Data Mining Assignment
VerifiedAdded on 2019/11/12
|8
|804
|312
Homework Assignment
AI Summary
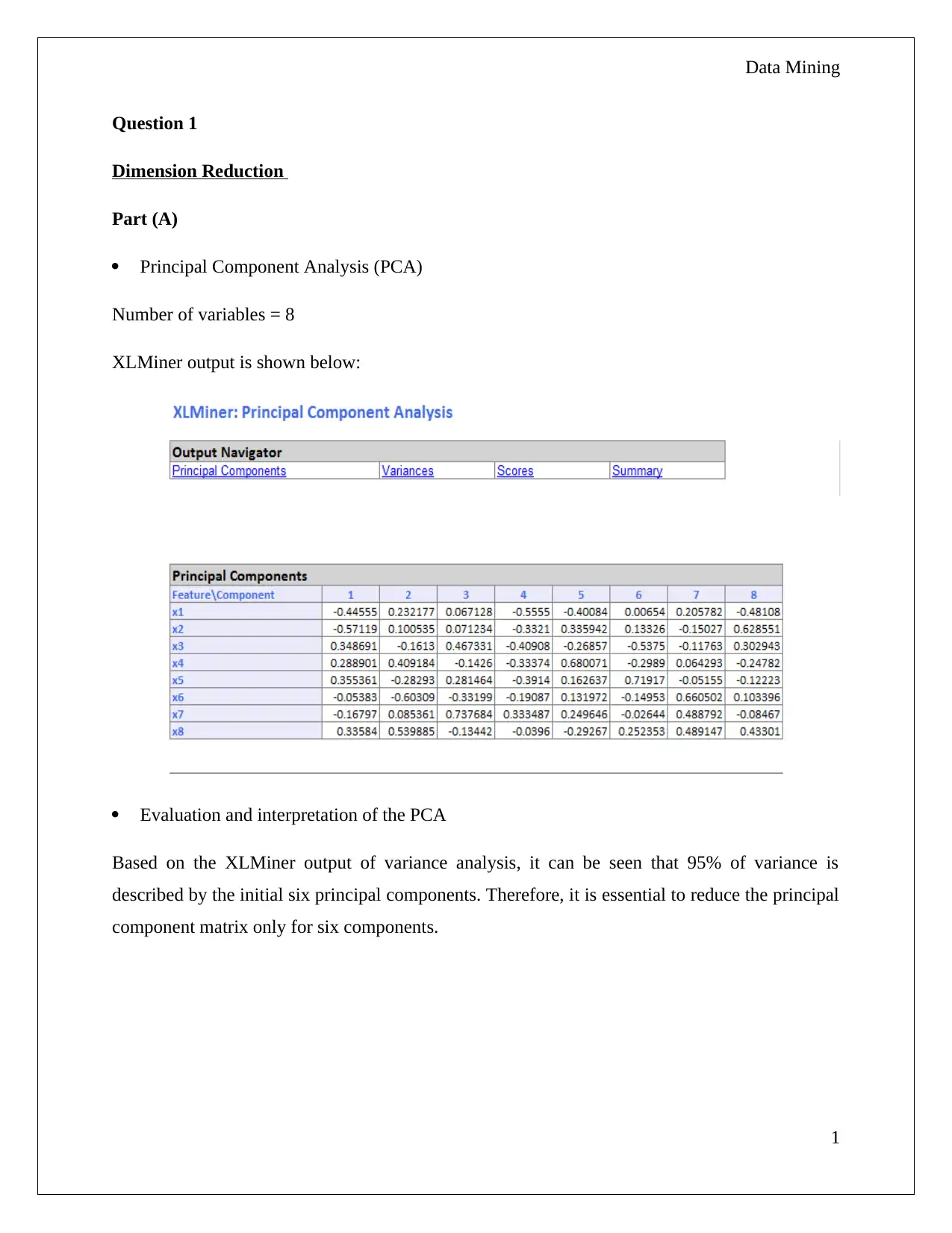
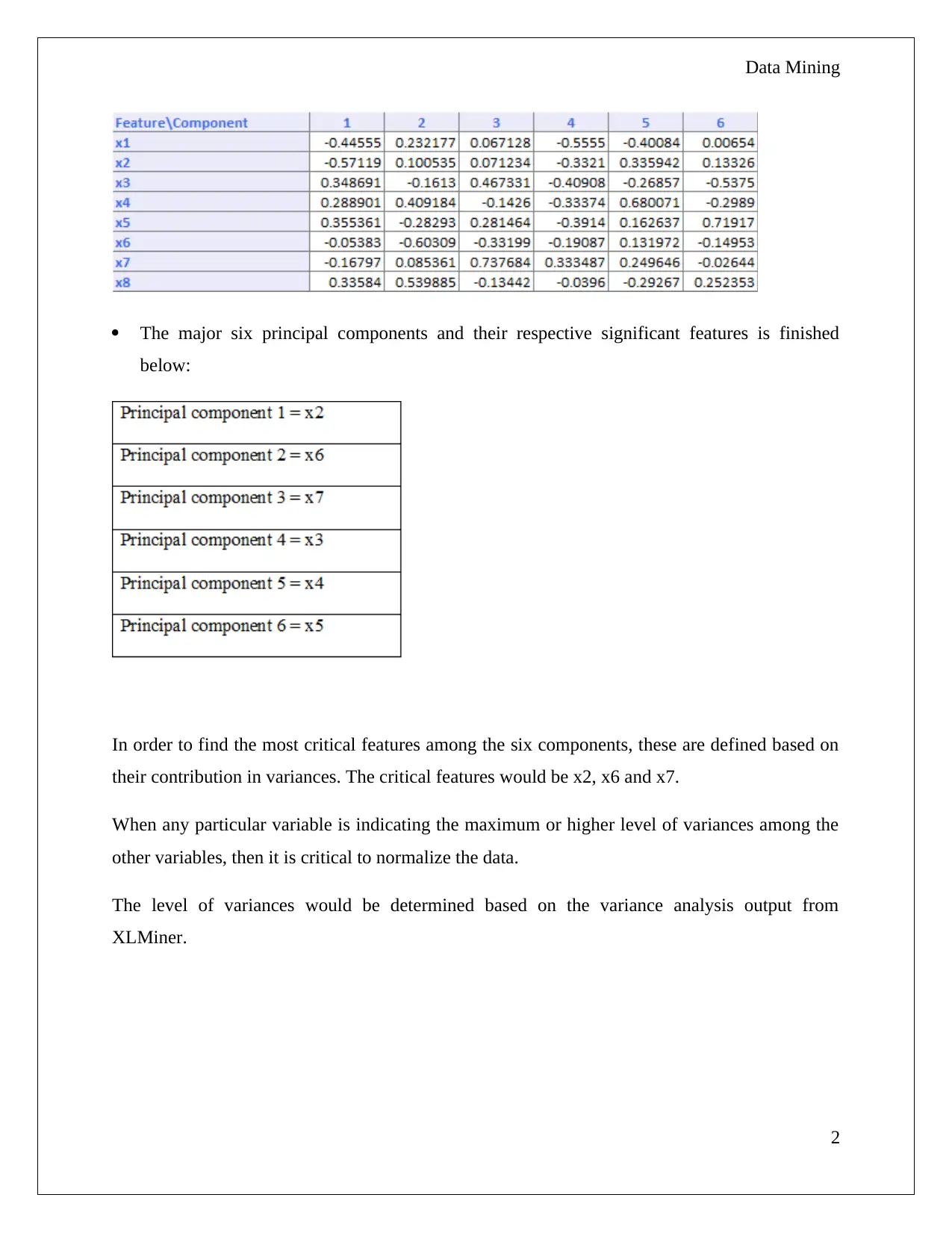
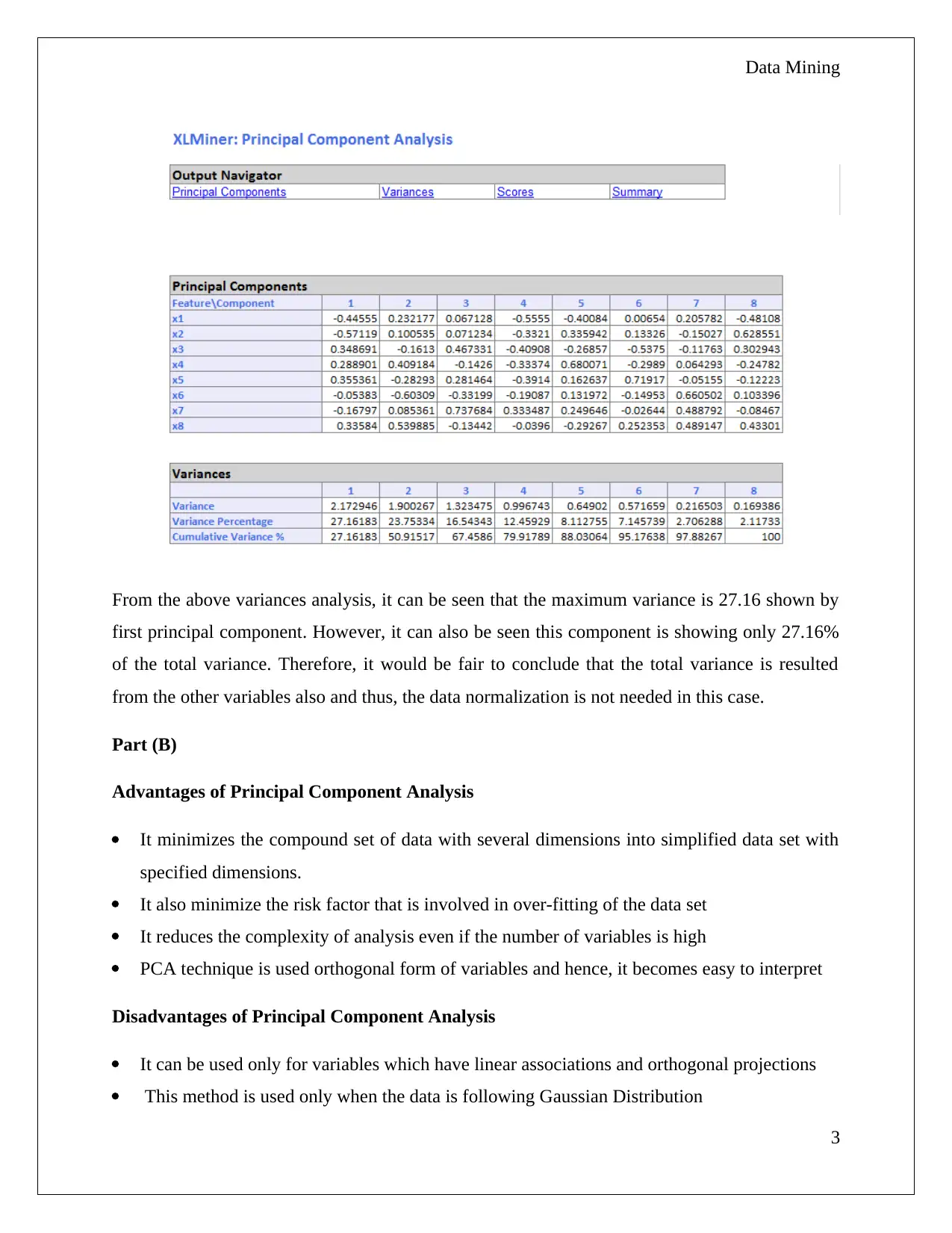
This data mining assignment focuses on two key areas: Principal Component Analysis (PCA) and the Naive Bayes Classifier. The PCA section involves evaluating and interpreting the results of a PCA analysis performed using XLMiner, identifying critical features, and discussing the advantages and disadvantages of the PCA method. The Naive Bayes section uses a dataset of Universal Bank customers to calculate probabilities related to loan acceptance based on factors like credit card ownership and online banking usage. The assignment requires creating pivot tables, calculating probabilities, and interpreting the results to determine the likelihood of loan acceptance under different conditions. The student is asked to analyze the data and draw conclusions about the factors influencing loan acceptance.





1 out of 8
Related Documents
![Data Mining and Visualization Business Case Analysis Solution - [Date]](/_next/image/?url=https%3A%2F%2Fdesklib.com%2Fmedia%2Fimages%2Fa4c62573bfd04fc8a6d2208b43ae0344.jpg&w=256&q=75)





Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Copyright © 2020–2026 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.