Data Mining Assignment: XL Miner, Association, Clustering Analysis
VerifiedAdded on 2020/04/01
|4
|1026
|46
Homework Assignment
AI Summary
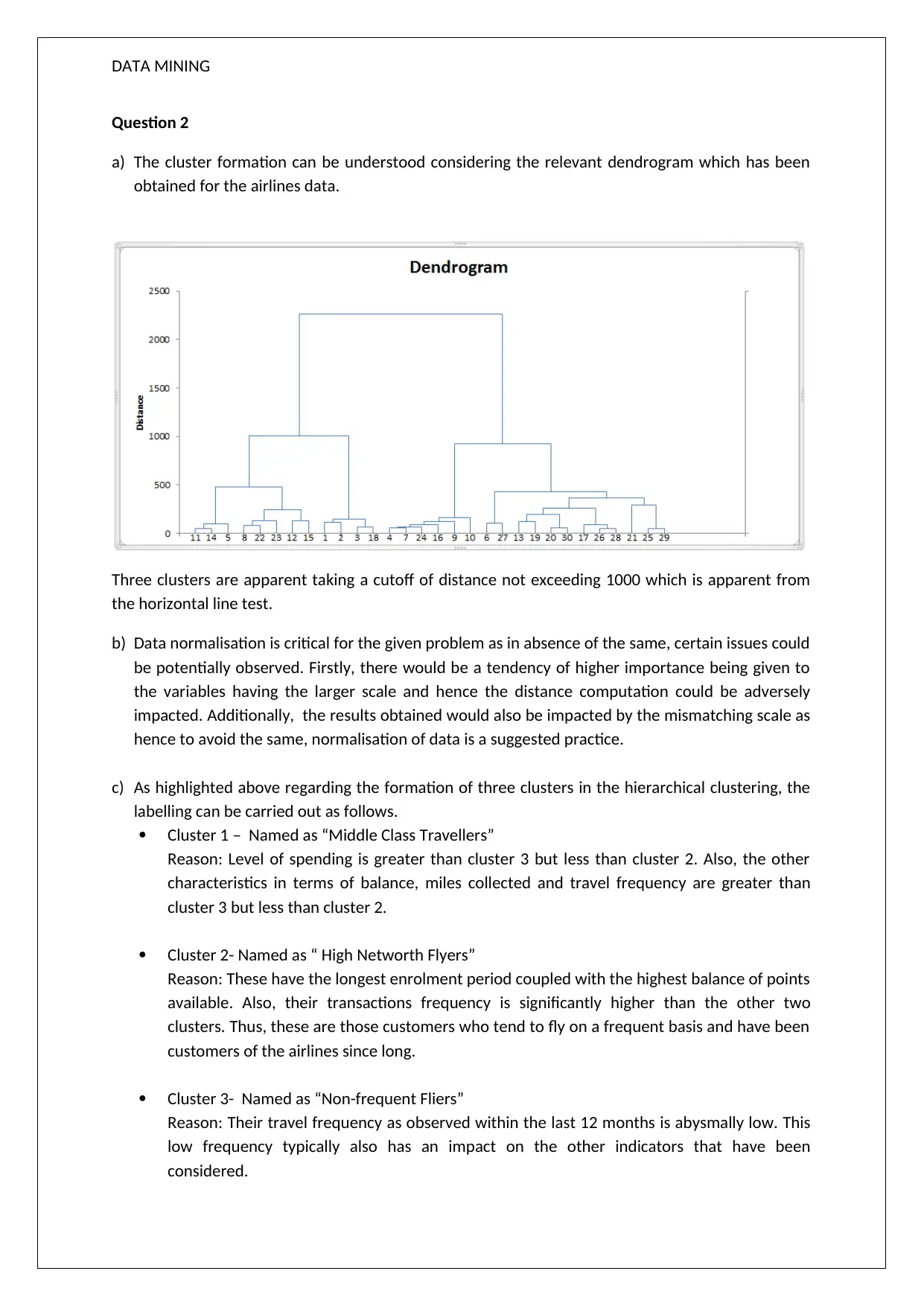
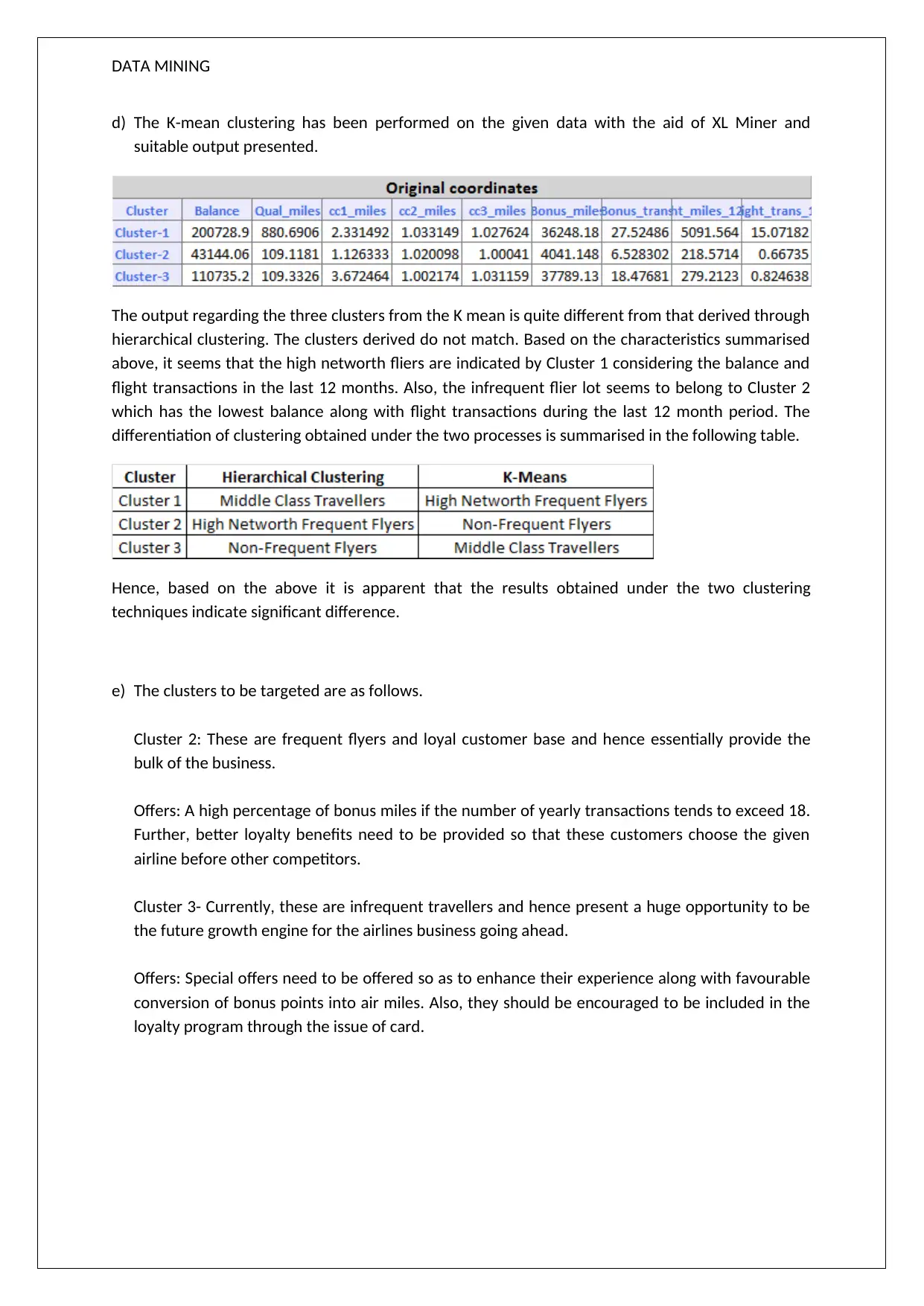
This assignment solution delves into data mining, focusing on association rules and clustering techniques using XL Miner. Question 1 analyzes association rules, exploring concepts like confidence levels and redundancy, with examples of brush, nail polish, and bronzer purchases. Question 2 focuses on cluster formation using airlines data, comparing hierarchical and K-means clustering. It discusses the importance of data normalization and identifies three clusters: "Middle Class Travellers," "High Networth Flyers," and "Non-frequent Fliers." The solution highlights the differences between the two clustering methods and proposes targeted offers for each customer segment, aiming to enhance loyalty and encourage increased travel frequency. The assignment provides a comprehensive analysis of data mining principles and their practical application in customer segmentation and business strategy.


1 out of 4
Related Documents






Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Copyright © 2020–2026 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.