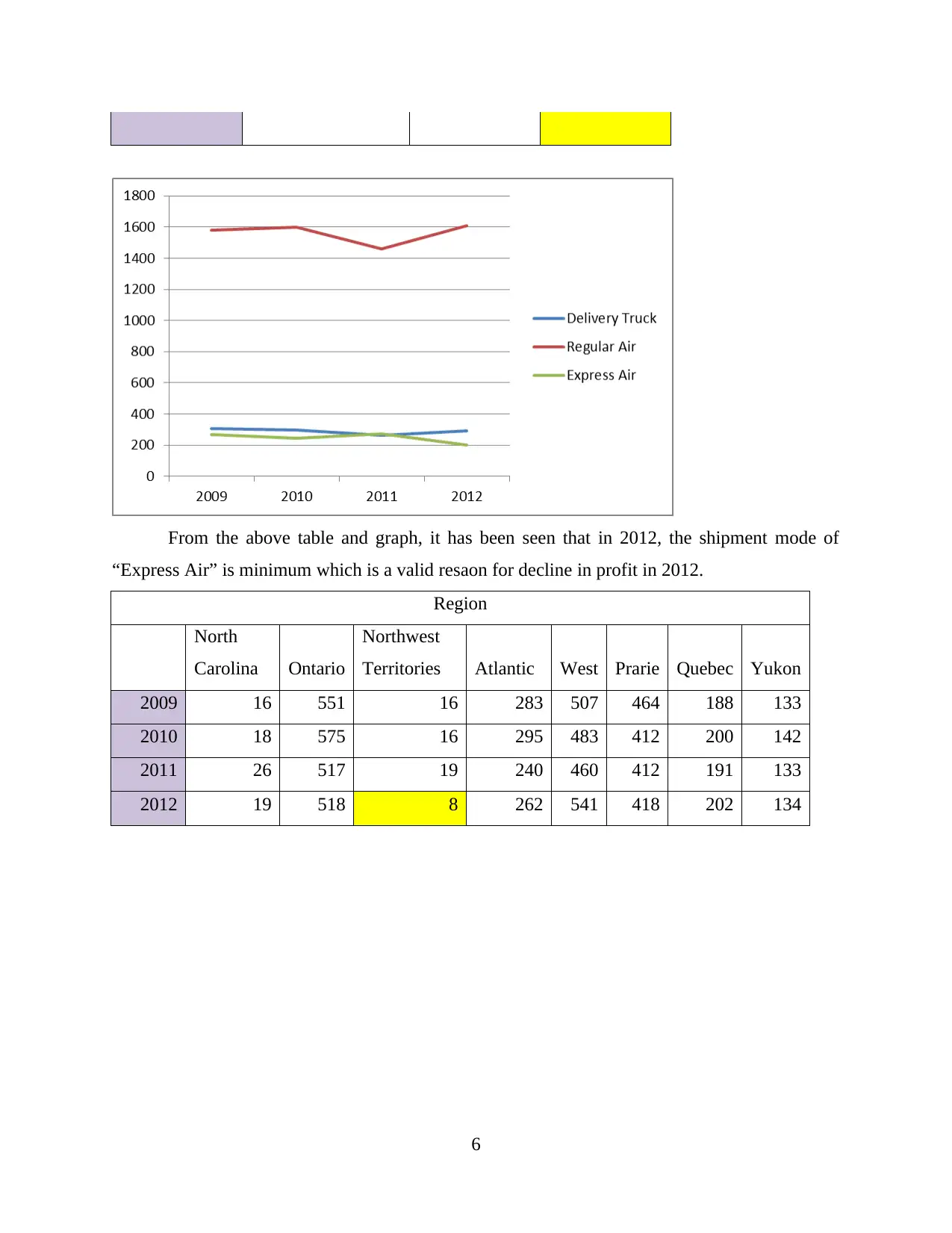
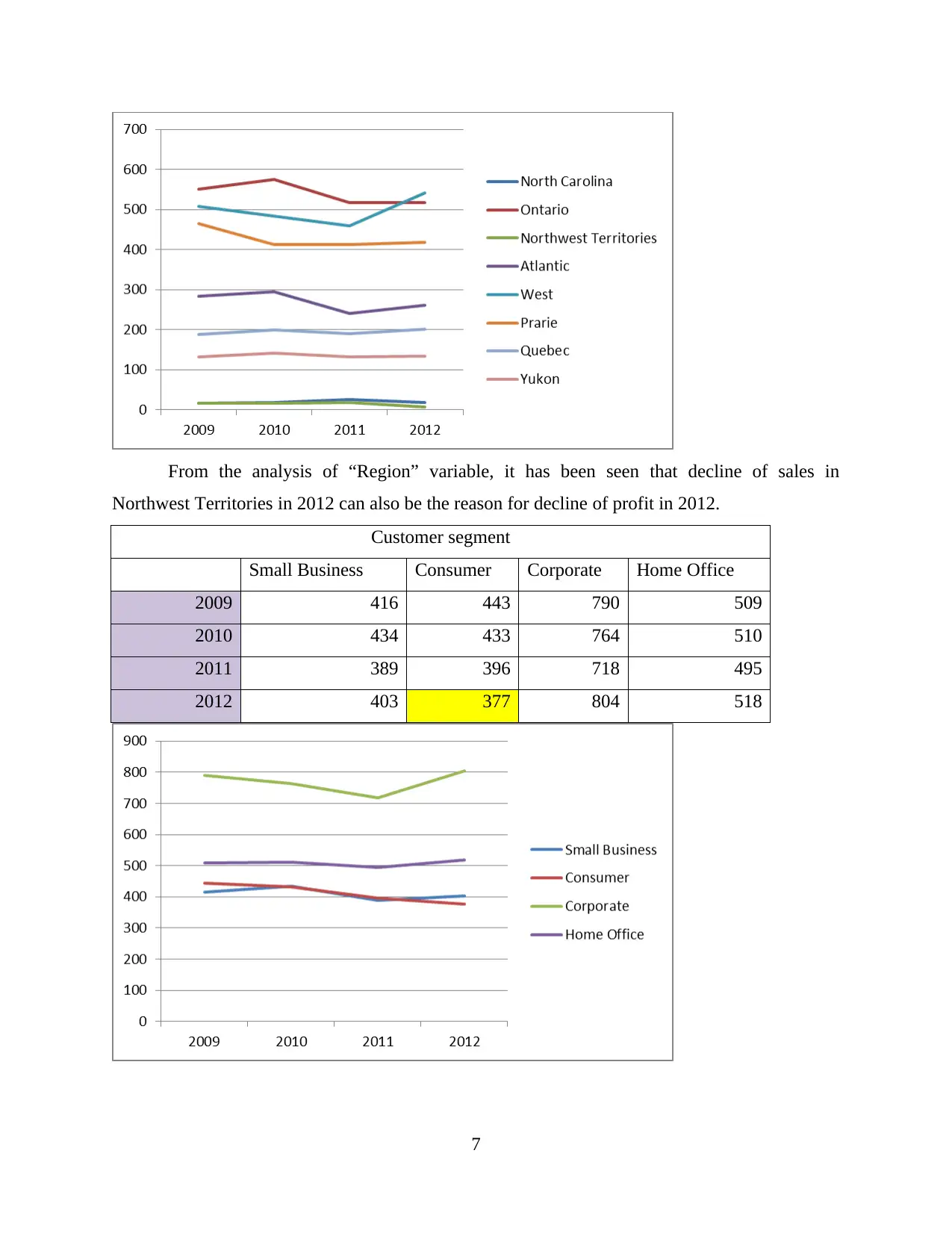
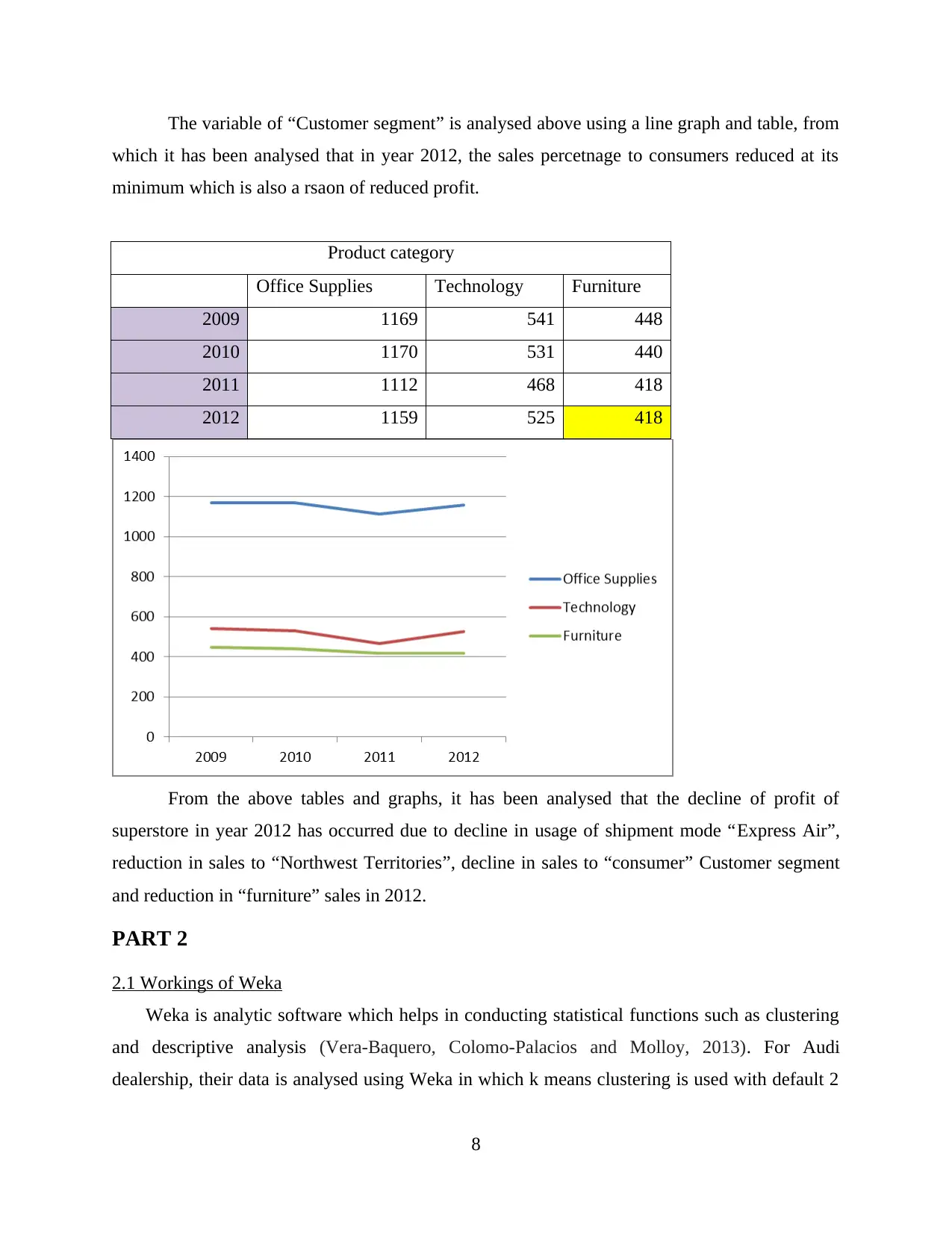
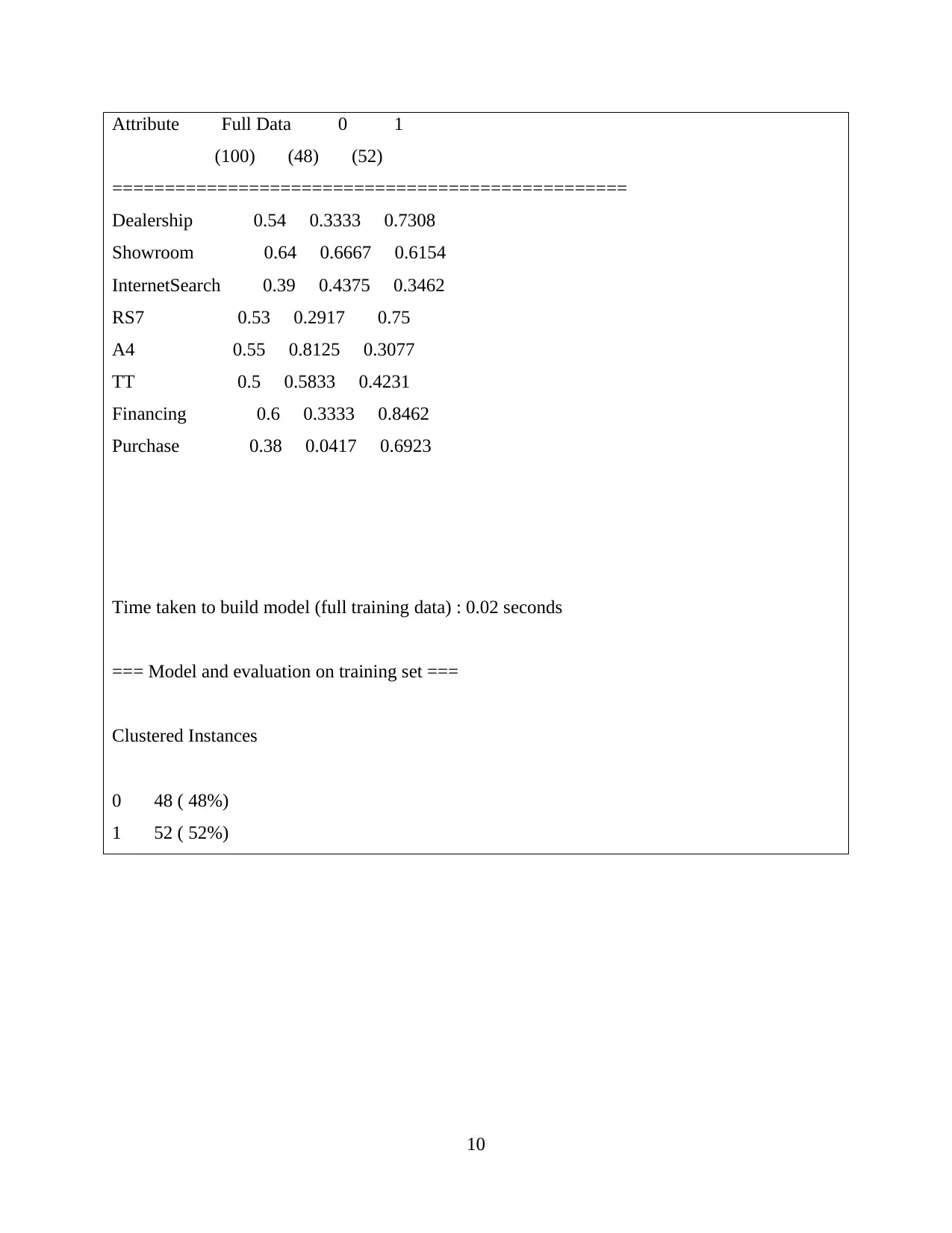
This report delves into the interconnected concepts of data handling, business intelligence, and data mining, crucial for modern organizations in collecting, storing, and analyzing data to derive actionable insights. It examines current trends in data warehousing, including self-service data access and the adoption of Big Data analytics. The report evaluates the use of Microsoft Excel for data pre-processing, analysis, and visualization, specifically focusing on a case study of a Superstore experiencing declining sales and profits. The analysis includes identifying missing values, formatting numerical data, and using pivot tables to extract relevant variables. Furthermore, the report explores the workings of WEKA, a data mining software, using a case study of an Audi dealership and employing k-means clustering to analyze customer behavior. It also explains common data mining methods such as tracking patterns and classification, providing real-world examples to illustrate their applications. Finally, it discusses the advantages and disadvantages of the WEKA tool.





1 out of 17
Related Documents






Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Copyright © 2020–2026 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.