BA Business Management: Data Handling and Business Intelligence Report
VerifiedAdded on 2023/01/11
|19
|3196
|51
Report
AI Summary
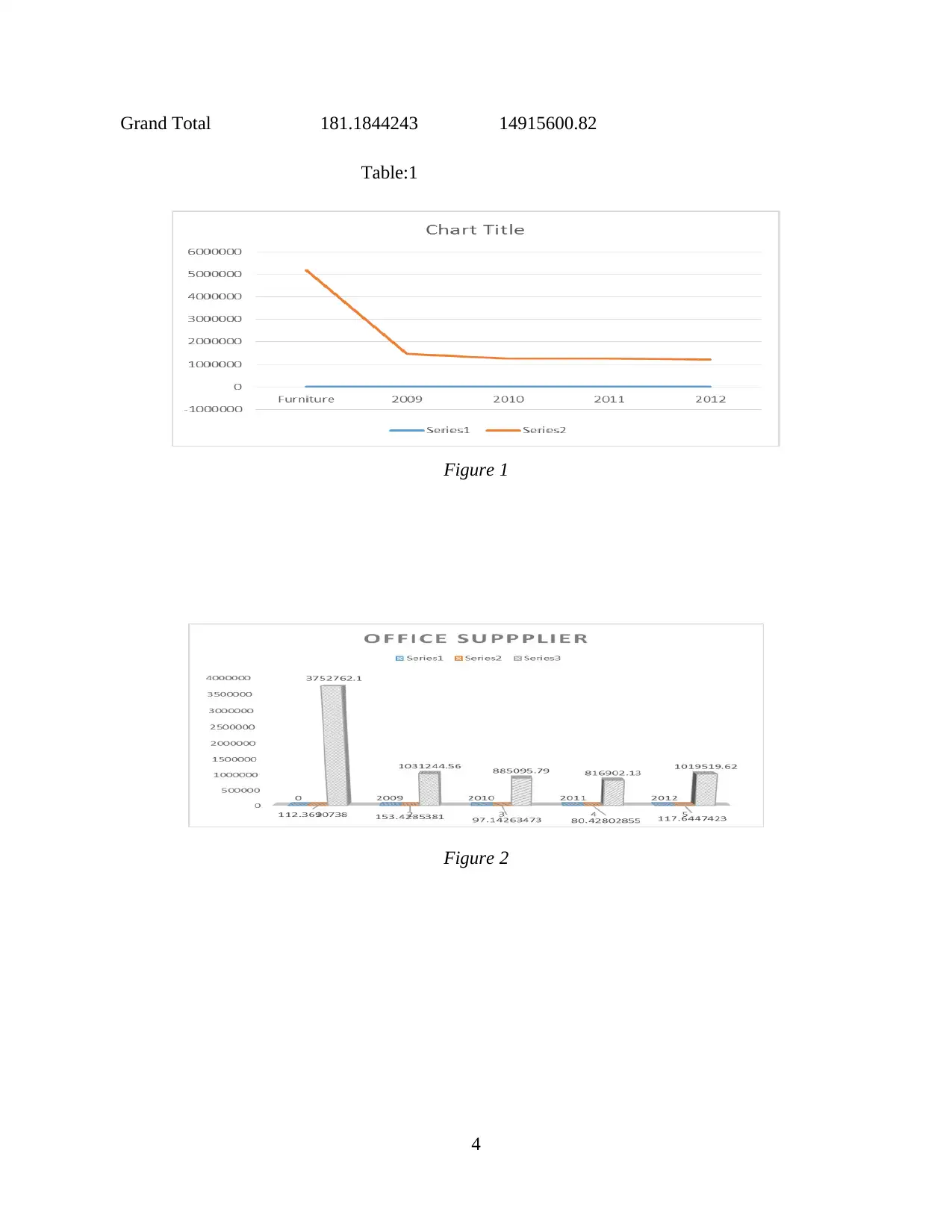
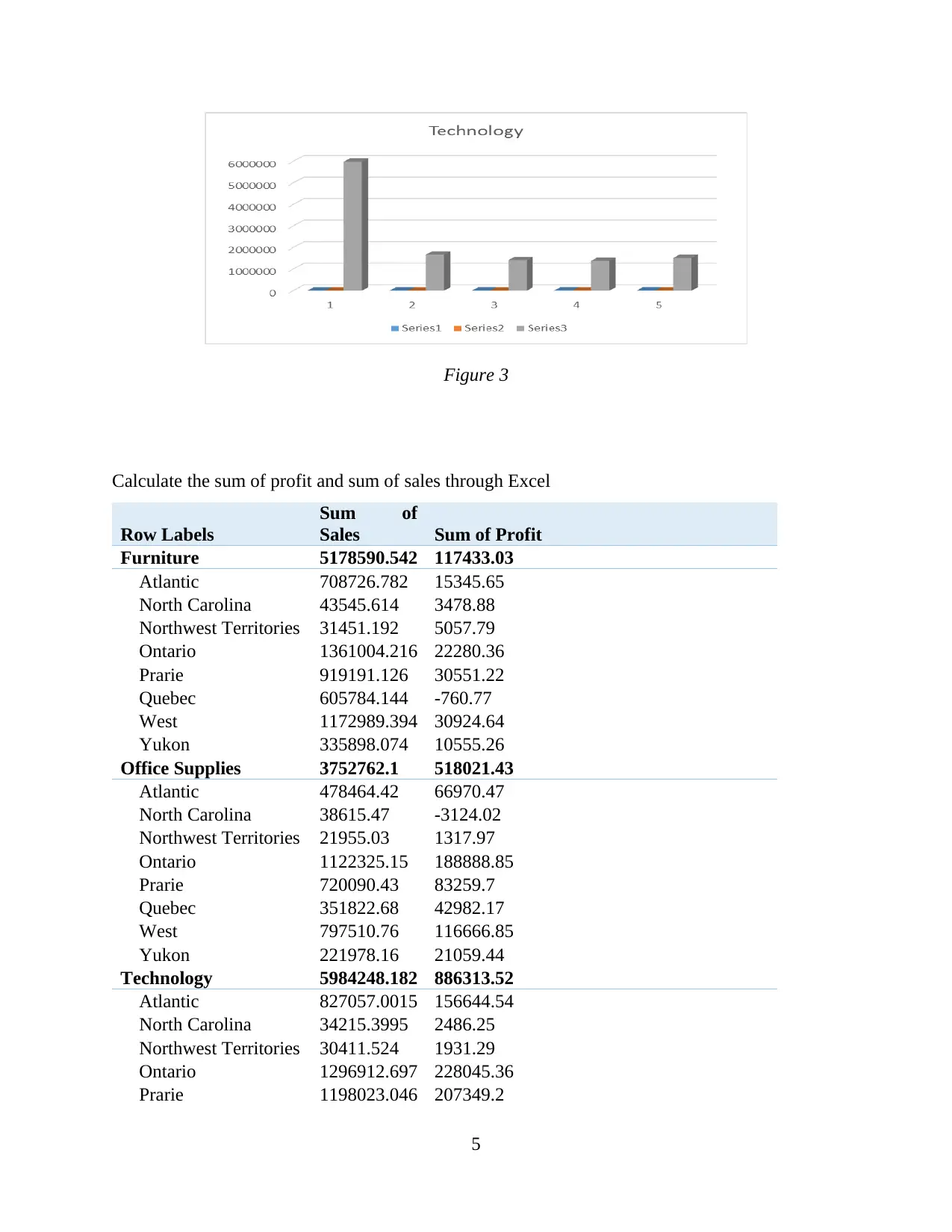
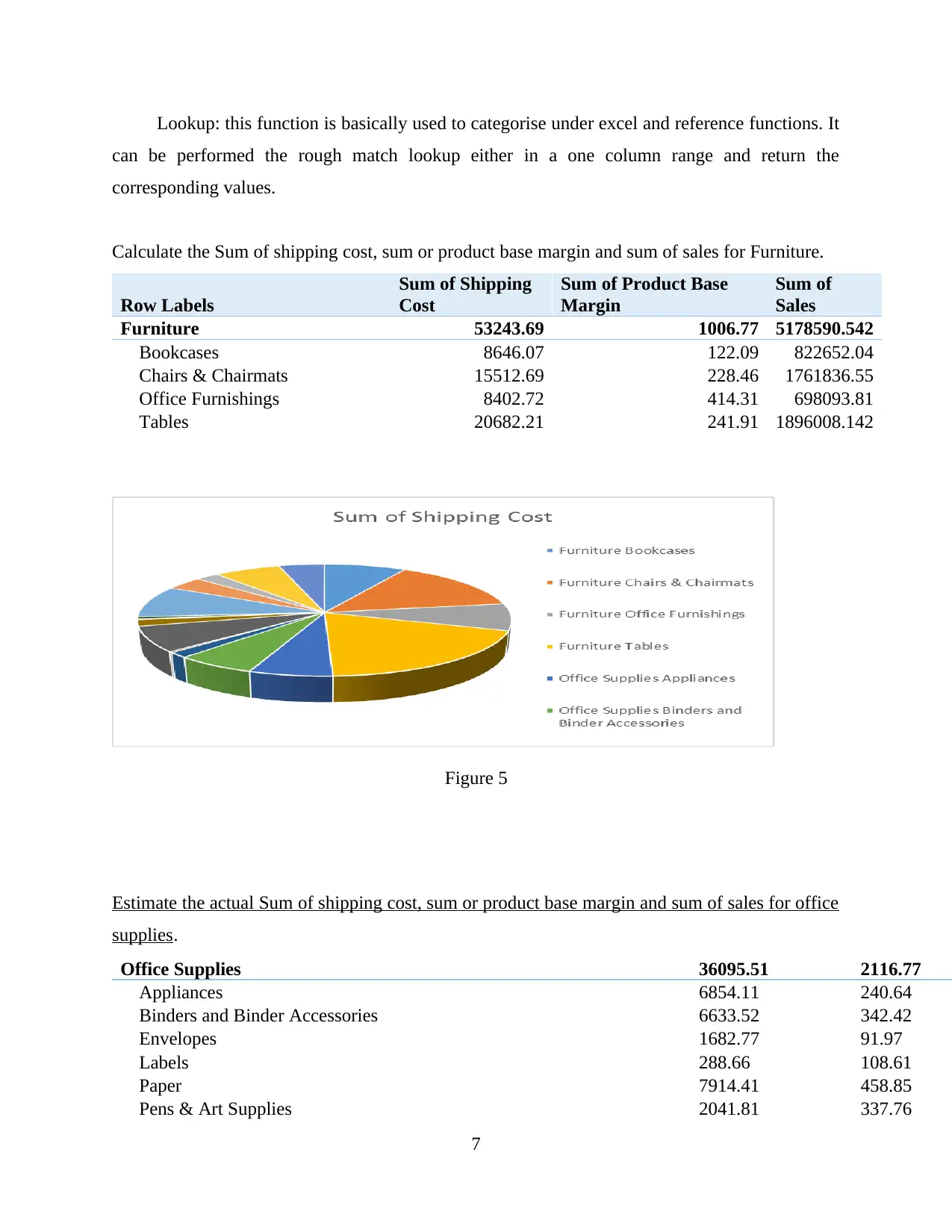
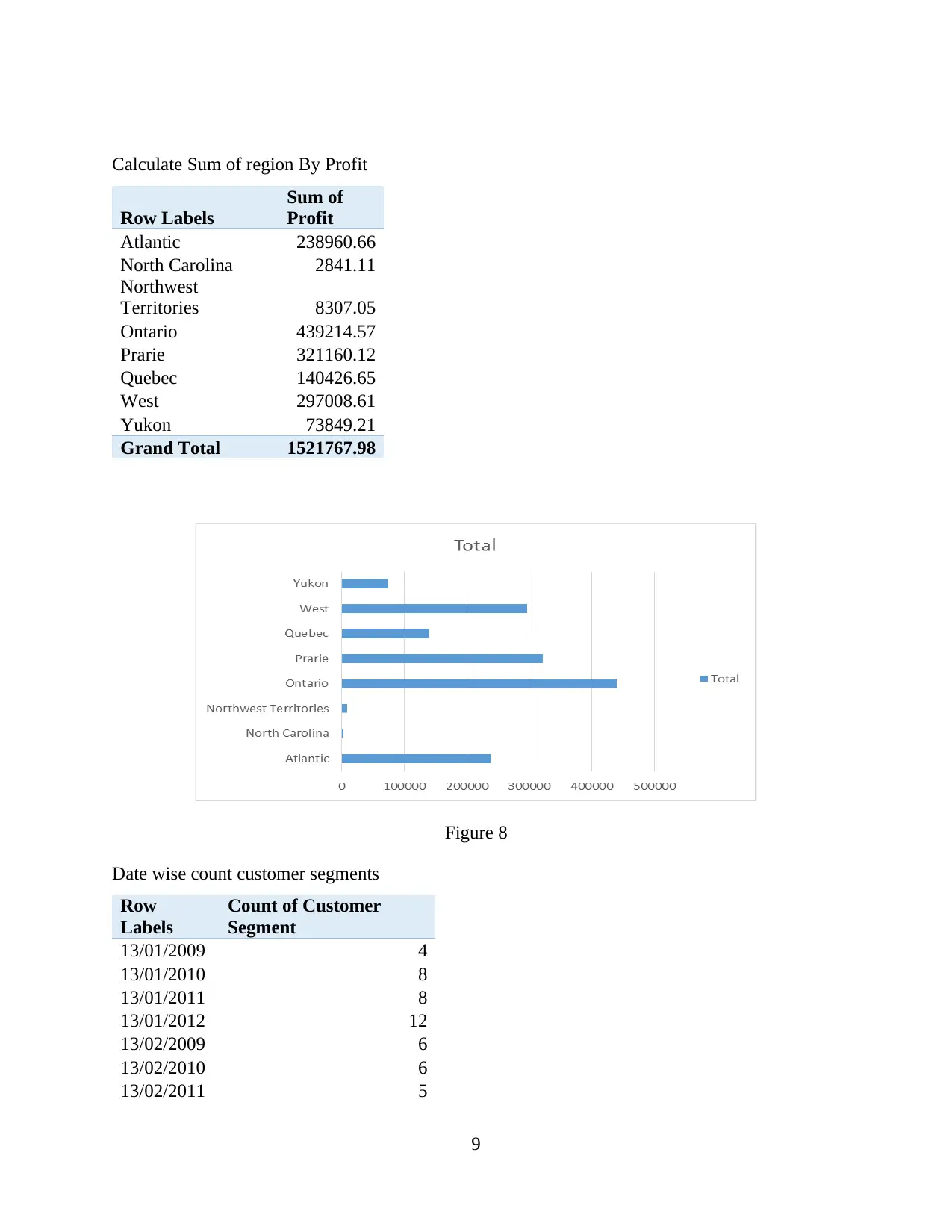
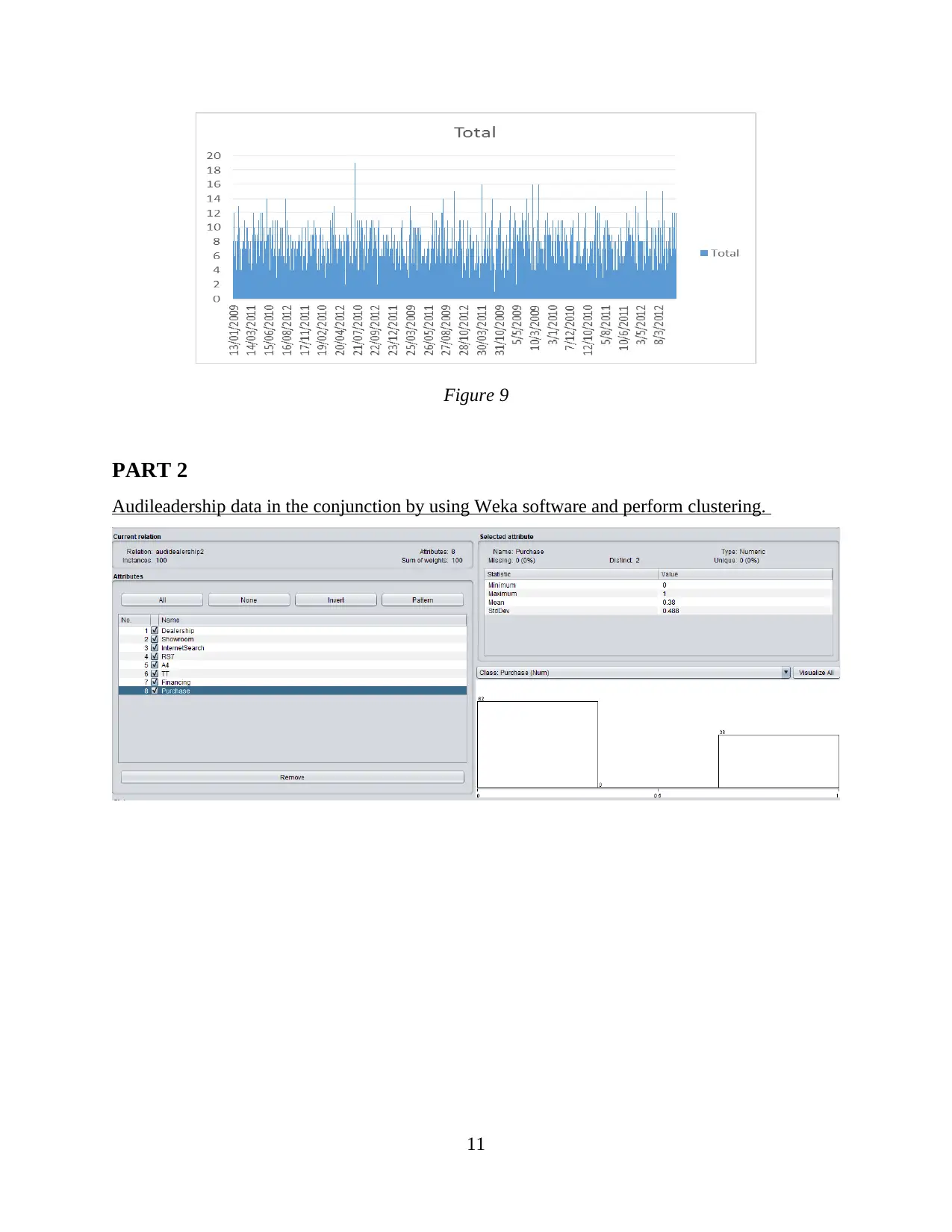
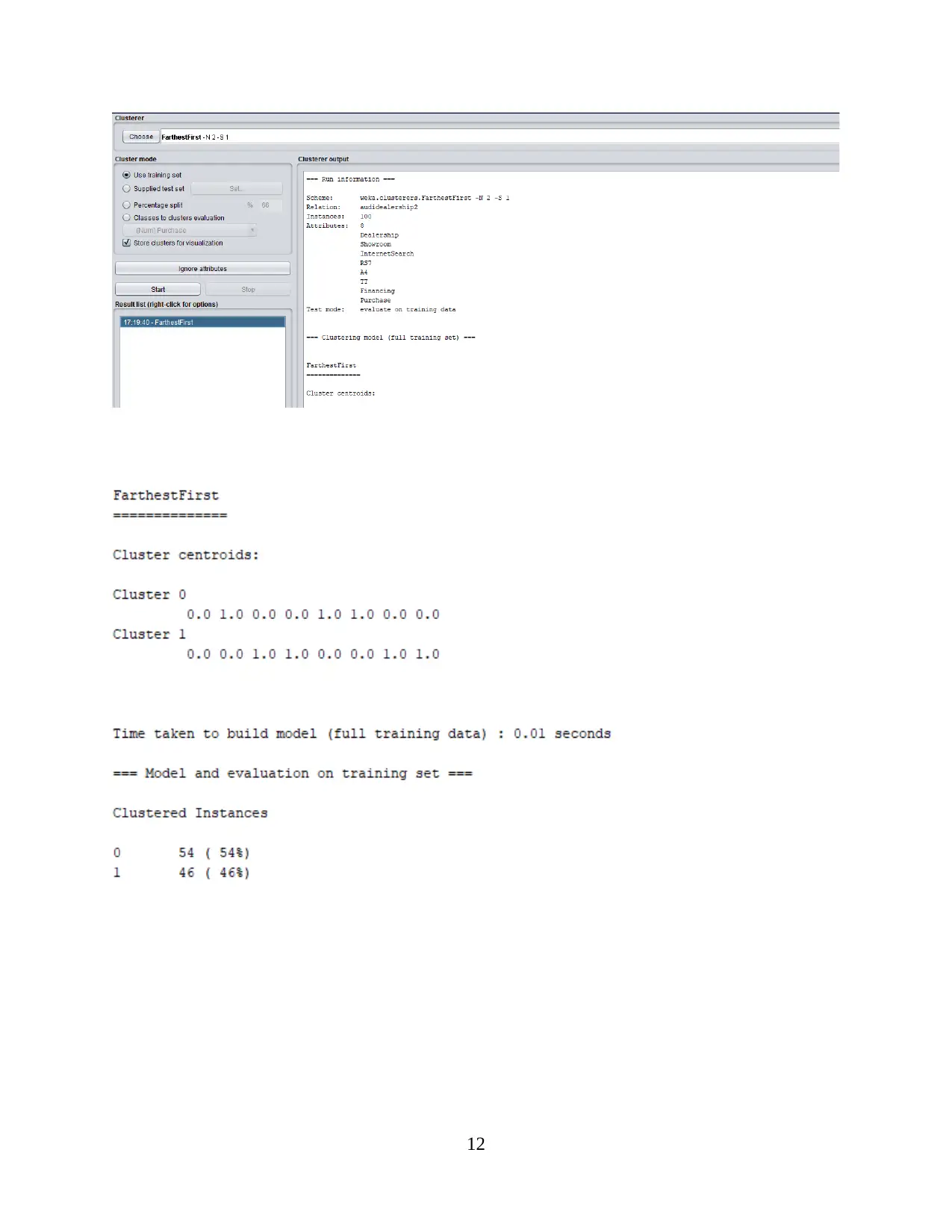
This report provides a comprehensive analysis of data handling and business intelligence. Part 1 focuses on identifying sales and profit trends over the years, with an evaluation of Excel for data preprocessing, demonstrating the use of Excel functions such as pivot tables, lookup, graphs, and charts. Part 2 delves into the application of Weka software for clustering audileadership data and explores various data mining methods applicable within a business context. The report also provides a comparative analysis of Weka and Excel, outlining their respective advantages and disadvantages. The report concludes with a discussion of the key findings and insights derived from the analysis, along with references to the sources used.





1 out of 19


Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Copyright © 2020–2026 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.