Data Management Architectures, EDA, and Regression Analysis Project
VerifiedAdded on 2020/07/22
|28
|2628
|100
Project
AI Summary
This project addresses data management architectures, including data warehouses, data lakes, and data marts, detailing their use cases and benefits within an organization. It contrasts query-driven and update-driven approaches for integrating heterogeneous directories. The project then delves into exploratory data analysis (EDA) and linear regression analysis. It summarizes variables, identifies outliers, and discusses data preparation techniques, including outlier detection and data splitting into training and test datasets. The analysis includes both univariate and bivariate analysis with scatterplots and correlation coefficients, highlighting the importance of addressing non-normal distributions and outliers before analysis.

Task 1 Data Management Architectures
Task 1.1
A data warehouse
Information warehousing is the process of making use of and constructing an information warehouse.
The data warehouse is built by integrating data through multiple heterogeneous sources that will
support analytical reporting, organized and/or ad hoc queries, plus decision making. Data warehousing
consists of data cleaning, data incorporation, and data consolidations.
Making use of Data Warehouse Information
You can find decision support technologies that will help utilize the data obtainable in a data warehouse.
These types of technologies help executives to make use of the warehouse quickly and effectively. They
can gather data, evaluate it, plus take decisions based on the provided information present in the
stockroom. The information collected in a warehouse can be used in different of the following domains:
o Tuning Production Strategies - The item strategies can be well tuned simply by repositioning the
products and handling the product portfolios by evaluating the sales quarterly or even yearly.
o Customer Analysis: Customer analysis is done simply by analyzing the customer's purchasing
preferences, buying time, spending budget cycles, etc.
o Operations Evaluation - Data warehousing will also help in customer relationship administration,
and making environmental modifications. The info allows us to analyze business procedures
also.
Integrating Heterogeneous Directories
To integrate heterogeneous directories, we have two approaches:
o Query-driven Approach
o Update-driven Approach
Query-Driven Approach
This is the traditional method of integrate heterogeneous databases. This method was used to build
packages and integrators on top of several heterogeneous databases. These types of integrators are also
known as mediators.
Procedure for Query-Driven Approach
o When the query is issued to some client side, the metadata dictionary translates the particular
query into an appropriate type for individual heterogeneous websites involved.
o Now these queries are mapped and sent to the local issue processor.
Task 1.1
A data warehouse
Information warehousing is the process of making use of and constructing an information warehouse.
The data warehouse is built by integrating data through multiple heterogeneous sources that will
support analytical reporting, organized and/or ad hoc queries, plus decision making. Data warehousing
consists of data cleaning, data incorporation, and data consolidations.
Making use of Data Warehouse Information
You can find decision support technologies that will help utilize the data obtainable in a data warehouse.
These types of technologies help executives to make use of the warehouse quickly and effectively. They
can gather data, evaluate it, plus take decisions based on the provided information present in the
stockroom. The information collected in a warehouse can be used in different of the following domains:
o Tuning Production Strategies - The item strategies can be well tuned simply by repositioning the
products and handling the product portfolios by evaluating the sales quarterly or even yearly.
o Customer Analysis: Customer analysis is done simply by analyzing the customer's purchasing
preferences, buying time, spending budget cycles, etc.
o Operations Evaluation - Data warehousing will also help in customer relationship administration,
and making environmental modifications. The info allows us to analyze business procedures
also.
Integrating Heterogeneous Directories
To integrate heterogeneous directories, we have two approaches:
o Query-driven Approach
o Update-driven Approach
Query-Driven Approach
This is the traditional method of integrate heterogeneous databases. This method was used to build
packages and integrators on top of several heterogeneous databases. These types of integrators are also
known as mediators.
Procedure for Query-Driven Approach
o When the query is issued to some client side, the metadata dictionary translates the particular
query into an appropriate type for individual heterogeneous websites involved.
o Now these queries are mapped and sent to the local issue processor.
Paraphrase This Document
Need a fresh take? Get an instant paraphrase of this document with our AI Paraphraser

o The results from heterogeneous sites are integrated into a worldwide answer set.
Update-Driven Approach
It is really an alternative to the traditional approach. All of us data warehouse systems adhere to update-
driven approach rather than the conventional approach discussed earlier. Within update-driven
approach, the information through multiple heterogeneous sources is usually integrated in advance and
is kept in a warehouse. This particular given information is available to get direct querying and
evaluation.
Benefits:
o Approach provides top rated.
o The data is replicated, processed, integrated, annotated, described and restructured in semantic
data store in advance.
o Query processing does not need an interface to procedure data at local resources.
o Features of Data Warehouse Equipment and Utilities
o The following are the features of data warehouse equipment and utilities:
o Data Removal - Involves gathering information from multiple heterogeneous resources.
o Data Cleaning - Requires finding and correcting the particular errors in data.
o Data Transformation - Involves switching the data from legacy file format to warehouse format.
o Data Loading - Involves selecting, summarizing, consolidating, checking condition, plus building
partitions and indices.
o Refreshing - Requires updating from data resources to warehouse.
A Data lake
Data Lake is really a new and increasingly popular method to store and analyze information that
addresses many of these problems. Data Lake allows a business to store all of their information,
organized and unstructured, in one, and centralized database. Since data can be kept as-is, there is no
need to transform it to a predefined schema and you no longer need to know exactly what questions
you want to ask of the data beforehand.
A Data Lake should support these capabilities:
o Collecting and keeping any type of data, at any level and at low costs
o Securing and protecting all of information stored in the central database
o Searching and finding the related data in the central database
o Quickly and easily executing new types of data evaluation on datasets
o Querying the information by defining the data’s structure at the time of use (schema on read)
Furthermore, the Data Lake isn’t intended to be replacing your existing Information Warehouses, but
instead complement them. Should you be already using a Data Stockroom, or even are looking to
implement one particular, the Data Lake can be used being a source for both organized and
Update-Driven Approach
It is really an alternative to the traditional approach. All of us data warehouse systems adhere to update-
driven approach rather than the conventional approach discussed earlier. Within update-driven
approach, the information through multiple heterogeneous sources is usually integrated in advance and
is kept in a warehouse. This particular given information is available to get direct querying and
evaluation.
Benefits:
o Approach provides top rated.
o The data is replicated, processed, integrated, annotated, described and restructured in semantic
data store in advance.
o Query processing does not need an interface to procedure data at local resources.
o Features of Data Warehouse Equipment and Utilities
o The following are the features of data warehouse equipment and utilities:
o Data Removal - Involves gathering information from multiple heterogeneous resources.
o Data Cleaning - Requires finding and correcting the particular errors in data.
o Data Transformation - Involves switching the data from legacy file format to warehouse format.
o Data Loading - Involves selecting, summarizing, consolidating, checking condition, plus building
partitions and indices.
o Refreshing - Requires updating from data resources to warehouse.
A Data lake
Data Lake is really a new and increasingly popular method to store and analyze information that
addresses many of these problems. Data Lake allows a business to store all of their information,
organized and unstructured, in one, and centralized database. Since data can be kept as-is, there is no
need to transform it to a predefined schema and you no longer need to know exactly what questions
you want to ask of the data beforehand.
A Data Lake should support these capabilities:
o Collecting and keeping any type of data, at any level and at low costs
o Securing and protecting all of information stored in the central database
o Searching and finding the related data in the central database
o Quickly and easily executing new types of data evaluation on datasets
o Querying the information by defining the data’s structure at the time of use (schema on read)
Furthermore, the Data Lake isn’t intended to be replacing your existing Information Warehouses, but
instead complement them. Should you be already using a Data Stockroom, or even are looking to
implement one particular, the Data Lake can be used being a source for both organized and

unstructured data, which can be easily changed into a well-defined schema just before ingesting it into
your Information Warehouse.
Task 1.2) a data warehouse, a data lake and a data mart would be used in an organization
Use of a data warehouse to have an organization including:
• Possible high returns on purchase
Implementation of data storage by an organization requires a massive investment typically from Rest 10
lack to fifty lacks. However, a study by International Data Corporation (IDC) in 1996 reported which will
average three-year returns on investment (RO I) within data warehousing reached 401%.
• Competitive advantage
The specific huge returns on financial commitment for those companies that have efficiently
implemented a data stockroom are evidence of the massive competitive advantage that includes this
technology. The competing advantage is gained simply by allowing decision-makers access to
information that can reveal previously not available, unknown, and untapped house elevators, for
example , customers, trends, in addition demands.
• Increased efficiency of corporate decision-makers
Information warehousing improves the efficiency of corporate decision-makers simply by creating an
integrated database associated with consistent, subject-oriented, historical details. It integrates data
through multiple incompatible systems to a form that provides one constant view of the organization.
Simply by transforming data into substantial information, a data storage space place allows business
managers to do more substantive, accurate, plus consistent analysis.
• Much more cost-effective decision-making
Data storage space helps to reduce the overall price of the· product· by decreasing the number of
channels.
o Far better enterprise intelligence.
o It helps to give better enterprise intelligence.
o Enhanced customer service.
A Data mart
A data mart is a subset of information from an enterprise information ware house in which the
importance is limited to a specific company unit or group of customers.
Data marts provide a long range view of data inside a given subject area, like sales or finance. Data
marts provide the exact same benefits of a data stockroom, using limited scope and dimension.
your Information Warehouse.
Task 1.2) a data warehouse, a data lake and a data mart would be used in an organization
Use of a data warehouse to have an organization including:
• Possible high returns on purchase
Implementation of data storage by an organization requires a massive investment typically from Rest 10
lack to fifty lacks. However, a study by International Data Corporation (IDC) in 1996 reported which will
average three-year returns on investment (RO I) within data warehousing reached 401%.
• Competitive advantage
The specific huge returns on financial commitment for those companies that have efficiently
implemented a data stockroom are evidence of the massive competitive advantage that includes this
technology. The competing advantage is gained simply by allowing decision-makers access to
information that can reveal previously not available, unknown, and untapped house elevators, for
example , customers, trends, in addition demands.
• Increased efficiency of corporate decision-makers
Information warehousing improves the efficiency of corporate decision-makers simply by creating an
integrated database associated with consistent, subject-oriented, historical details. It integrates data
through multiple incompatible systems to a form that provides one constant view of the organization.
Simply by transforming data into substantial information, a data storage space place allows business
managers to do more substantive, accurate, plus consistent analysis.
• Much more cost-effective decision-making
Data storage space helps to reduce the overall price of the· product· by decreasing the number of
channels.
o Far better enterprise intelligence.
o It helps to give better enterprise intelligence.
o Enhanced customer service.
A Data mart
A data mart is a subset of information from an enterprise information ware house in which the
importance is limited to a specific company unit or group of customers.
Data marts provide a long range view of data inside a given subject area, like sales or finance. Data
marts provide the exact same benefits of a data stockroom, using limited scope and dimension.
⊘ This is a preview!⊘
Do you want full access?
Subscribe today to unlock all pages.
Trusted by 1+ million students worldwide

Data marts are utilized by a variety of businesspeople. The advantages of a data mart generally arise
because it is too time-consuming to collect the information the users require directly from the source
database.
The data mart gives customers direct access to specific information about the performance of their
company unit. It is a cost-effective replacement for a data warehouse, which could take many months to
create. A data mart is simple to use because it is designed especially for the needs of its users, the data
mart can speed up business processes thus.
A data lake
A data lake, nevertheless, you can put all sorts of information into a single repository without worrying
regarding schemas that define the incorporation points between different information sets.
Ability to handle loading data
Today’s data planet is a streaming world. Loading has evolved from rare make use of cases, for example
sensor data from the share and Iota market information, to common everyday data, such as social
networking.
Fitting the task to the device
When you store data within an EDW, it works well for several kinds of analytics. But when you are
utilizing Spark, Map Reduce, or some other new models, preparing information for analysis in an EDW
can take more time than executing the actual analytics. In an information lake, information can be
processed by these types of new paradigm tools without having excessive prep work effectively.
Integrating information involves fewer steps due to the fact data lakes don’t impose a rigid metadata
schema. Schema-on-read allows users to create custom schema into their questions upon query
execution.
Simpler accessibility
Information lakes also solve the task of data accessibility plus integration that plague EDWs. Using Large
Data Hardtop infrastructures, you are able to bring together ever-larger data quantities for analytics-or
simply shop them for some as-yet-undetermined upcoming use. Unlike a monolithic see of a single
enterprise-wide information model, the data lake enables you to put off modeling until you really use
the data, which usually creates opportunities for much better operational insights and information
discovery. This particular advantage only grows because data volumes, variety, plus metadata richness
increase.
Decreased costs
Because of economies associated with scale, some Hadoop customers claim they pay lower than $1, 000
per tb for a Hadoop cluster. Even though numbers can vary, business customers understand that
because it is too time-consuming to collect the information the users require directly from the source
database.
The data mart gives customers direct access to specific information about the performance of their
company unit. It is a cost-effective replacement for a data warehouse, which could take many months to
create. A data mart is simple to use because it is designed especially for the needs of its users, the data
mart can speed up business processes thus.
A data lake
A data lake, nevertheless, you can put all sorts of information into a single repository without worrying
regarding schemas that define the incorporation points between different information sets.
Ability to handle loading data
Today’s data planet is a streaming world. Loading has evolved from rare make use of cases, for example
sensor data from the share and Iota market information, to common everyday data, such as social
networking.
Fitting the task to the device
When you store data within an EDW, it works well for several kinds of analytics. But when you are
utilizing Spark, Map Reduce, or some other new models, preparing information for analysis in an EDW
can take more time than executing the actual analytics. In an information lake, information can be
processed by these types of new paradigm tools without having excessive prep work effectively.
Integrating information involves fewer steps due to the fact data lakes don’t impose a rigid metadata
schema. Schema-on-read allows users to create custom schema into their questions upon query
execution.
Simpler accessibility
Information lakes also solve the task of data accessibility plus integration that plague EDWs. Using Large
Data Hardtop infrastructures, you are able to bring together ever-larger data quantities for analytics-or
simply shop them for some as-yet-undetermined upcoming use. Unlike a monolithic see of a single
enterprise-wide information model, the data lake enables you to put off modeling until you really use
the data, which usually creates opportunities for much better operational insights and information
discovery. This particular advantage only grows because data volumes, variety, plus metadata richness
increase.
Decreased costs
Because of economies associated with scale, some Hadoop customers claim they pay lower than $1, 000
per tb for a Hadoop cluster. Even though numbers can vary, business customers understand that
Paraphrase This Document
Need a fresh take? Get an instant paraphrase of this document with our AI Paraphraser

because it’s no more excessively costly for them to shop all their data, they could maintain copies of
everything simply by dumping it into Hadoop simply, to become discovered and analyzed later on.
Scalability
Huge Data is typically defined as the particular intersection between volume, variety, plus velocity.
EDWs are well known for not being able to scale over and above a certain volume due to limitations of
the architecture. Data digesting takes so long that institutions are prevented from taking advantage of
all their data to the fullest extent. Using Hadoop, petabyte- scale data lakes are cost-efficient and simple
to create and maintain at whatever size is desired relatively.
A data mart:
o To partition data to be able to impose access control techniques.
o To speed up the questions by reducing the volume associated with data to be scanned.
o To segment data into various hardware platforms.
o To framework data in a form ideal for a user access tool.
Budget-friendly Data Marting
Follow the actions given below to make information marting cost-effective:
o Identify the particular Functional Splits
o Identify Consumer Access Tool Requirements
o Identify Access Control Issues
A retail organization, exactly where each merchant is responsible for maximizing the sales of the group
of products. With this, the following are the valuable info:
o sales transaction on a daily basis
o sales forecast on a weekly schedule
o stock position on a daily basis
o stock movements on a daily basis
As the service provider is not interested in the products they may not be dealing with, the data marting
is really a subset of the data coping which the product group of curiosity. The following diagram shows
information marting for different users.
everything simply by dumping it into Hadoop simply, to become discovered and analyzed later on.
Scalability
Huge Data is typically defined as the particular intersection between volume, variety, plus velocity.
EDWs are well known for not being able to scale over and above a certain volume due to limitations of
the architecture. Data digesting takes so long that institutions are prevented from taking advantage of
all their data to the fullest extent. Using Hadoop, petabyte- scale data lakes are cost-efficient and simple
to create and maintain at whatever size is desired relatively.
A data mart:
o To partition data to be able to impose access control techniques.
o To speed up the questions by reducing the volume associated with data to be scanned.
o To segment data into various hardware platforms.
o To framework data in a form ideal for a user access tool.
Budget-friendly Data Marting
Follow the actions given below to make information marting cost-effective:
o Identify the particular Functional Splits
o Identify Consumer Access Tool Requirements
o Identify Access Control Issues
A retail organization, exactly where each merchant is responsible for maximizing the sales of the group
of products. With this, the following are the valuable info:
o sales transaction on a daily basis
o sales forecast on a weekly schedule
o stock position on a daily basis
o stock movements on a daily basis
As the service provider is not interested in the products they may not be dealing with, the data marting
is really a subset of the data coping which the product group of curiosity. The following diagram shows
information marting for different users.
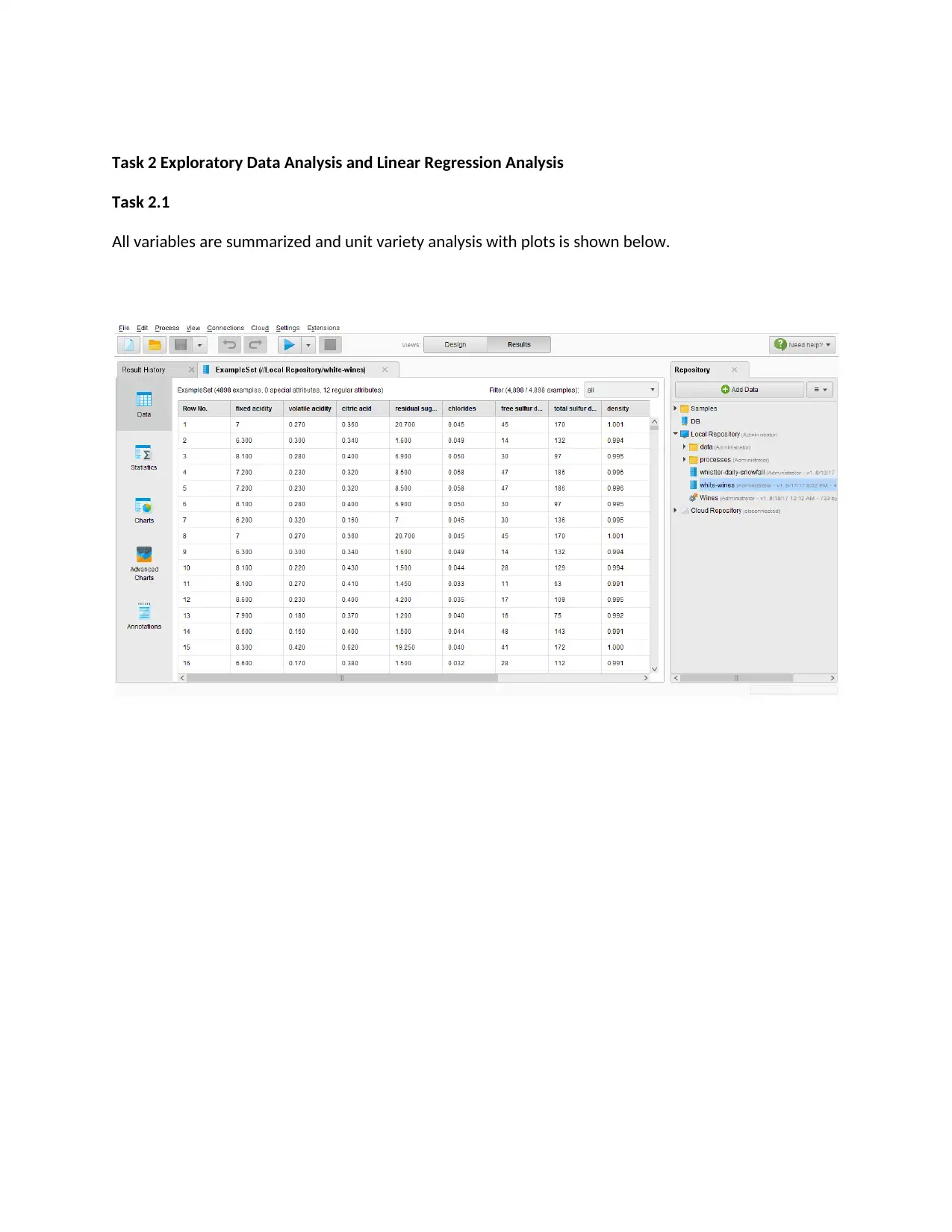
Task 2 Exploratory Data Analysis and Linear Regression Analysis
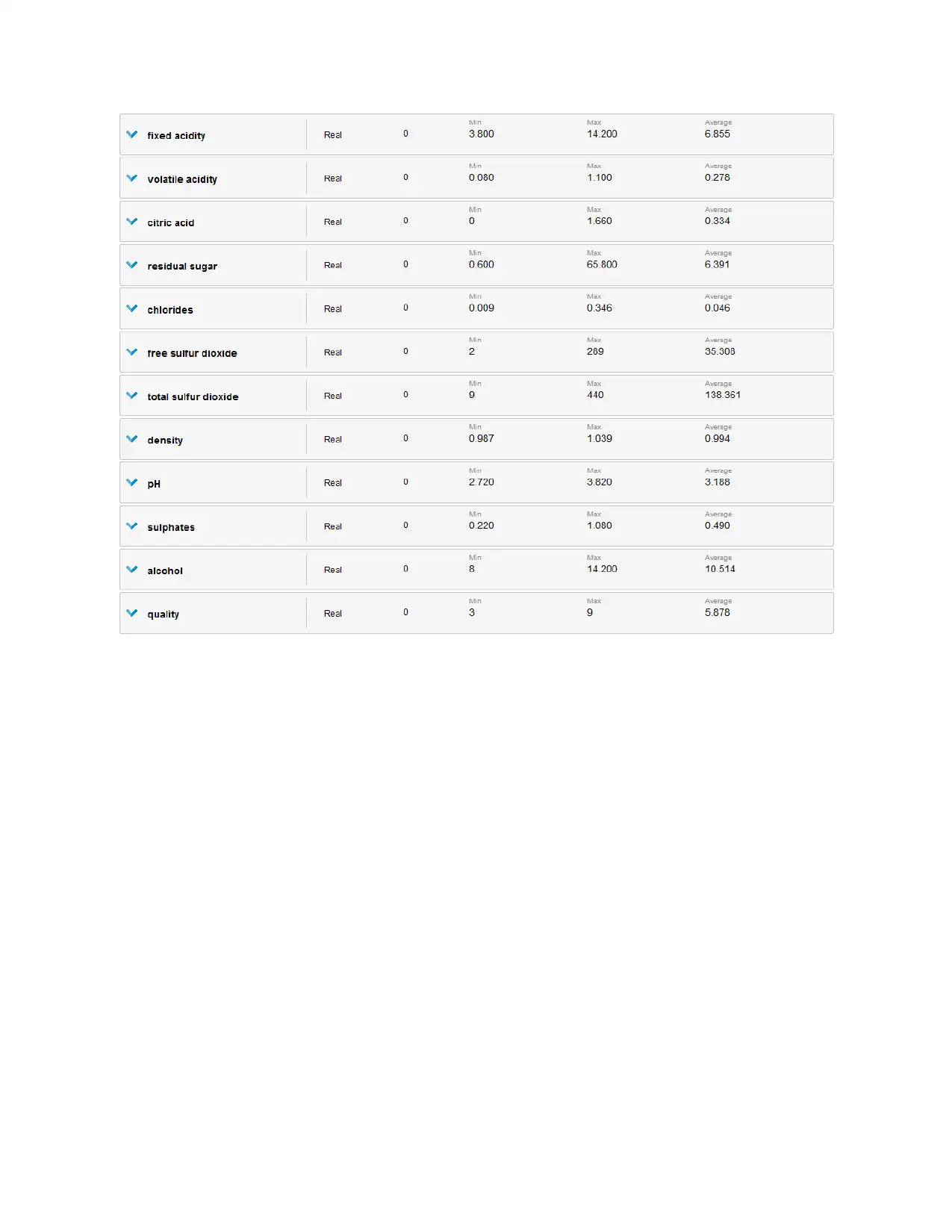
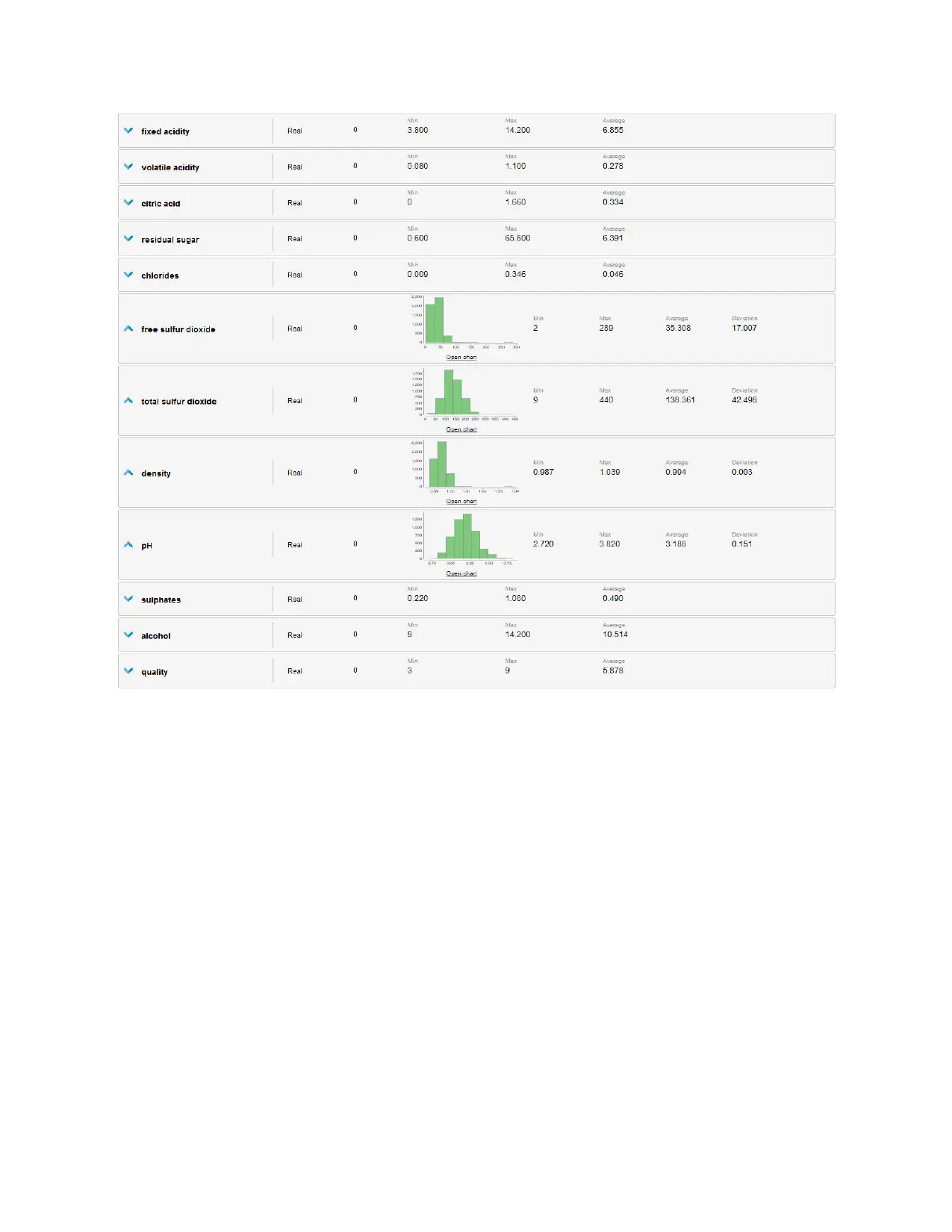
Task 2.1
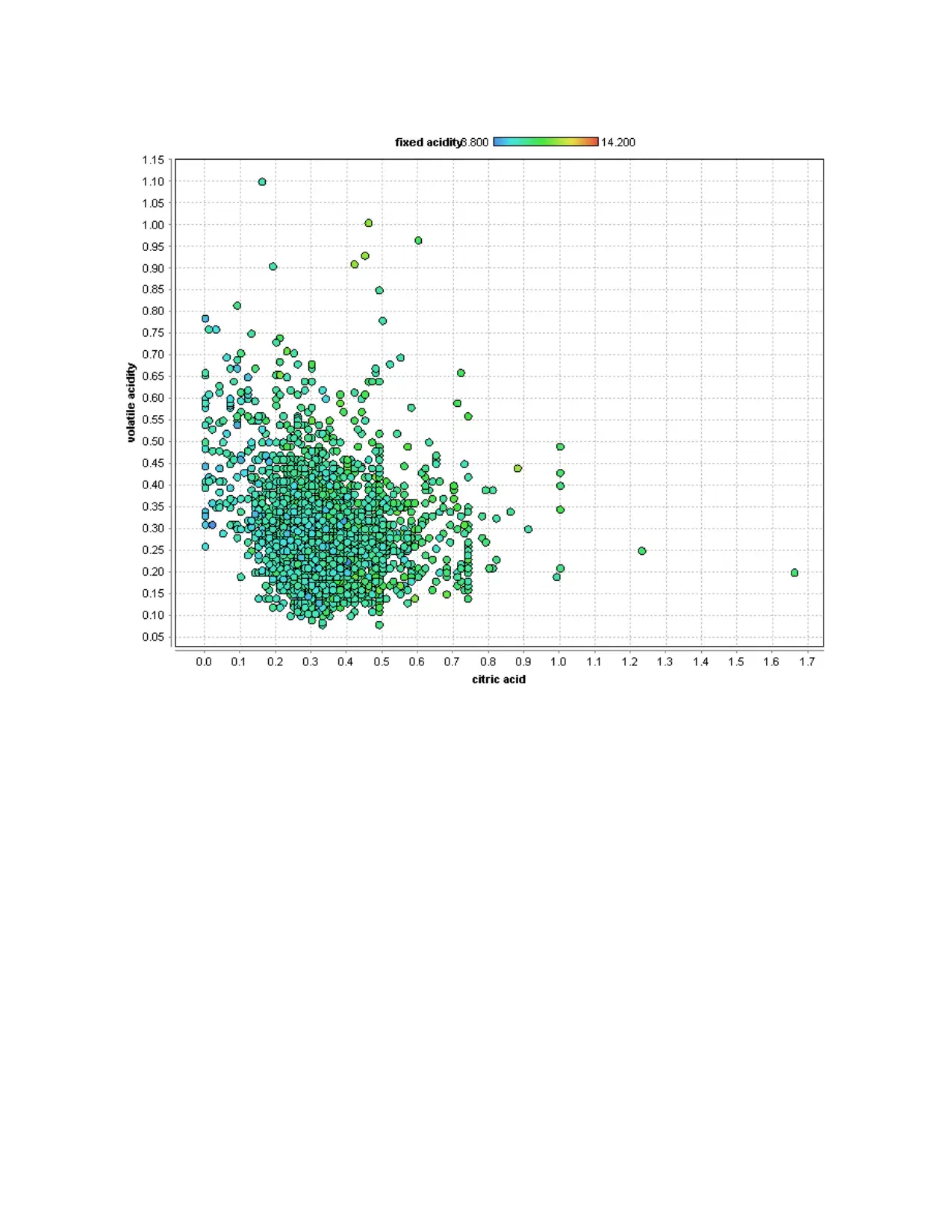
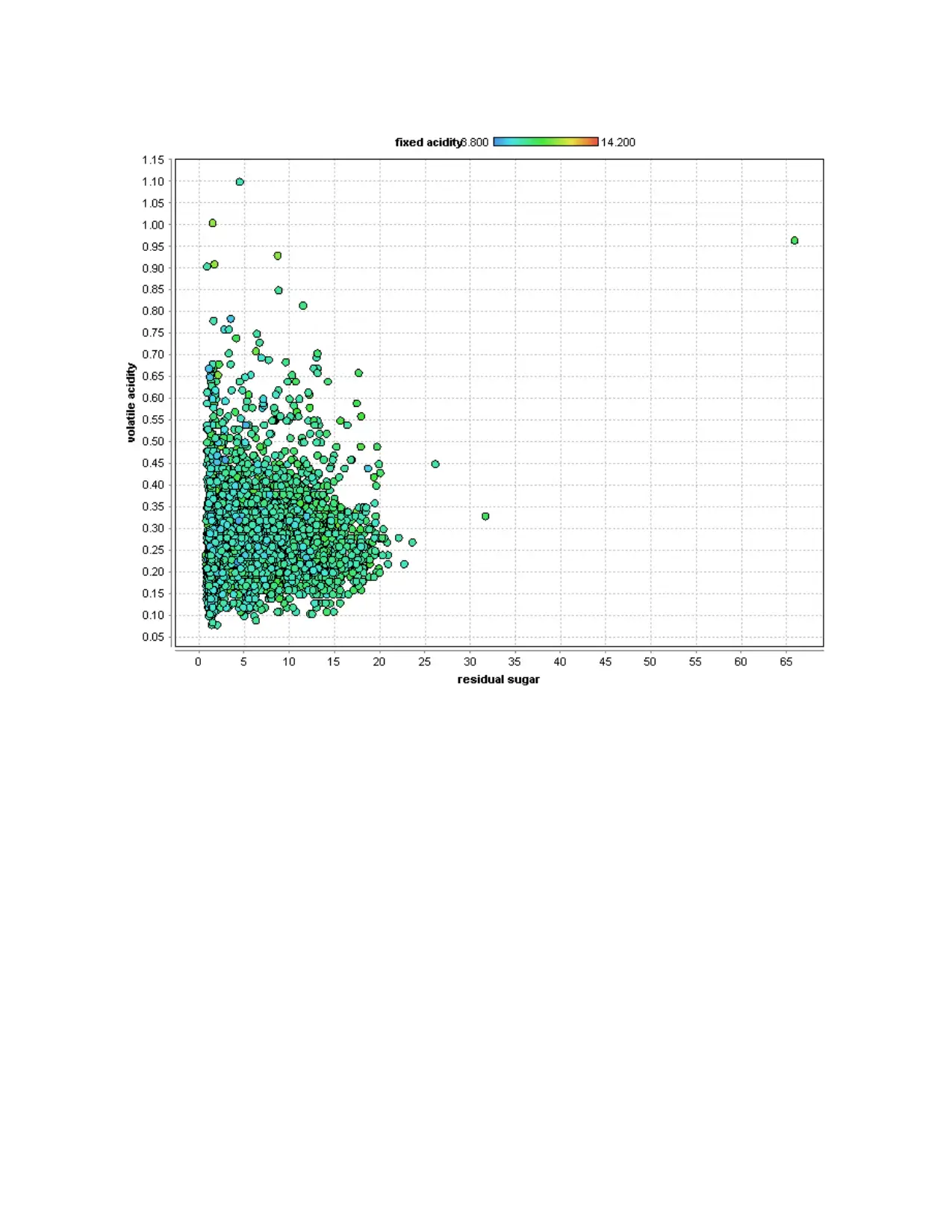
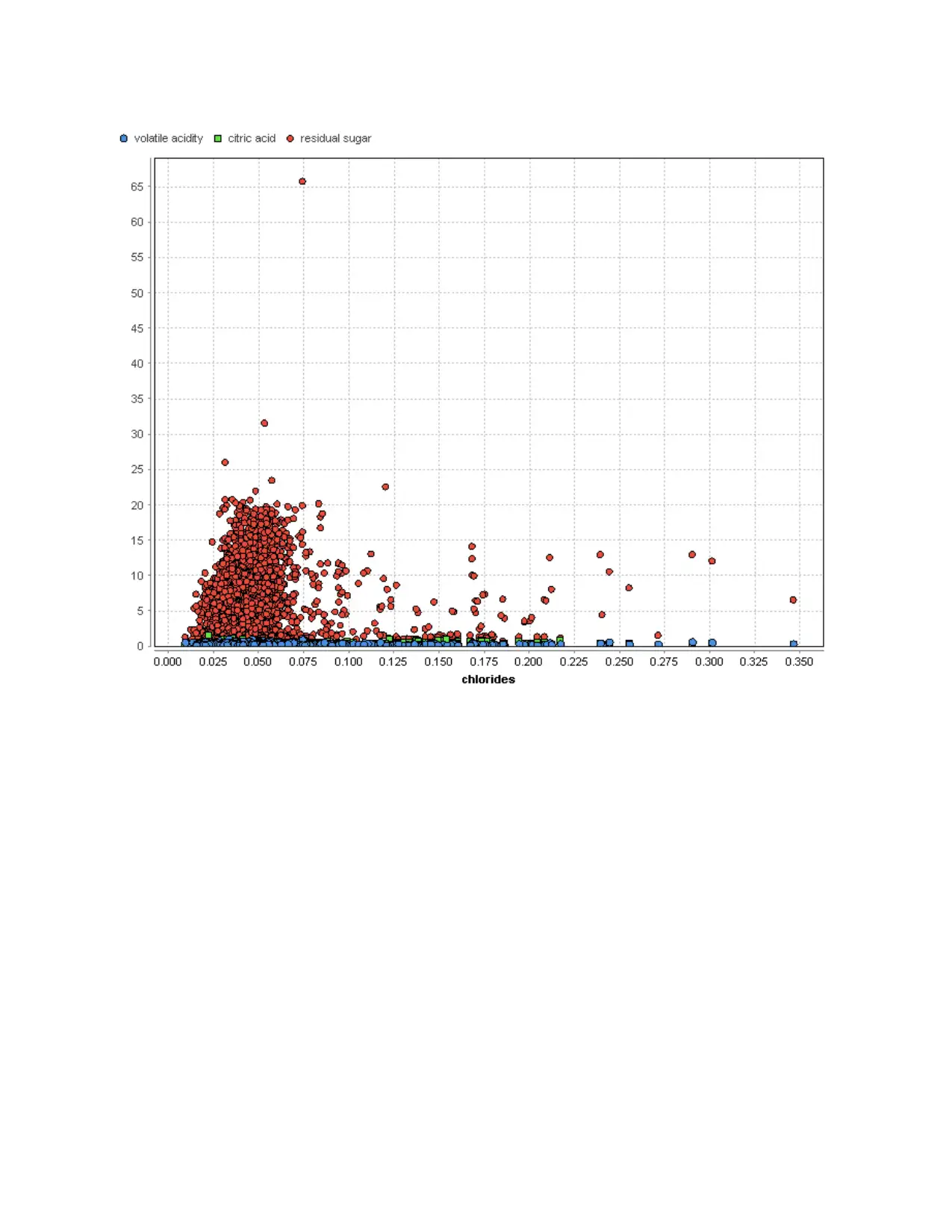
All variables are summarized and unit variety analysis with plots is shown below.
Task 2.1
All variables are summarized and unit variety analysis with plots is shown below.
⊘ This is a preview!⊘
Do you want full access?
Subscribe today to unlock all pages.
Trusted by 1+ million students worldwide
Paraphrase This Document
Need a fresh take? Get an instant paraphrase of this document with our AI Paraphraser
⊘ This is a preview!⊘
Do you want full access?
Subscribe today to unlock all pages.
Trusted by 1+ million students worldwide
Paraphrase This Document
Need a fresh take? Get an instant paraphrase of this document with our AI Paraphraser
⊘ This is a preview!⊘
Do you want full access?
Subscribe today to unlock all pages.
Trusted by 1+ million students worldwide
1 out of 28
Related Documents




Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Unlock your academic potential
Copyright © 2020–2026 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.