Big Data Technologies ITEC874: Data Lake Architecture Assignment
VerifiedAdded on 2022/10/01
|10
|2134
|172
Homework Assignment
AI Summary
This document presents a comprehensive assignment solution on Data Lake Architecture, covering various crucial components and technologies. The assignment begins with an in-depth exploration of Data Lake components, including data ingestion methods (structured and unstructured data, Hortonworks dataflow), data organization techniques (MongoDB, MySQL), data security and governance issues (trust, privacy, and security), indexing and search strategies (Federated Search, Elasticsearch), analytics platforms (SAS Text Analytics, Amazon ML, Microsoft ML, Apache Mahout), and data visualization tools (SAS Visual Analytics). Part 2 of the assignment provides a proposed Data Lake architecture diagram, illustrating the flow of data from various sources to the enterprise data lake and its utilization for big data analytics, search, and business interfaces. The architecture integrates Amazon Cloudwatch logs, Amazon Elasticsearch service, and Amazon DB. The assignment brief from Macquarie University, Department of Computing, ITEC874, is also provided.

Running head: DATA LAKE ARCHITECTURE
DATA LAKE ARCHITECTURE
Name of student
Name of university
Author’s note:
DATA LAKE ARCHITECTURE
Name of student
Name of university
Author’s note:
Paraphrase This Document
Need a fresh take? Get an instant paraphrase of this document with our AI Paraphraser

1
DATA LAKE ARCHITECTURE
Table of Contents
Part 1: Data lake components.........................................................................................2
Data ingestion component..........................................................................................2
Data organisation component.....................................................................................3
Data security and governance component..................................................................3
Indexing and search component.................................................................................4
Analytics component..................................................................................................4
Visualisation component............................................................................................5
Part 2. Data Lake Architecture.......................................................................................6
References......................................................................................................................7
DATA LAKE ARCHITECTURE
Table of Contents
Part 1: Data lake components.........................................................................................2
Data ingestion component..........................................................................................2
Data organisation component.....................................................................................3
Data security and governance component..................................................................3
Indexing and search component.................................................................................4
Analytics component..................................................................................................4
Visualisation component............................................................................................5
Part 2. Data Lake Architecture.......................................................................................6
References......................................................................................................................7

2
DATA LAKE ARCHITECTURE
Part 1: Data lake components
Data ingestion component
Data types: There are two varieties of data that are accessible in the present
technological world, namely unstructured and the structured data. The structured data could
be described as the data that has been organised into the formatted depository, commonly the
database, for allowing the elements to be significantly addressable for efficient processing as
well as analysis (Henaff, Bruna and LeCun 2015). Unstructured data could be described as
the information who does not have any pre-determined data model or has not been structured
in the pre-determined manner. The data could be effectively streamed in the real time or it
could ingested in batches. Data ingestion could be described as procedure of the introducing
after gathering data for any immediate use or storing in database. When the data has been
introduced in real time, the importing of data could be done exactly as it has been transmitted
by source. When the data has been ingested in batches, the importing of data items could be
done in significantly distinct chunks at the periodic time intervals (Yao and Van Durme
2014).
Hortonworks dataflow: The Hortonworks dataflow could be referred as scalable,
analytics platform working with real-time streaming which intakes, analyses as well as
curates the data for the crucial insights as well as crucial intelligence that is gained
immediately. The dataflow mainly addresses the crucial challenges that are faced by the
organisation with the data stream processing in the real time of the data at significantly high
scale and high volume, the data ingestion and the provenance from the IoT devices, the
streaming sources and the edge applications (Gates and Dai 2016). It drastically reduces the
development time of the data integration.
DATA LAKE ARCHITECTURE
Part 1: Data lake components
Data ingestion component
Data types: There are two varieties of data that are accessible in the present
technological world, namely unstructured and the structured data. The structured data could
be described as the data that has been organised into the formatted depository, commonly the
database, for allowing the elements to be significantly addressable for efficient processing as
well as analysis (Henaff, Bruna and LeCun 2015). Unstructured data could be described as
the information who does not have any pre-determined data model or has not been structured
in the pre-determined manner. The data could be effectively streamed in the real time or it
could ingested in batches. Data ingestion could be described as procedure of the introducing
after gathering data for any immediate use or storing in database. When the data has been
introduced in real time, the importing of data could be done exactly as it has been transmitted
by source. When the data has been ingested in batches, the importing of data items could be
done in significantly distinct chunks at the periodic time intervals (Yao and Van Durme
2014).
Hortonworks dataflow: The Hortonworks dataflow could be referred as scalable,
analytics platform working with real-time streaming which intakes, analyses as well as
curates the data for the crucial insights as well as crucial intelligence that is gained
immediately. The dataflow mainly addresses the crucial challenges that are faced by the
organisation with the data stream processing in the real time of the data at significantly high
scale and high volume, the data ingestion and the provenance from the IoT devices, the
streaming sources and the edge applications (Gates and Dai 2016). It drastically reduces the
development time of the data integration.
⊘ This is a preview!⊘
Do you want full access?
Subscribe today to unlock all pages.
Trusted by 1+ million students worldwide

3
DATA LAKE ARCHITECTURE
Data organisation component
MongoDB in NoSQL document-oriented DBs and MySQL in Relational DBs:
MySQL could be described as the open source relational database management system
(Győrödi et al. 2015). It has been based on structure query language that has been utilised for
the addition, removal as well as altering information within the database. The website, which
used the MySQL might include the web pages that accesses the information form the
database. MySQL could be effectively used for the variety of the application but could be
commonly found on the web servers.
MongoDB could be described as the open-source database, which utilises the
document oriented data model as well as the query language that has been non-structured. As
this is a NoSQL tool, it do no utilise the common columns and the rows that associates with
relational database management. It is the architecture, which has been built on the documents
and the collections (Lawrence 2014). It permits the documents in having the various
structures and the fields. This particular database utilises the document storage format
referred as the BSON that is the binary style of the JSON documents.
Data security and governance component
Trust, privacy, and security, issues in Big Data: The trust in the relation to technology
of big data is trust as the result of belief in honesty of the stakeholders in process of the
collection, processing and the analysis of the big data (Terzi, Terzi and Sagiroglu 2015).
There are several big data security issues that are presently residing in the organisations such
as the false data production, the unverified mappers, the cryptographic protection issues, the
mining classified information, and the granular access controls. In this regard, the veracity is
in the principle the moral requirement according to the users of the big data should
significantly respect any individual citizen as the data provider with facilitating their
informed consent.
DATA LAKE ARCHITECTURE
Data organisation component
MongoDB in NoSQL document-oriented DBs and MySQL in Relational DBs:
MySQL could be described as the open source relational database management system
(Győrödi et al. 2015). It has been based on structure query language that has been utilised for
the addition, removal as well as altering information within the database. The website, which
used the MySQL might include the web pages that accesses the information form the
database. MySQL could be effectively used for the variety of the application but could be
commonly found on the web servers.
MongoDB could be described as the open-source database, which utilises the
document oriented data model as well as the query language that has been non-structured. As
this is a NoSQL tool, it do no utilise the common columns and the rows that associates with
relational database management. It is the architecture, which has been built on the documents
and the collections (Lawrence 2014). It permits the documents in having the various
structures and the fields. This particular database utilises the document storage format
referred as the BSON that is the binary style of the JSON documents.
Data security and governance component
Trust, privacy, and security, issues in Big Data: The trust in the relation to technology
of big data is trust as the result of belief in honesty of the stakeholders in process of the
collection, processing and the analysis of the big data (Terzi, Terzi and Sagiroglu 2015).
There are several big data security issues that are presently residing in the organisations such
as the false data production, the unverified mappers, the cryptographic protection issues, the
mining classified information, and the granular access controls. In this regard, the veracity is
in the principle the moral requirement according to the users of the big data should
significantly respect any individual citizen as the data provider with facilitating their
informed consent.
Paraphrase This Document
Need a fresh take? Get an instant paraphrase of this document with our AI Paraphraser

4
DATA LAKE ARCHITECTURE
Indexing and search component
Federated Search: The federated search could be described as the approach to the
information retrieval that efficiently aggregates the query results from the multiple sources of
information (Mohamed and Hassan 2015). The federated search permits any user in
submitting any single query and then receive the results from the multiple system if data
resources have been stored on-premises or with the cloud service provider deprived of having
the requirement of querying each system respectively (Georgas 2014). The federated search
gets transmitted to the multiple data sources that mainly belongs to federation simultaneously
offering the end user with the real time results of the query taken straight from required
source of the information.
Elasticsearch: Elasticsearch could be described as the open-source, significantly
broad-distributable, easily-scalable and enterprise-grade search engine. It is accessible with
the use of the extensive as well as elegant API, the elasticsearch could power significantly
fast searches, which supports the applications of the data discovery. The data could be sent in
form of the JSON documents to the elasticsearch with the utilisation of the API or the
ingestion tools like the Amazon Kinesis Firehose and the Logstash (Gormley and Tong
2015). The original document is stored automatically by the elastisearch and then it adds the
discoverable reference to the document in index of the cluster. The document could be
searched and retrieved with the utilisation of the API of Elasticsearch.
Analytics component
SAS Text-Analytics: The SAS Text Analytics could be described as SAS offering that
has been designed for efficiently extracting the insights from the unstructured data in
significantly large scale (Chakraborty, Pagolu and Garla 2014). It is offered in SAS Viya
architecture, the text analytics efficiently combines power of the Natural Language
Processing, the Linguistic rules and the Machine Learning (Massey et al. 2014).
DATA LAKE ARCHITECTURE
Indexing and search component
Federated Search: The federated search could be described as the approach to the
information retrieval that efficiently aggregates the query results from the multiple sources of
information (Mohamed and Hassan 2015). The federated search permits any user in
submitting any single query and then receive the results from the multiple system if data
resources have been stored on-premises or with the cloud service provider deprived of having
the requirement of querying each system respectively (Georgas 2014). The federated search
gets transmitted to the multiple data sources that mainly belongs to federation simultaneously
offering the end user with the real time results of the query taken straight from required
source of the information.
Elasticsearch: Elasticsearch could be described as the open-source, significantly
broad-distributable, easily-scalable and enterprise-grade search engine. It is accessible with
the use of the extensive as well as elegant API, the elasticsearch could power significantly
fast searches, which supports the applications of the data discovery. The data could be sent in
form of the JSON documents to the elasticsearch with the utilisation of the API or the
ingestion tools like the Amazon Kinesis Firehose and the Logstash (Gormley and Tong
2015). The original document is stored automatically by the elastisearch and then it adds the
discoverable reference to the document in index of the cluster. The document could be
searched and retrieved with the utilisation of the API of Elasticsearch.
Analytics component
SAS Text-Analytics: The SAS Text Analytics could be described as SAS offering that
has been designed for efficiently extracting the insights from the unstructured data in
significantly large scale (Chakraborty, Pagolu and Garla 2014). It is offered in SAS Viya
architecture, the text analytics efficiently combines power of the Natural Language
Processing, the Linguistic rules and the Machine Learning (Massey et al. 2014).

5
DATA LAKE ARCHITECTURE
Amazon ML Platform: The platform of the Amazon Machine learning is the Amazon
Web services products, which permits the developer in discovering the patterns in the end-
user data using the algorithms, construct the mathematical models on the basis of the patterns,
then create as well as implement the predictive applications (Heilig and Voß 2017).
Microsoft ML platform: The Microsoft Azure Machine Learning could be described
as the collection of the tools and the services that is intended for helping the developers with
training and deploying the models of machine learning (Bihis and Roychowdhury 2015).
Microsoft offers the tools as well as services using the Azure public cloud.
Apache Mahout: The Apache Mahout could be described as the project of Apache
Software Foundation that is mainly implemented on top of the Apache Hadoop. It also
utilises the paradigm of MapReduce (Lyubimov and Palumbo 2016). It has been also utilised
for creating implementations of significantly scalable and the distributed algorithms of
machine learning that are focused in areas of the collaborate filtering, clustering as well as the
classification.
Visualisation component
SAS Visual Analytics: The SAS visual analytics is significantly easy-to-use,
significantly web-based product, which leverages the analytic technologies of SAS which are
significantly high performance. The SAS visual analytics mainly empowers any organisation
with exploring the huge volumes of data significantly quickly in identifying the patterns, the
trends and the opportunities for the further analysis (Munshi and Mohamed 2016). The SAS
visual data builder mainly enables users with summarising the data, then join the data and
then improve predictive power of the data.
DATA LAKE ARCHITECTURE
Amazon ML Platform: The platform of the Amazon Machine learning is the Amazon
Web services products, which permits the developer in discovering the patterns in the end-
user data using the algorithms, construct the mathematical models on the basis of the patterns,
then create as well as implement the predictive applications (Heilig and Voß 2017).
Microsoft ML platform: The Microsoft Azure Machine Learning could be described
as the collection of the tools and the services that is intended for helping the developers with
training and deploying the models of machine learning (Bihis and Roychowdhury 2015).
Microsoft offers the tools as well as services using the Azure public cloud.
Apache Mahout: The Apache Mahout could be described as the project of Apache
Software Foundation that is mainly implemented on top of the Apache Hadoop. It also
utilises the paradigm of MapReduce (Lyubimov and Palumbo 2016). It has been also utilised
for creating implementations of significantly scalable and the distributed algorithms of
machine learning that are focused in areas of the collaborate filtering, clustering as well as the
classification.
Visualisation component
SAS Visual Analytics: The SAS visual analytics is significantly easy-to-use,
significantly web-based product, which leverages the analytic technologies of SAS which are
significantly high performance. The SAS visual analytics mainly empowers any organisation
with exploring the huge volumes of data significantly quickly in identifying the patterns, the
trends and the opportunities for the further analysis (Munshi and Mohamed 2016). The SAS
visual data builder mainly enables users with summarising the data, then join the data and
then improve predictive power of the data.
⊘ This is a preview!⊘
Do you want full access?
Subscribe today to unlock all pages.
Trusted by 1+ million students worldwide
6
DATA LAKE ARCHITECTURE
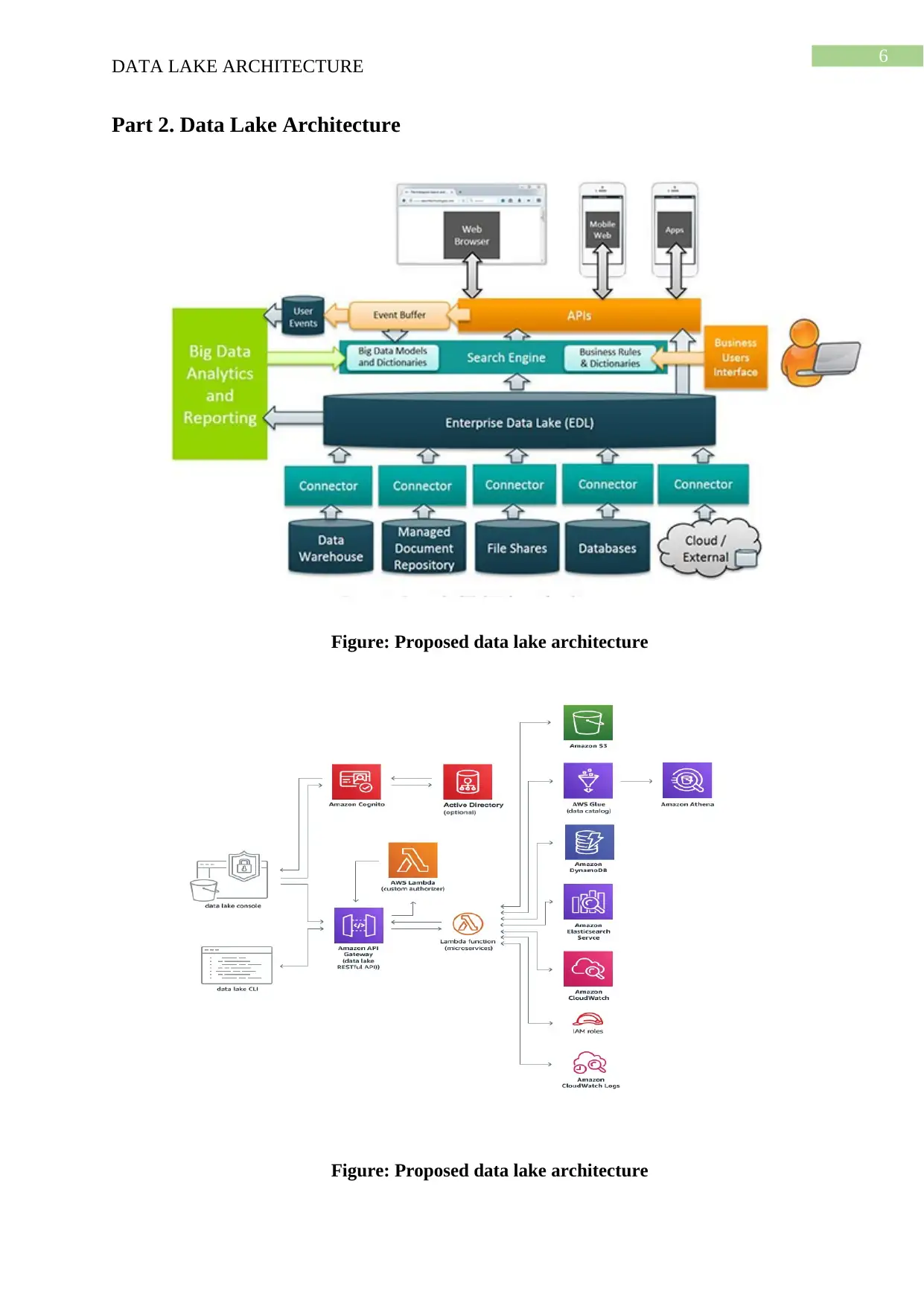
Part 2. Data Lake Architecture
Figure: Proposed data lake architecture
Figure: Proposed data lake architecture
DATA LAKE ARCHITECTURE
Part 2. Data Lake Architecture
Figure: Proposed data lake architecture
Figure: Proposed data lake architecture
Paraphrase This Document
Need a fresh take? Get an instant paraphrase of this document with our AI Paraphraser

7
DATA LAKE ARCHITECTURE
From the proposed data lake architecture, it could be observed that all the data of the
organisation is sent the enterprise data lake using the connectors. The data of the organisation
includes all the data managed in the data warehouse, the managed document repository, the
file shares as well as the databases and the cloud data. These data are transmitted to the EDL
and then it could be used for the Big data analytics. All the data is sent for the analysis and
then then big data dictionaries are created. The EDL is also used in the search engine. The
business interface mainly uses the big data dictionaries and the business rules. Then the data
is sent to the API and then it is transmitted to the event buffer and the user events. All the
data could be viewed in the web browser or the mobile web or the mobile applications. This
proposed architecture could be considered as significantly efficient and effective in operation.
It uses the Amazon Cloudwatch logs, Amazon Elasticsearch service and the Amazon DB.
References
Bihis, M. and Roychowdhury, S., 2015, October. A generalized flow for multi-class and
binary classification tasks: An Azure ML approach. In 2015 IEEE International Conference
on Big Data (Big Data) (pp. 1728-1737). IEEE.
Chakraborty, G., Pagolu, M. and Garla, S., 2014. Text mining and analysis: practical
methods, examples, and case studies using SAS. SAS Institute.
Gates, A. and Dai, D., 2016. Programming pig: Dataflow scripting with hadoop. " O'Reilly
Media, Inc.".
Georgas, H., 2014. Google vs. the library (part II): Student search patterns and behaviors
when using Google and a federated search tool. portal: Libraries and the Academy, 14(4),
pp.503-532.
Gormley, C. and Tong, Z., 2015. Elasticsearch: the definitive guide: a distributed real-time
search and analytics engine. " O'Reilly Media, Inc.".
DATA LAKE ARCHITECTURE
From the proposed data lake architecture, it could be observed that all the data of the
organisation is sent the enterprise data lake using the connectors. The data of the organisation
includes all the data managed in the data warehouse, the managed document repository, the
file shares as well as the databases and the cloud data. These data are transmitted to the EDL
and then it could be used for the Big data analytics. All the data is sent for the analysis and
then then big data dictionaries are created. The EDL is also used in the search engine. The
business interface mainly uses the big data dictionaries and the business rules. Then the data
is sent to the API and then it is transmitted to the event buffer and the user events. All the
data could be viewed in the web browser or the mobile web or the mobile applications. This
proposed architecture could be considered as significantly efficient and effective in operation.
It uses the Amazon Cloudwatch logs, Amazon Elasticsearch service and the Amazon DB.
References
Bihis, M. and Roychowdhury, S., 2015, October. A generalized flow for multi-class and
binary classification tasks: An Azure ML approach. In 2015 IEEE International Conference
on Big Data (Big Data) (pp. 1728-1737). IEEE.
Chakraborty, G., Pagolu, M. and Garla, S., 2014. Text mining and analysis: practical
methods, examples, and case studies using SAS. SAS Institute.
Gates, A. and Dai, D., 2016. Programming pig: Dataflow scripting with hadoop. " O'Reilly
Media, Inc.".
Georgas, H., 2014. Google vs. the library (part II): Student search patterns and behaviors
when using Google and a federated search tool. portal: Libraries and the Academy, 14(4),
pp.503-532.
Gormley, C. and Tong, Z., 2015. Elasticsearch: the definitive guide: a distributed real-time
search and analytics engine. " O'Reilly Media, Inc.".

8
DATA LAKE ARCHITECTURE
Győrödi, C., Győrödi, R., Pecherle, G. and Olah, A., 2015, June. A comparative study:
MongoDB vs. MySQL. In 2015 13th International Conference on Engineering of Modern
Electric Systems (EMES) (pp. 1-6). IEEE.
Heilig, L. and Voß, S., 2017. Managing Cloud-Based Big Data Platforms: A Reference
Architecture and Cost Perspective. In Big Data Management (pp. 29-45). Springer, Cham.
Henaff, M., Bruna, J. and LeCun, Y., 2015. Deep convolutional networks on graph-structured
data. arXiv preprint arXiv:1506.05163.
Lawrence, R., 2014, March. Integration and virtualization of relational SQL and NoSQL
systems including MySQL and MongoDB. In 2014 International Conference on
Computational Science and Computational Intelligence (Vol. 1, pp. 285-290). IEEE.
Lyubimov, D. and Palumbo, A., 2016. Apache Mahout: Beyond MapReduce. CreateSpace
Independent Publishing Platform.
Massey, J.G., Myneni, R., Mattocks, M.A. and Brinsfield, E.C., 2014. Extracting key
concepts from unstructured medical reports using SAS® Text Analytics and SAS® Visual
Analytics. In Proceedings of SAS Global Forum.
Mohamed, K.A. and Hassan, A., 2015. Evaluating federated search tools: usability and
retrievability framework. The Electronic Library, 33(6), pp.1079-1099.
Munshi, A.A. and Mohamed, Y.A., 2016, September. Cloud-based visual analytics for smart
grids big data. In 2016 IEEE Power & Energy Society Innovative Smart Grid Technologies
Conference (ISGT) (pp. 1-5). IEEE.
Terzi, D.S., Terzi, R. and Sagiroglu, S., 2015, December. A survey on security and privacy
issues in big data. In 2015 10th International Conference for Internet Technology and
Secured Transactions (ICITST) (pp. 202-207). IEEE.
DATA LAKE ARCHITECTURE
Győrödi, C., Győrödi, R., Pecherle, G. and Olah, A., 2015, June. A comparative study:
MongoDB vs. MySQL. In 2015 13th International Conference on Engineering of Modern
Electric Systems (EMES) (pp. 1-6). IEEE.
Heilig, L. and Voß, S., 2017. Managing Cloud-Based Big Data Platforms: A Reference
Architecture and Cost Perspective. In Big Data Management (pp. 29-45). Springer, Cham.
Henaff, M., Bruna, J. and LeCun, Y., 2015. Deep convolutional networks on graph-structured
data. arXiv preprint arXiv:1506.05163.
Lawrence, R., 2014, March. Integration and virtualization of relational SQL and NoSQL
systems including MySQL and MongoDB. In 2014 International Conference on
Computational Science and Computational Intelligence (Vol. 1, pp. 285-290). IEEE.
Lyubimov, D. and Palumbo, A., 2016. Apache Mahout: Beyond MapReduce. CreateSpace
Independent Publishing Platform.
Massey, J.G., Myneni, R., Mattocks, M.A. and Brinsfield, E.C., 2014. Extracting key
concepts from unstructured medical reports using SAS® Text Analytics and SAS® Visual
Analytics. In Proceedings of SAS Global Forum.
Mohamed, K.A. and Hassan, A., 2015. Evaluating federated search tools: usability and
retrievability framework. The Electronic Library, 33(6), pp.1079-1099.
Munshi, A.A. and Mohamed, Y.A., 2016, September. Cloud-based visual analytics for smart
grids big data. In 2016 IEEE Power & Energy Society Innovative Smart Grid Technologies
Conference (ISGT) (pp. 1-5). IEEE.
Terzi, D.S., Terzi, R. and Sagiroglu, S., 2015, December. A survey on security and privacy
issues in big data. In 2015 10th International Conference for Internet Technology and
Secured Transactions (ICITST) (pp. 202-207). IEEE.
⊘ This is a preview!⊘
Do you want full access?
Subscribe today to unlock all pages.
Trusted by 1+ million students worldwide

9
DATA LAKE ARCHITECTURE
Yao, X. and Van Durme, B., 2014, June. Information extraction over structured data:
Question answering with freebase. In Proceedings of the 52nd Annual Meeting of the
Association for Computational Linguistics (Volume 1: Long Papers) (pp. 956-966).
DATA LAKE ARCHITECTURE
Yao, X. and Van Durme, B., 2014, June. Information extraction over structured data:
Question answering with freebase. In Proceedings of the 52nd Annual Meeting of the
Association for Computational Linguistics (Volume 1: Long Papers) (pp. 956-966).
1 out of 10
Related Documents


Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Unlock your academic potential
Copyright © 2020–2026 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.