Data Mining Assignment on Association Rules and Clustering Analysis
VerifiedAdded on 2020/03/04
|4
|991
|208
Homework Assignment
AI Summary
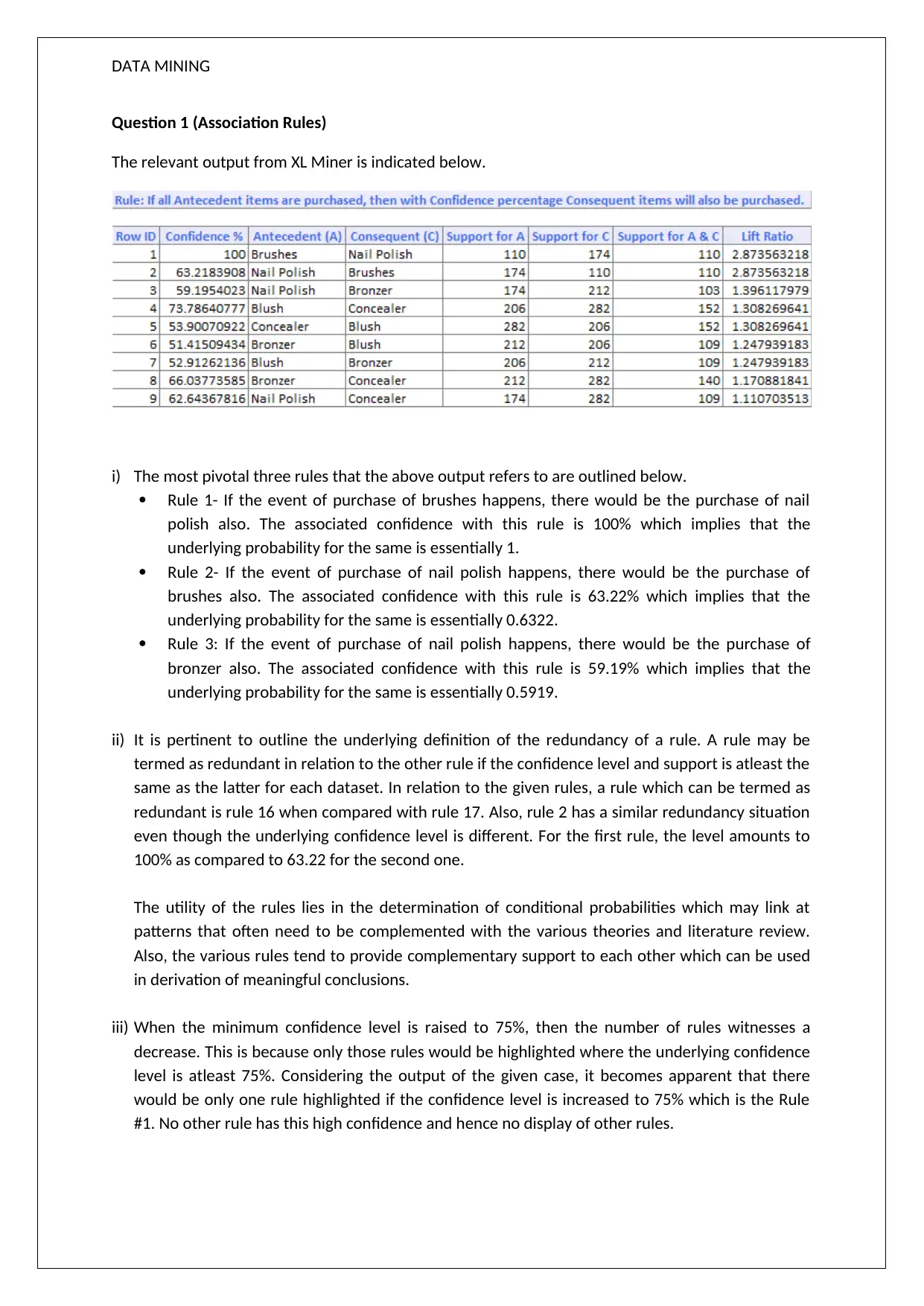
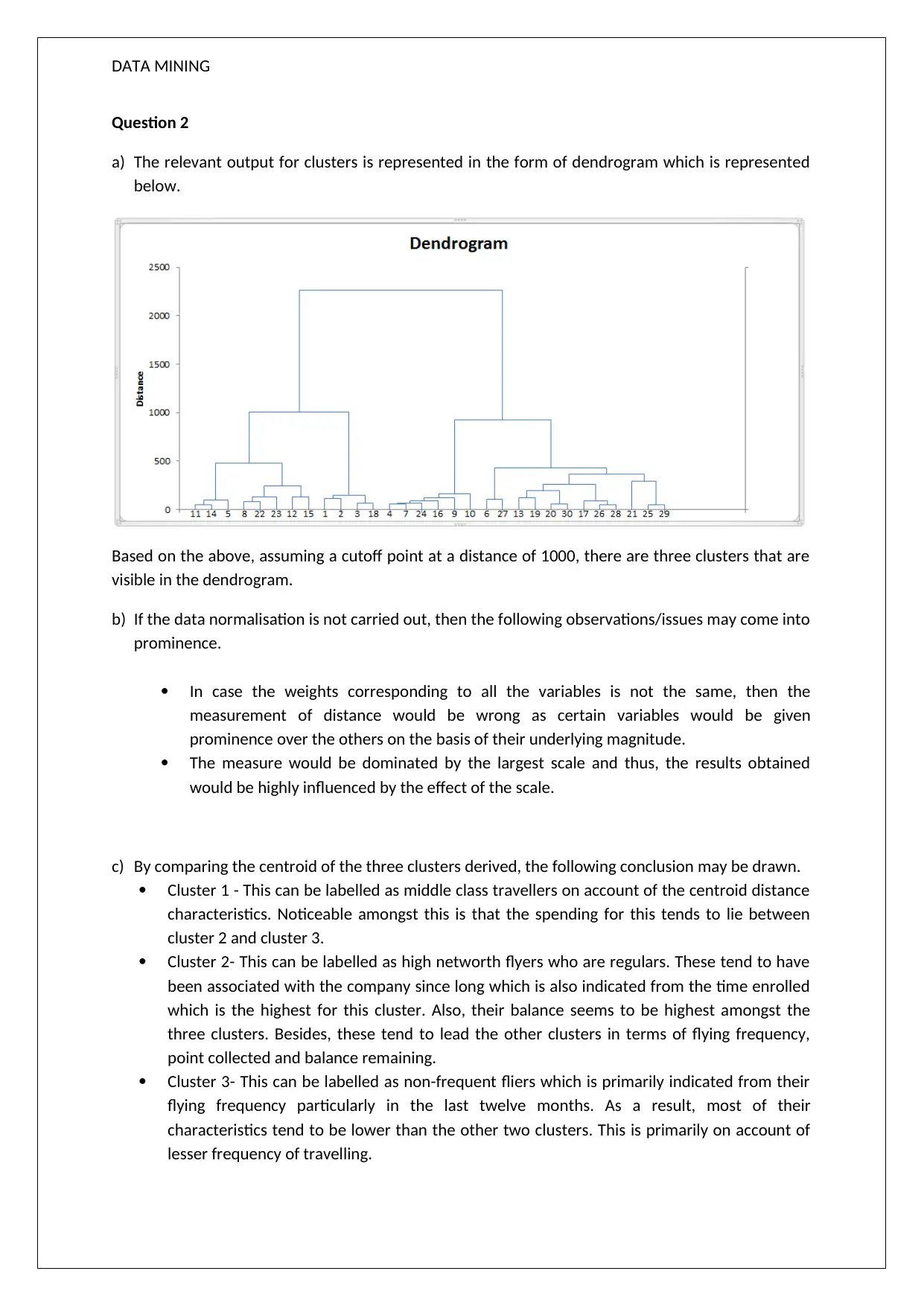
This data mining assignment explores association rules and clustering techniques using XL Miner. The solution analyzes three pivotal association rules, discussing their confidence and redundancy. It then delves into hierarchical clustering, interpreting a dendrogram to identify three clusters based on travel patterns and spending habits. The assignment also compares hierarchical clustering with K-Means clustering, highlighting differences in cluster characteristics. Finally, it provides recommendations for each cluster to enhance customer engagement and increase airline revenue, focusing on offers such as bonus points and frequent flyer card benefits to boost travel frequency and customer loyalty. The analysis provides insights into customer segmentation and targeted marketing strategies.


1 out of 4
Related Documents

![Data Mining Assignment for [Course Name] - Analysis and Findings](/_next/image/?url=https%3A%2F%2Fdesklib.com%2Fmedia%2Fimages%2Fml%2F8b9bb9b0c77d435887f2ac7476b3a62f.jpg&w=256&q=75)




Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Copyright © 2020–2026 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.