Data Mining and Visualization for Business Intelligence Assignment - 3
VerifiedAdded on 2020/03/16
|6
|1216
|89
Project
AI Summary
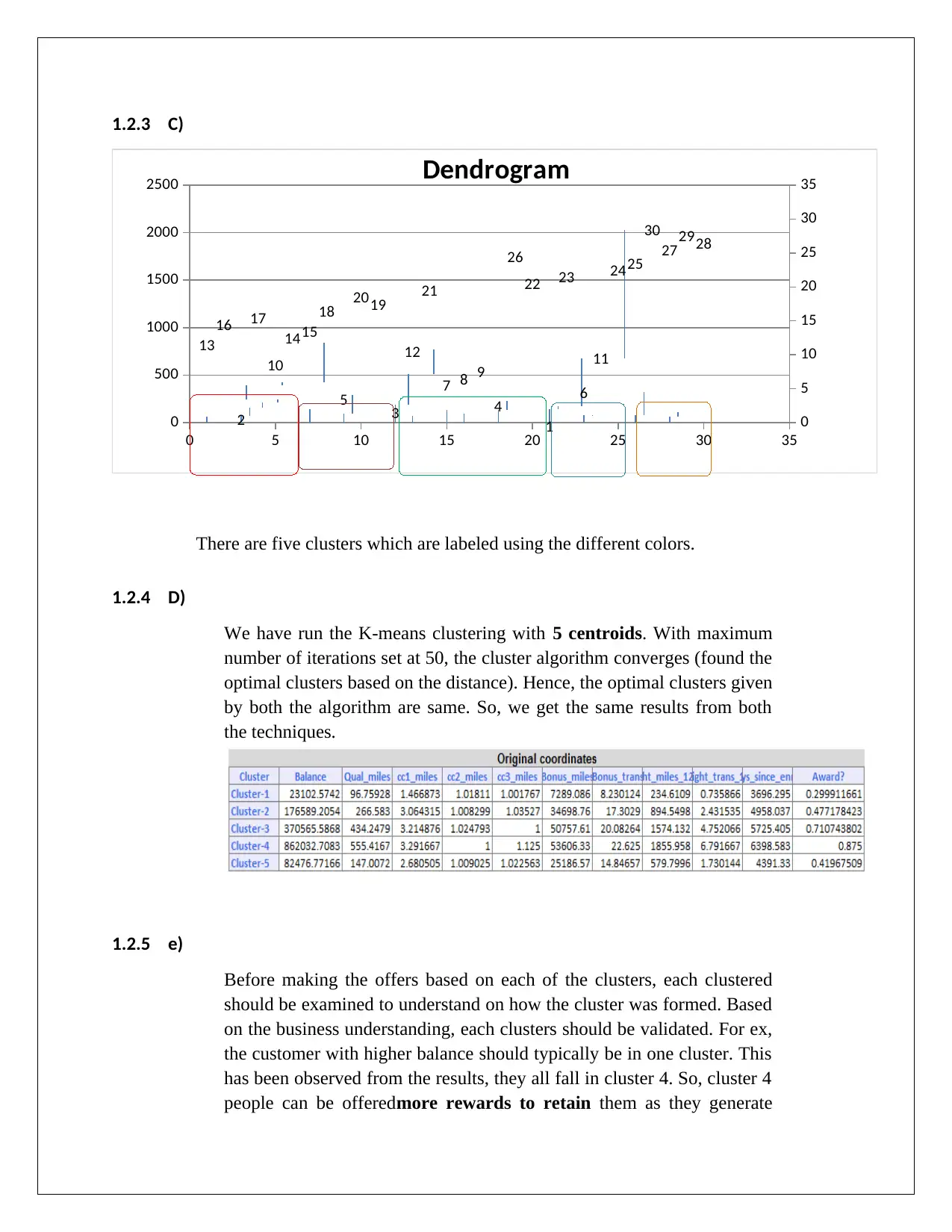
This assignment explores data mining and visualization techniques for business intelligence. It covers association rules, including concepts like antecedents, consequents, confidence levels, and lift ratios, using examples to illustrate how these rules can be applied to understand customer purchasing behavior. The assignment also delves into cluster analysis, specifically K-means clustering, discussing the importance of data normalization, the interpretation of clusters, and how clustered data can inform business decisions such as targeted marketing offers and customer retention strategies. The analysis is supported by references to relevant literature in the field of data mining and business intelligence.





1 out of 6
Related Documents






Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Copyright © 2020–2026 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.