MN405 Data and Information Management Assignment 1 Solution - T1 2018
VerifiedAdded on 2021/05/31
|10
|1298
|142
Homework Assignment
AI Summary
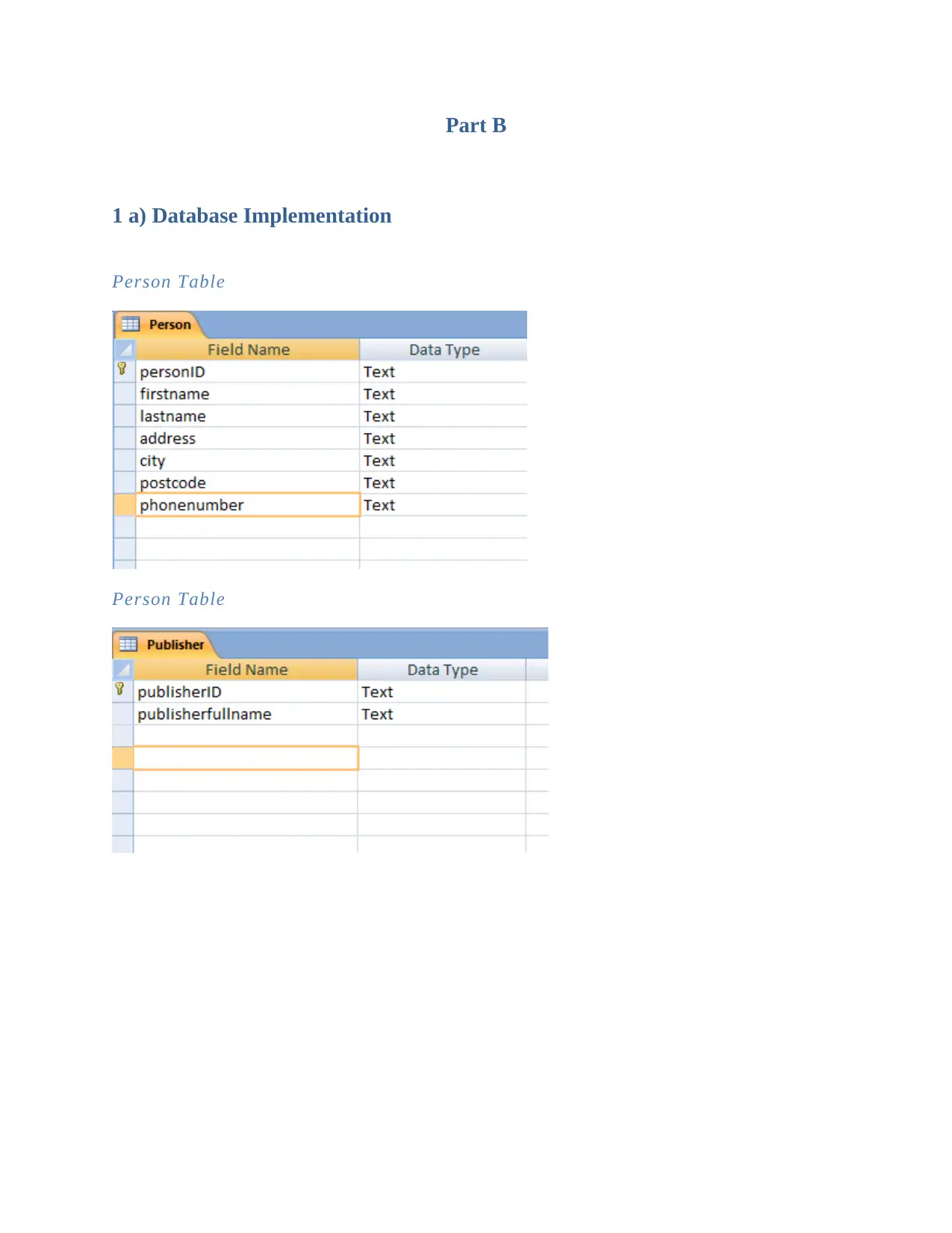
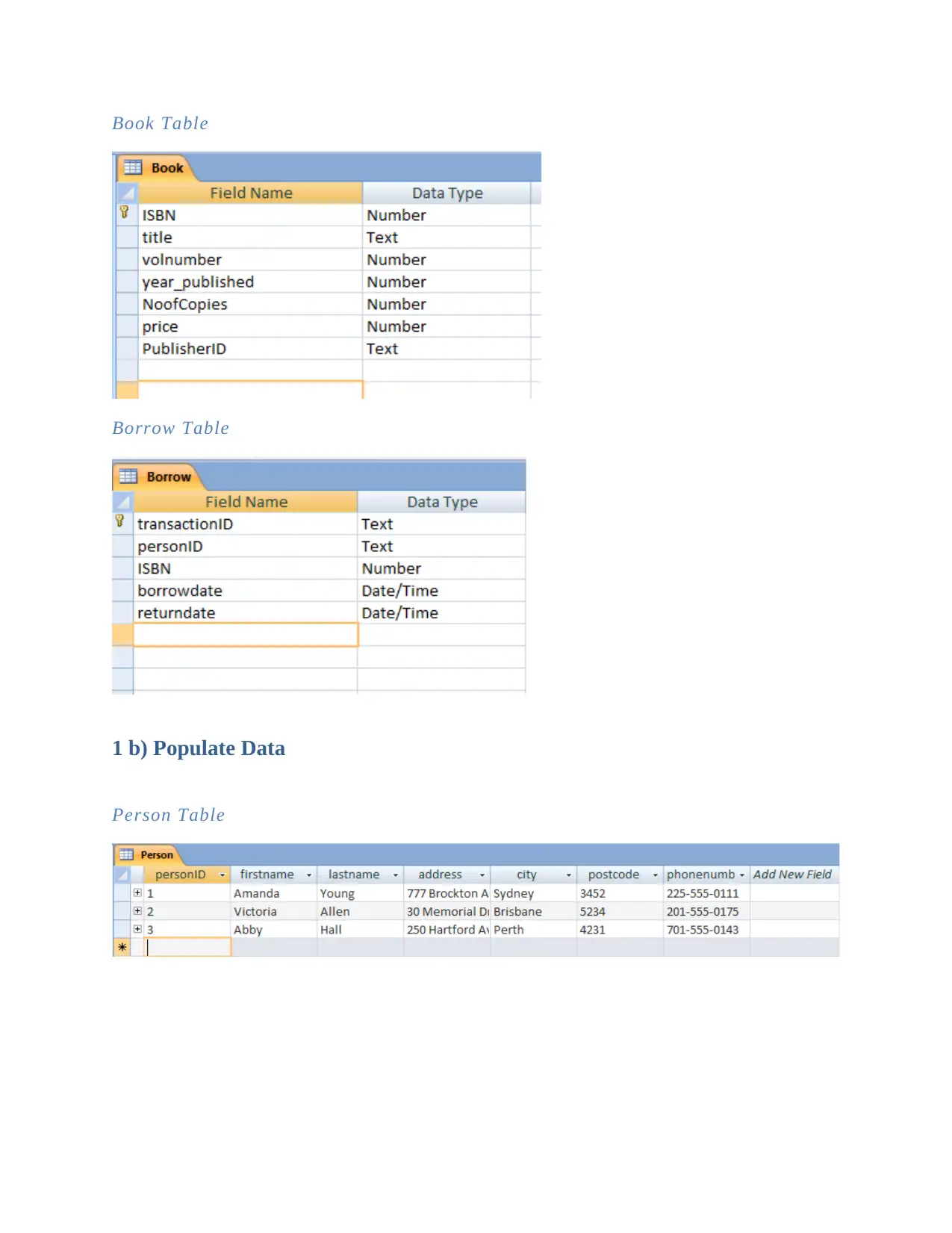
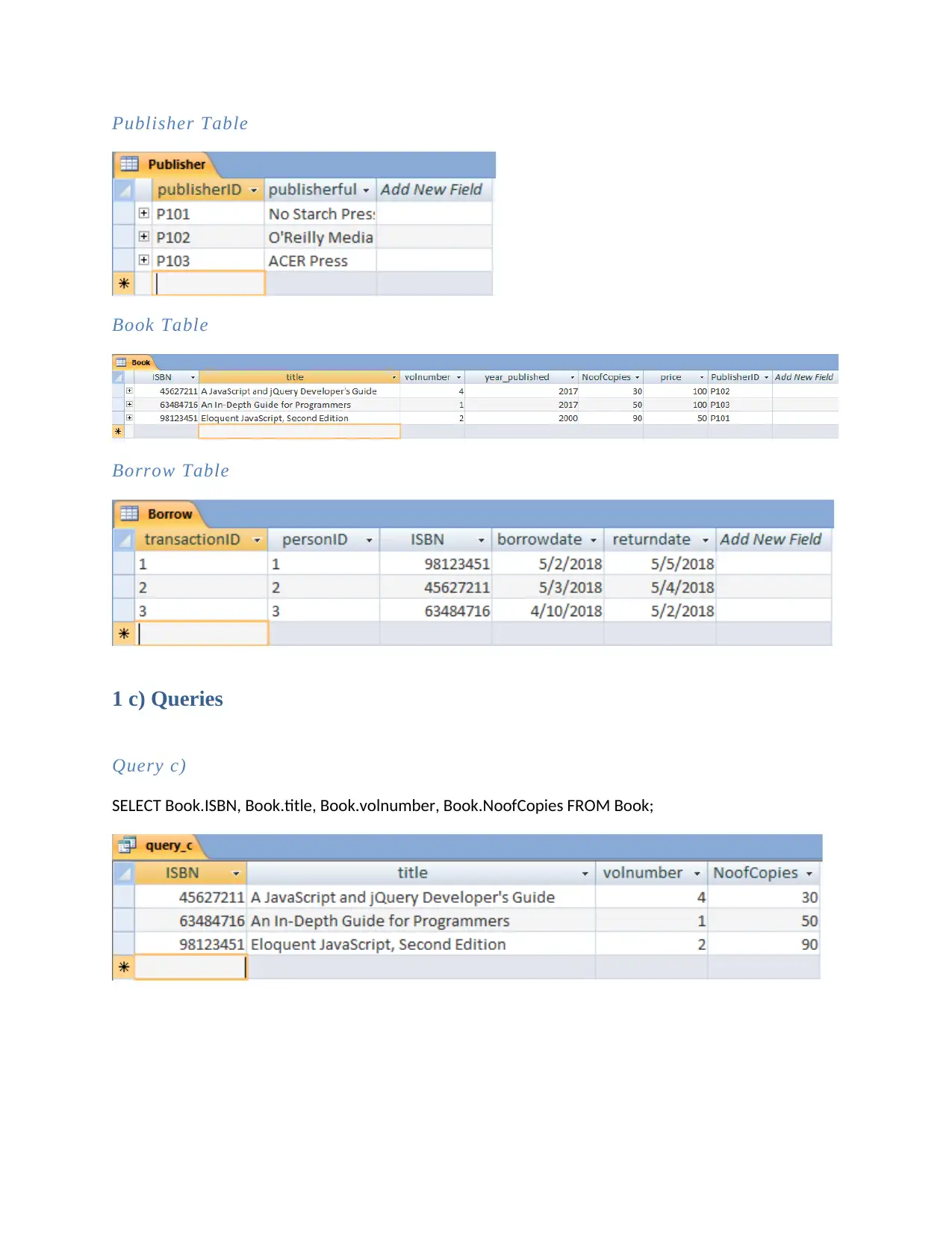
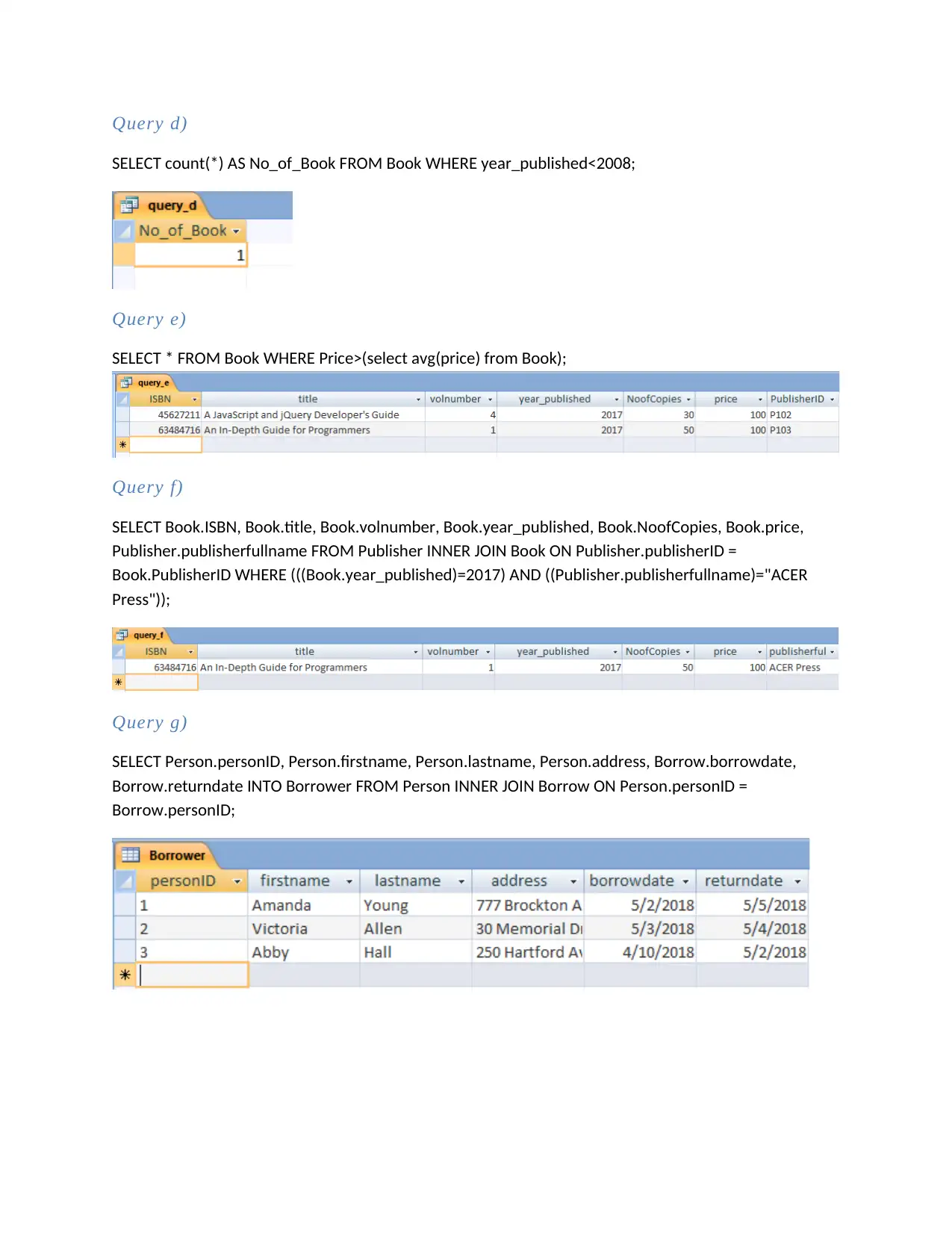
This document presents a comprehensive solution to the MN405 Data and Information Management Assignment 1. It begins with database implementation, including the creation of tables and population of data, followed by SQL queries to retrieve and manipulate data. The solution then delves into relational database schema, identifying composite attributes and relationship cardinalities. Furthermore, the assignment explores big data concepts, providing an introduction to Hadoop and MapReduce, explaining their capabilities, limitations, and suitability for processing large datasets in a distributed environment. The document references several sources to support the presented information.






1 out of 10
Related Documents




Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Copyright © 2020–2026 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.