Comprehensive Solution for MIT4204 Data Mining Assignment
VerifiedAdded on 2023/04/24
|23
|3790
|116
Homework Assignment
AI Summary
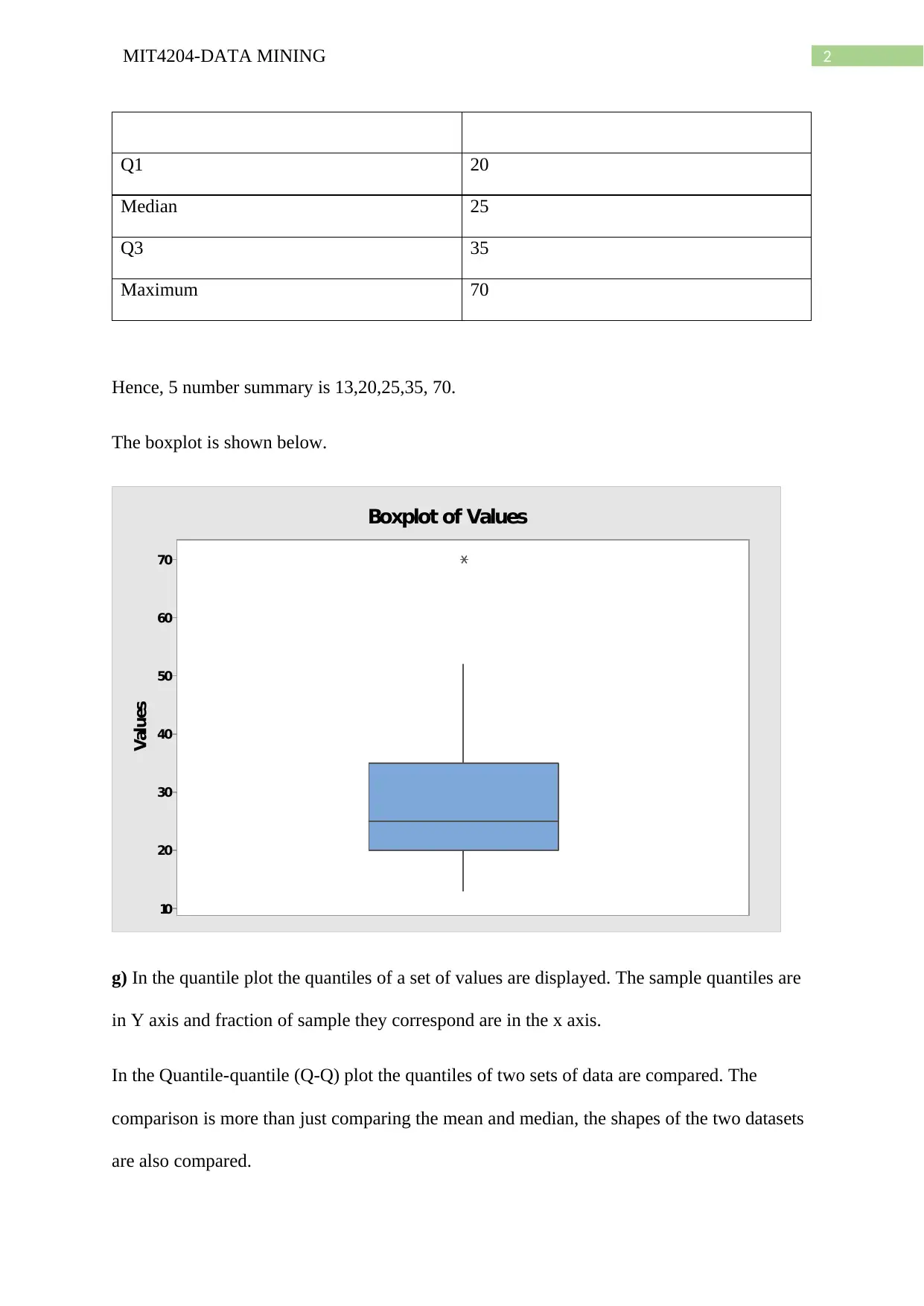
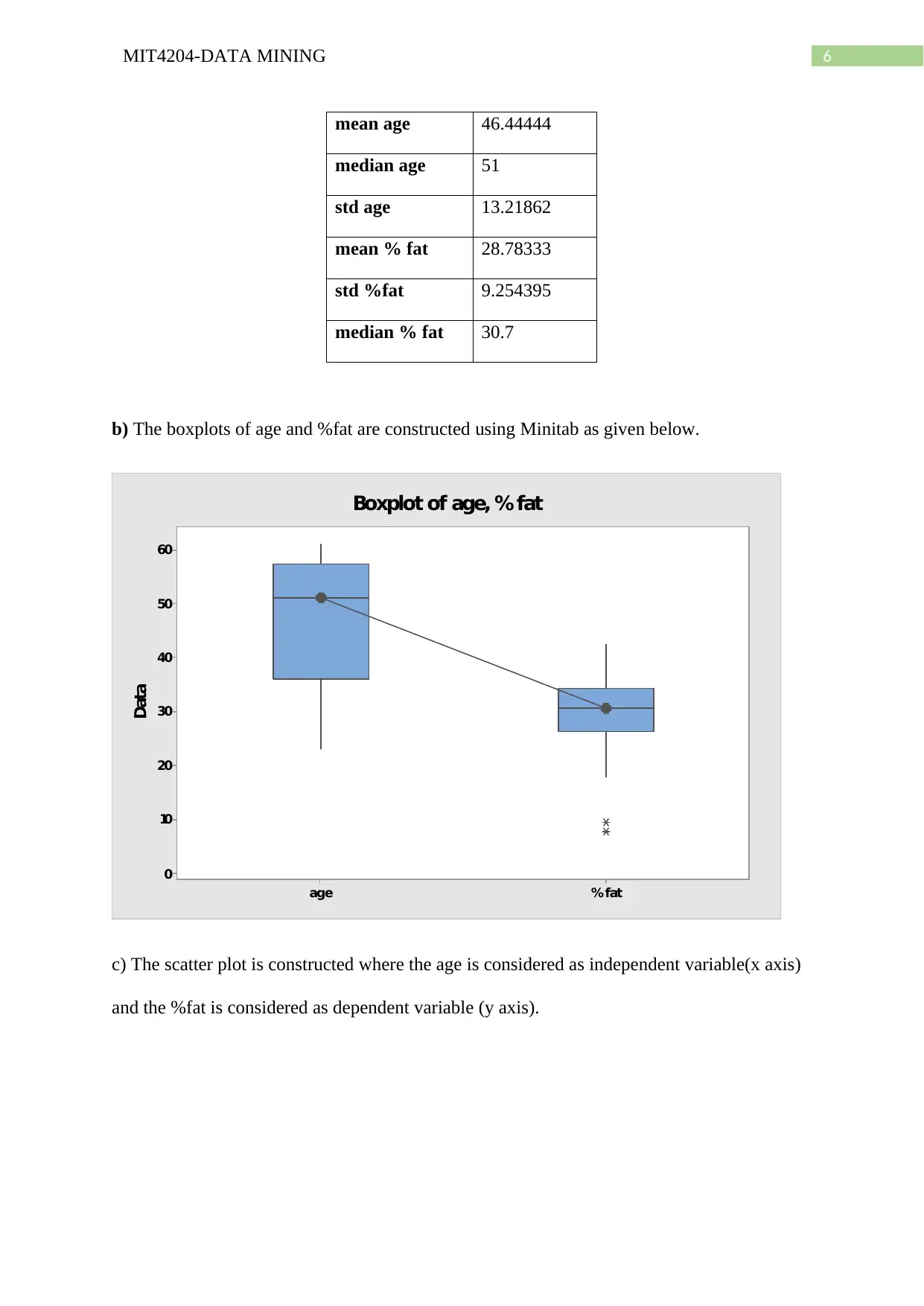
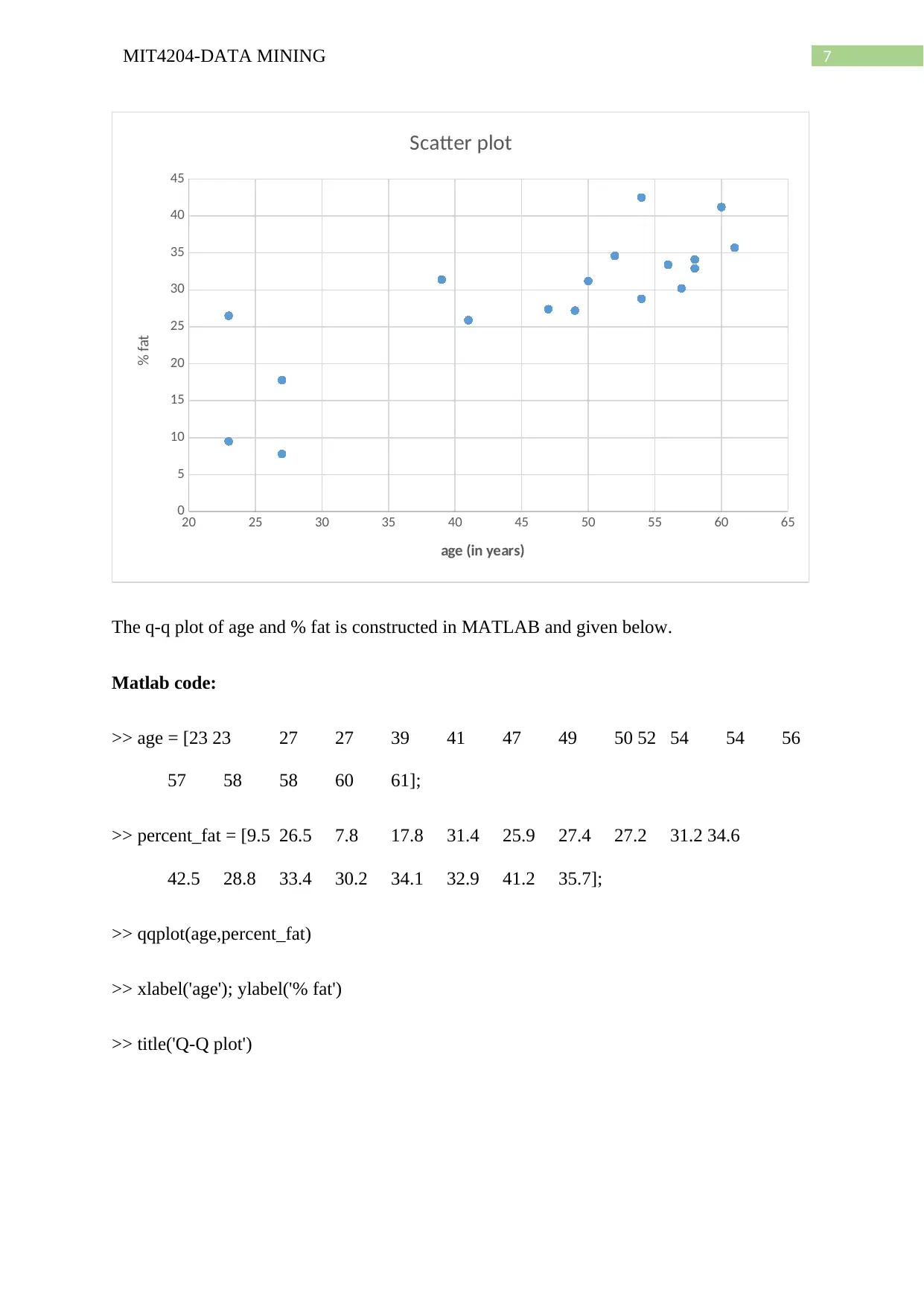
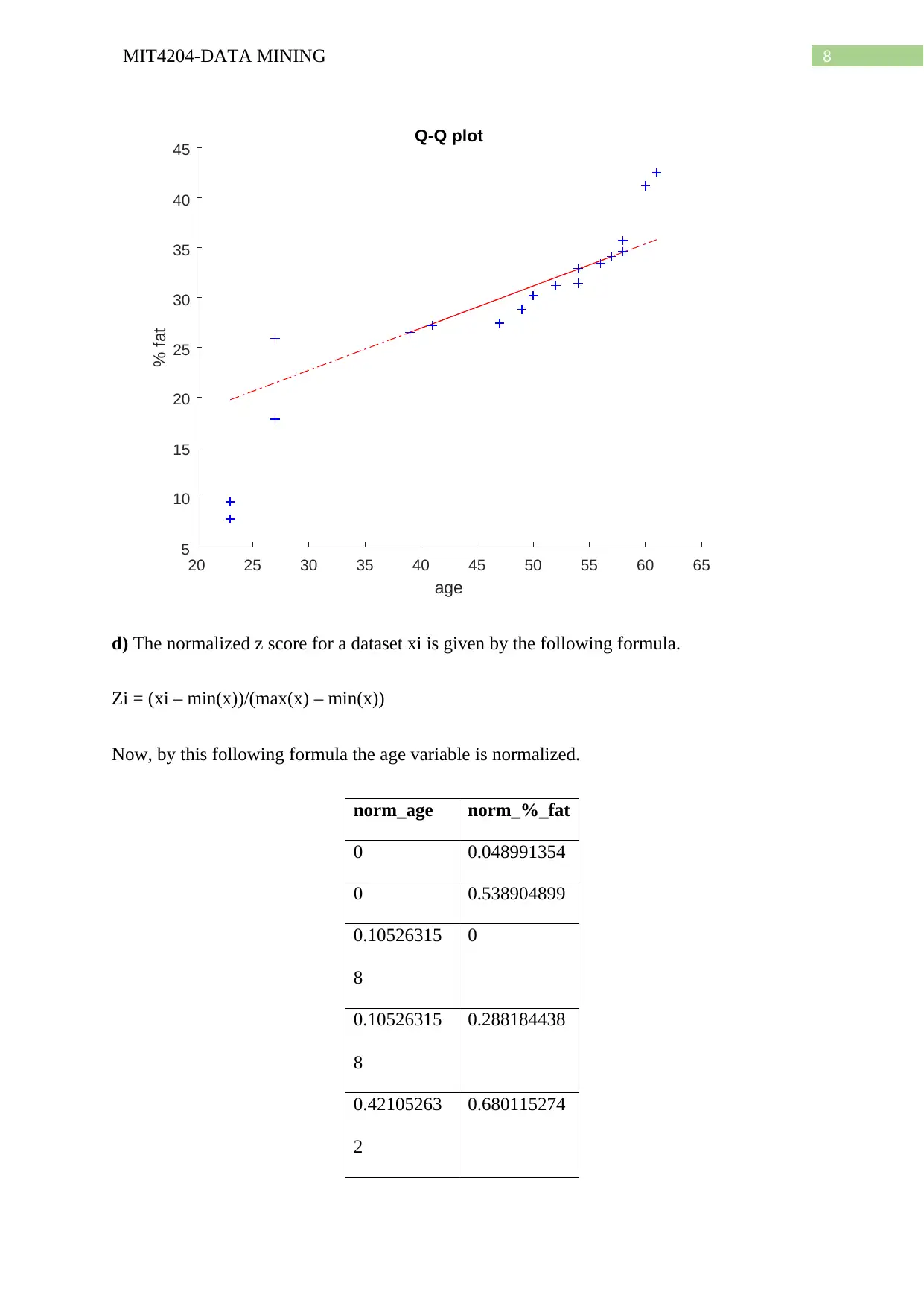
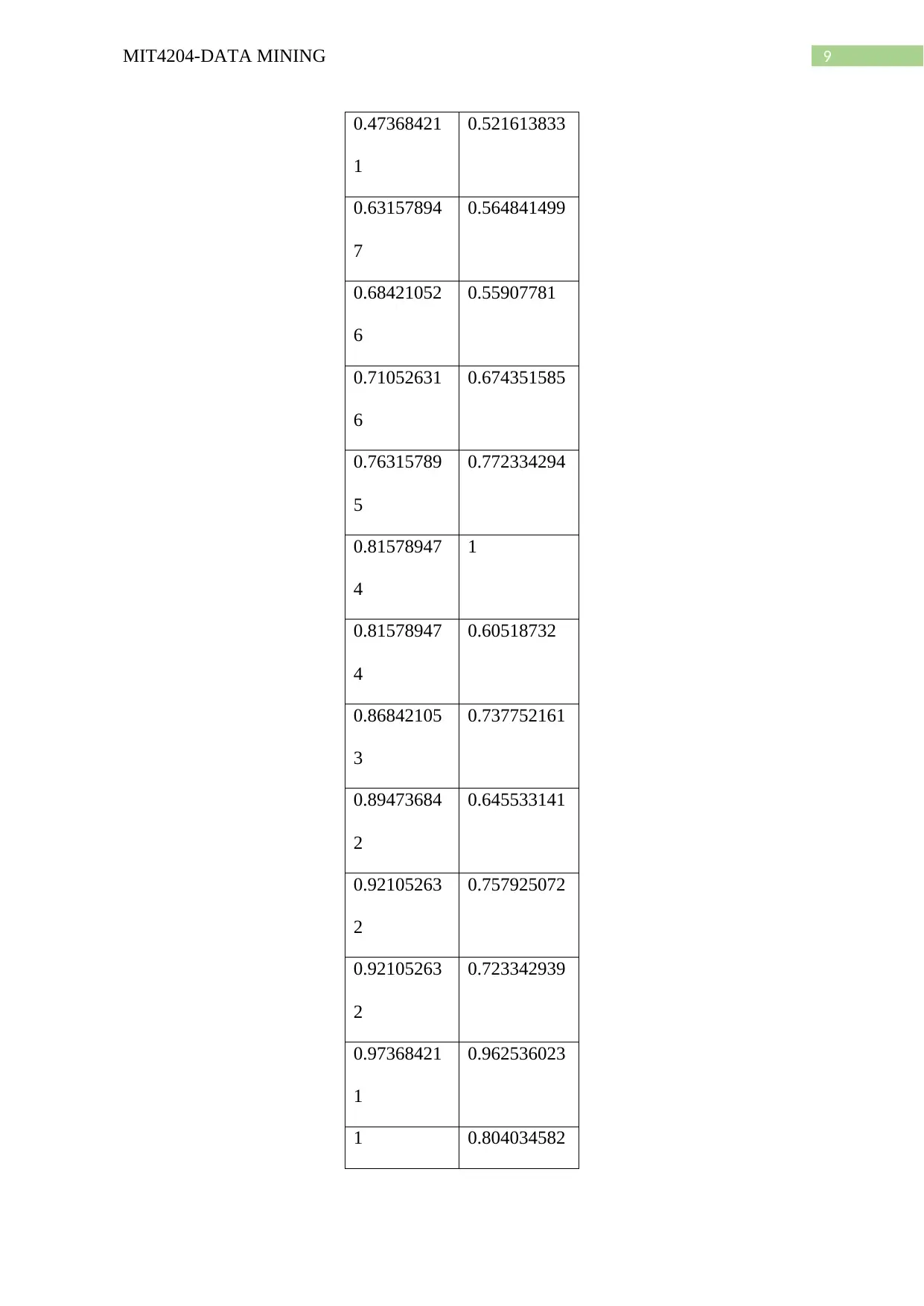
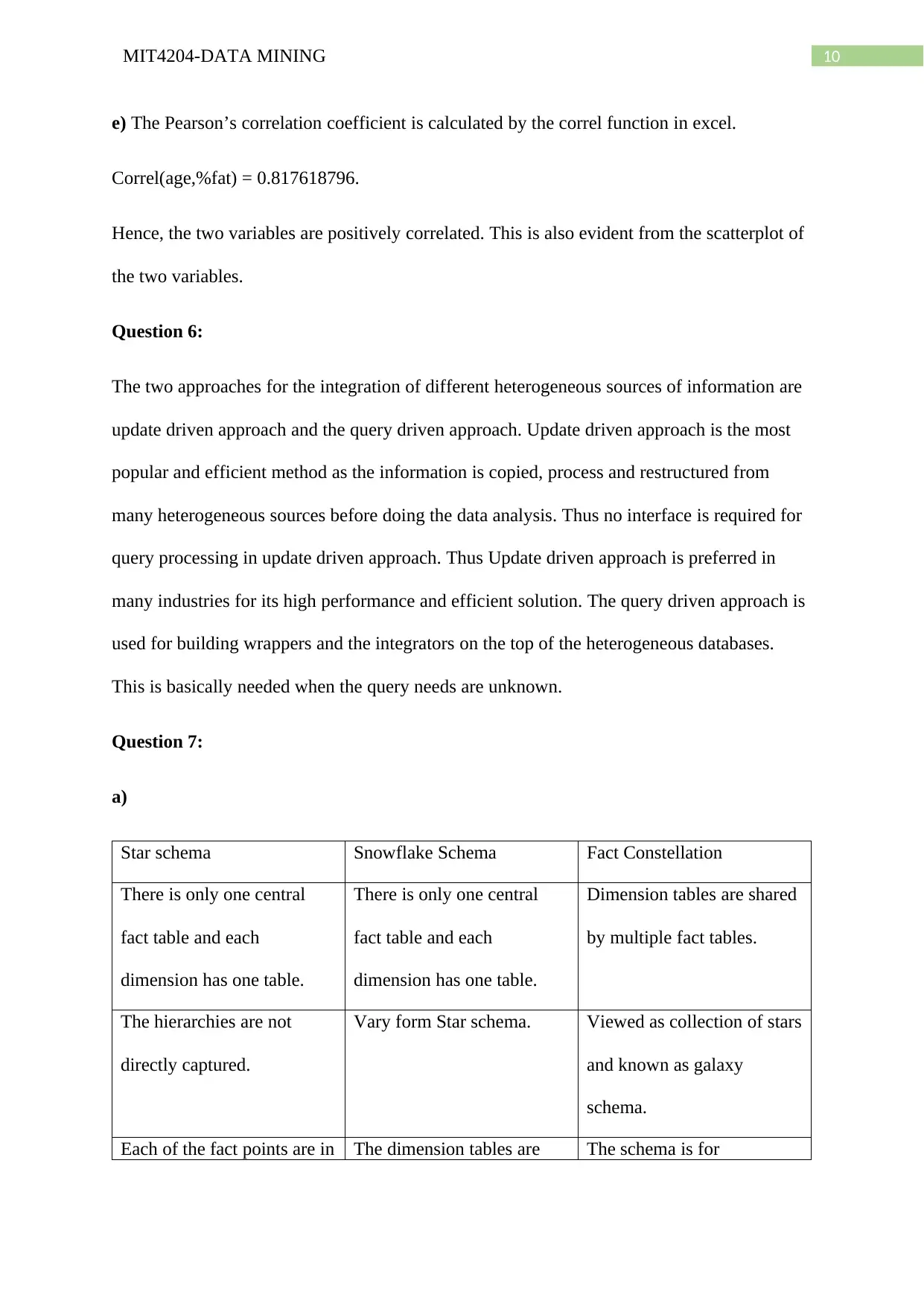
This document provides a detailed solution to a data mining assignment, covering a wide range of topics. It begins with statistical analysis, including calculations of mean, median, mode, midrange, quartiles, and the five-number summary, along with the creation of a boxplot and explanation of quantile plots. The solution then delves into distributive, algebraic, and holistic measures, and addresses methods for handling missing data. Further, it explores data smoothing techniques such as bin means, and discusses outliers and different smoothing methods. The assignment continues with an analysis of a dataset involving age and %fat, including calculations of mean, standard deviation, boxplots, scatter plots, and Q-Q plots, as well as normalization and correlation analysis. The solution also covers data integration approaches, schema types for data warehouses (star, snowflake, fact constellation), OLAP operations, and data warehouse modeling, including SQL queries. Finally, the document addresses data refresh, cleaning, and transformation processes, as well as the differences between data marts, enterprise warehouses, and virtual warehouses. Desklib offers this and many more past papers and solved assignments for students to excel in their studies.






1 out of 23
Related Documents





Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Copyright © 2020–2026 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.