Business Intelligence Report: Excel, Weka, and Data Mining Analysis
VerifiedAdded on 2023/01/11
|17
|3795
|21
Report
AI Summary
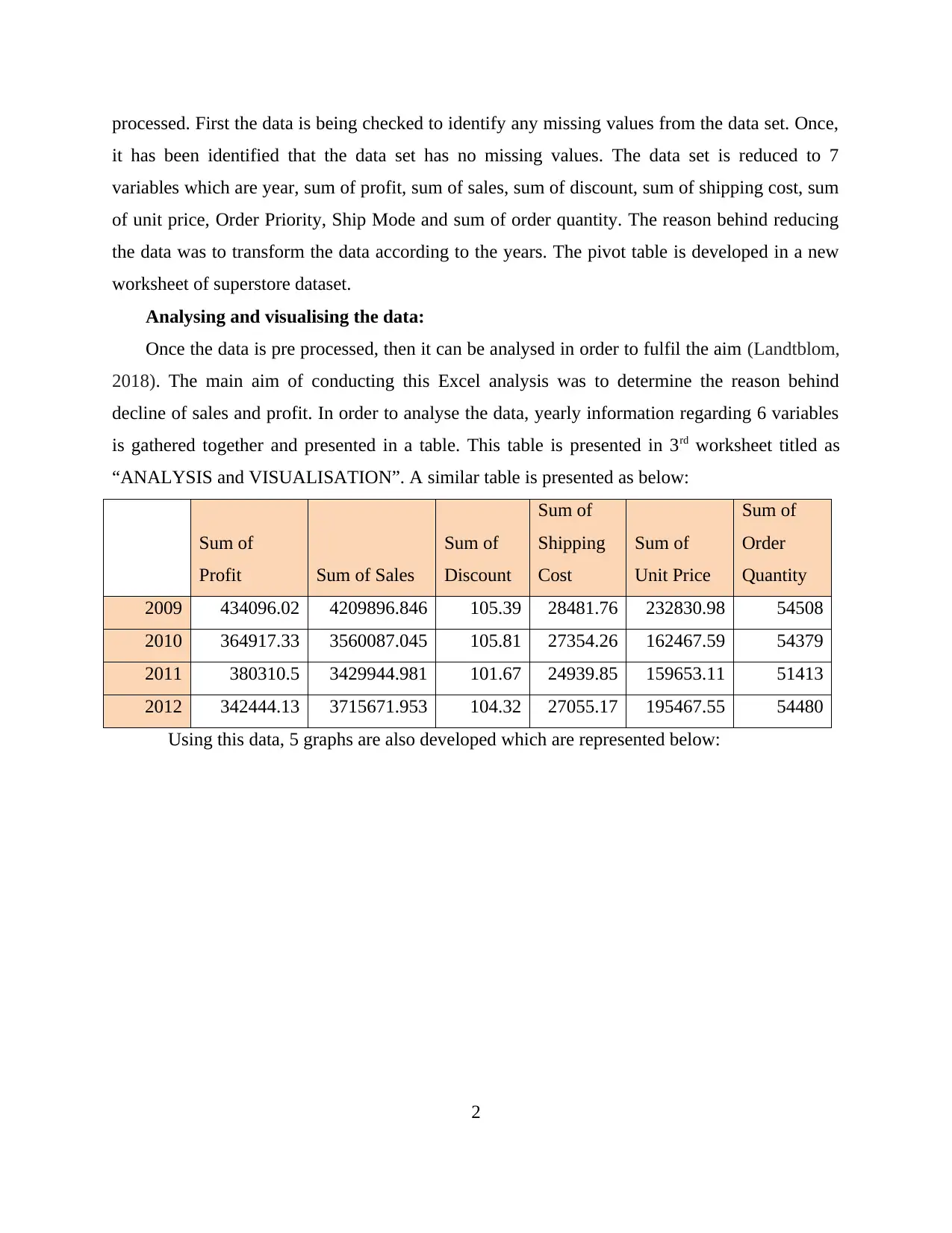
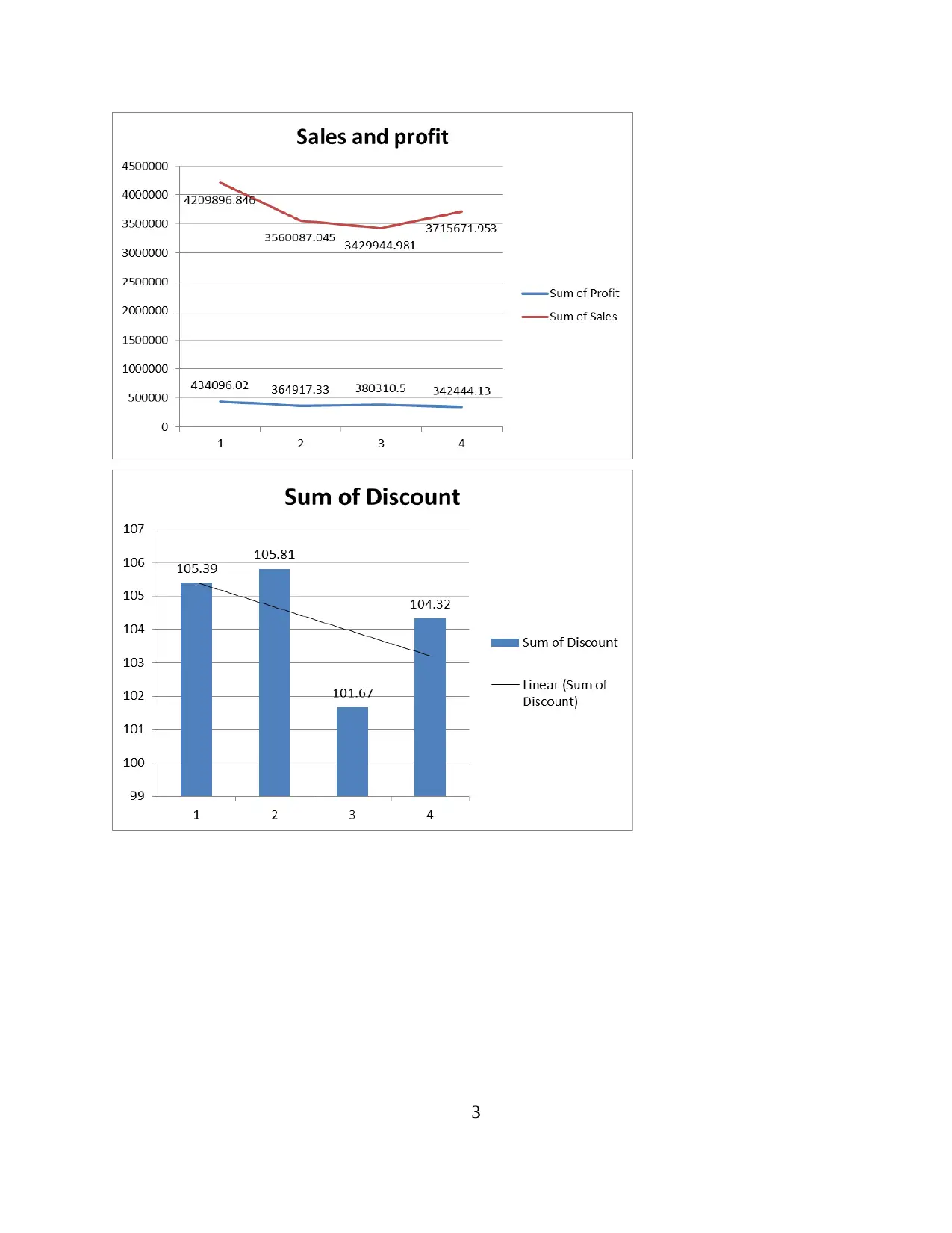
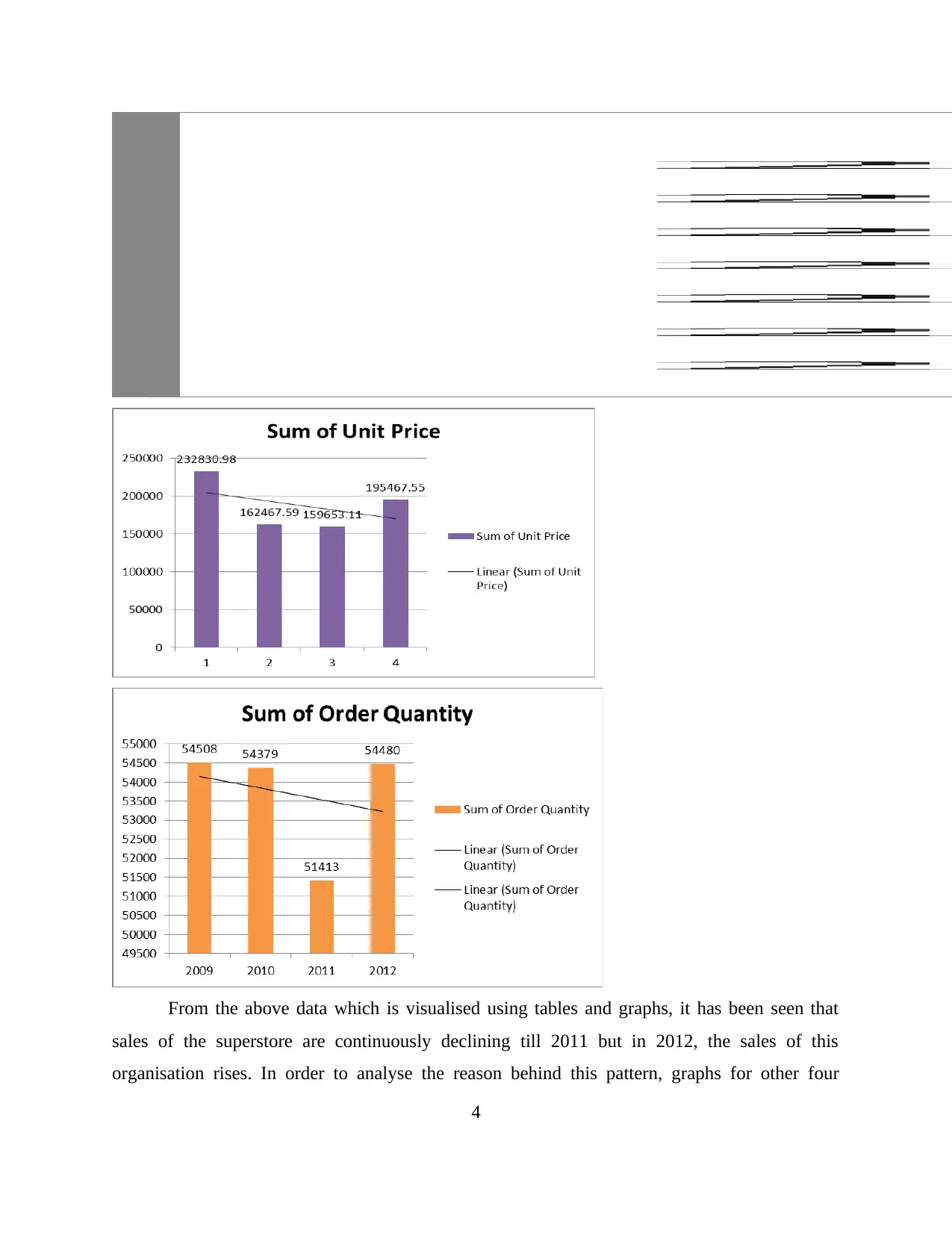
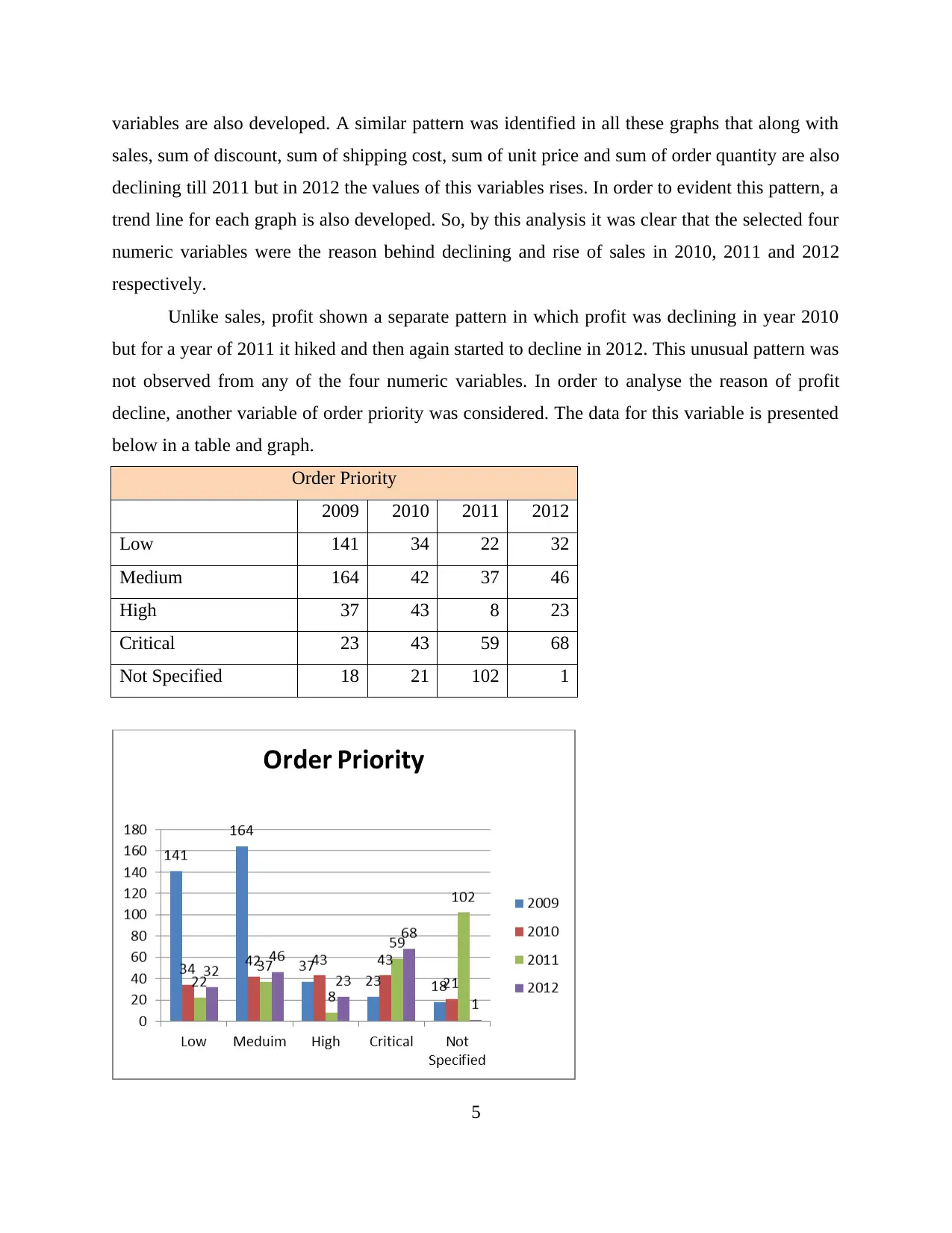
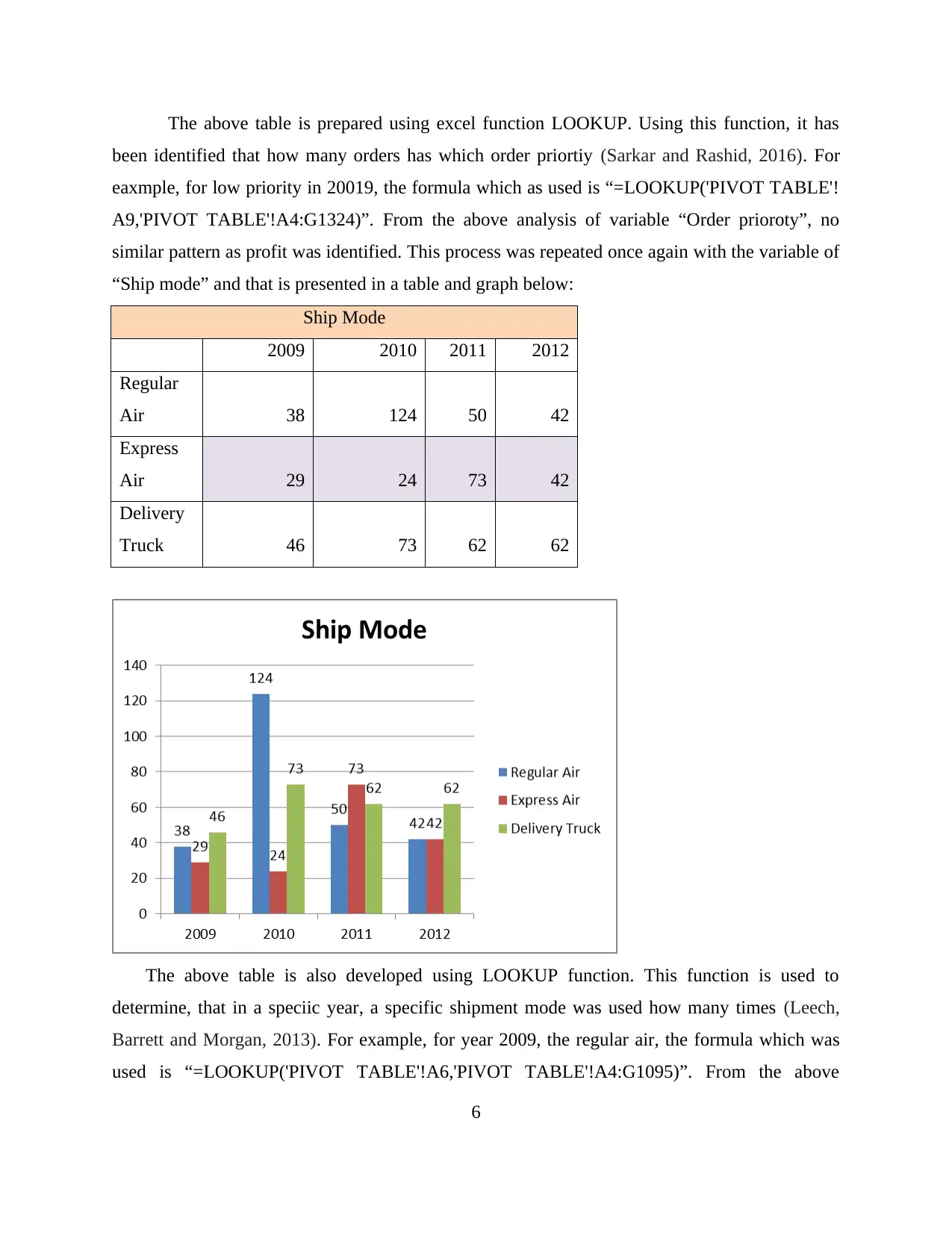
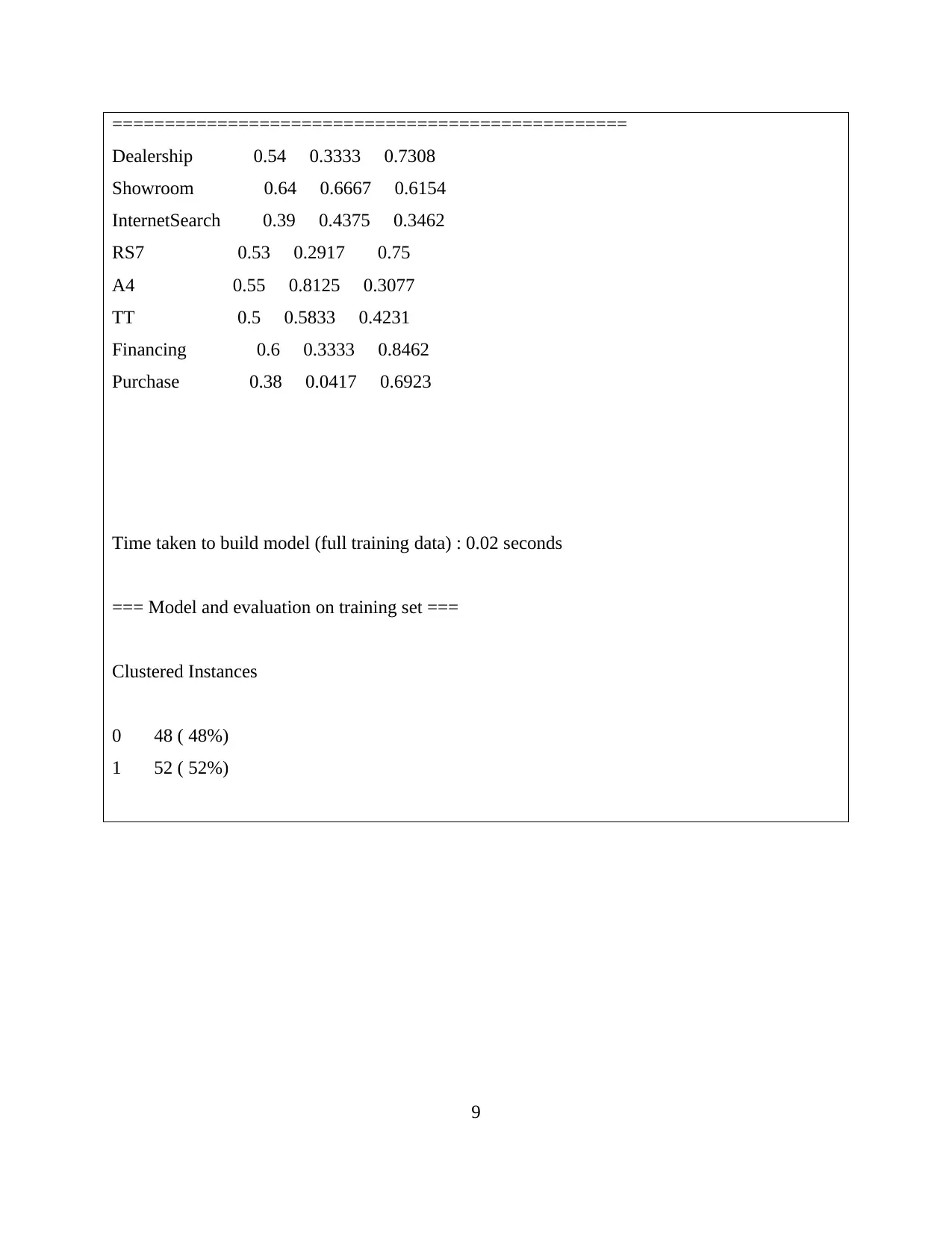
This report explores data handling and business intelligence, focusing on the analysis of sales and profit decline using Microsoft Excel and Weka. The first part utilizes Excel to preprocess, analyze, and visualize Superstore data, identifying factors contributing to sales and profit trends. The analysis reveals declining sales until 2011, with a subsequent rise in 2012, attributed to changes in discounts, shipping costs, unit prices, and order quantities. Profit decline is linked to the reduced use of Express Air shipment mode. The second part employs Weka for clustering the "audidealership" dataset using the k-means method, providing insights into customer behavior. The report also discusses common data mining methods like tracking patterns and classification that can be used in business, along with the advantages and disadvantages of Weka over Excel, offering a comprehensive overview of data analysis techniques.






1 out of 17
Related Documents






Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Copyright © 2020–2026 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.