Data Mining Techniques: Association and Clustering Analysis Project
VerifiedAdded on 2020/05/11
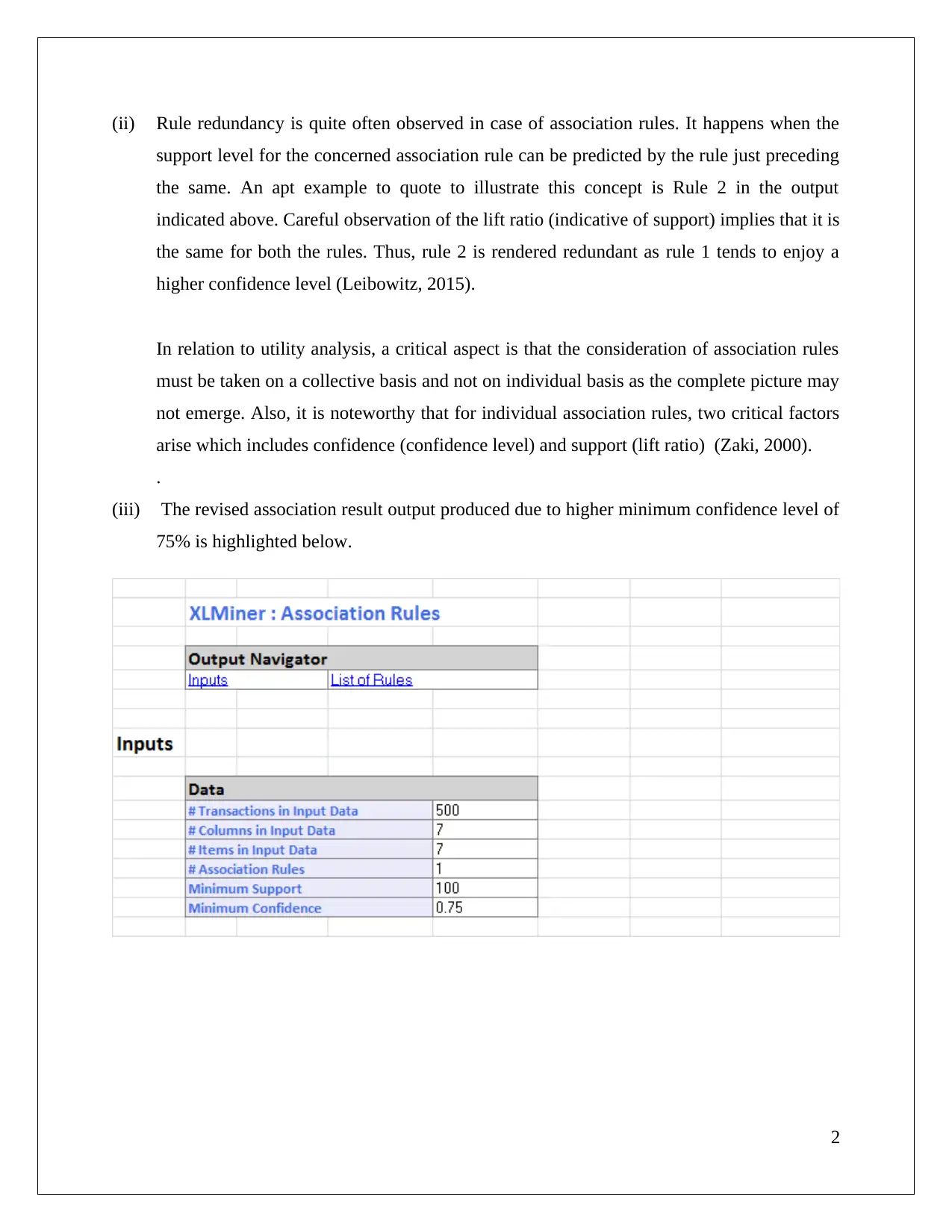
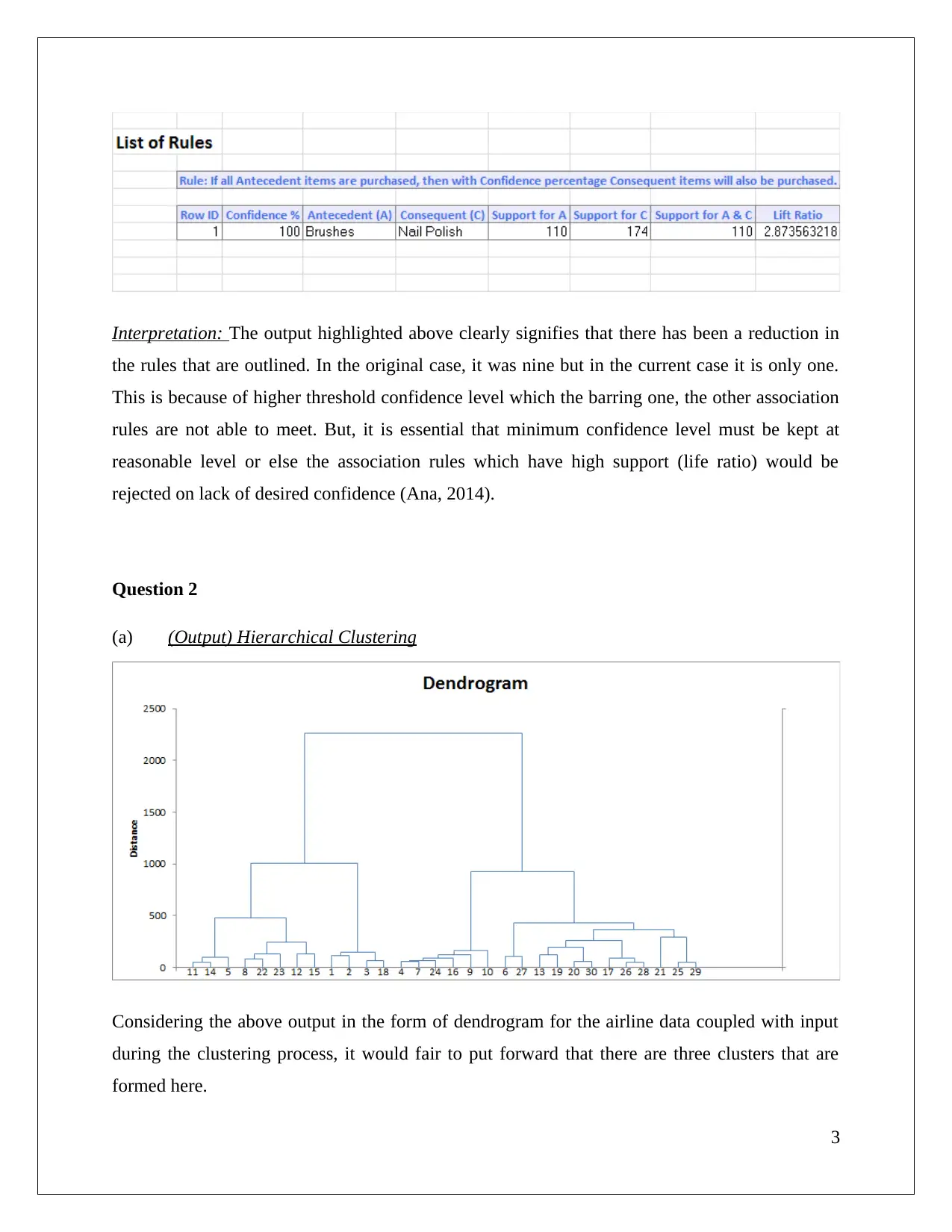
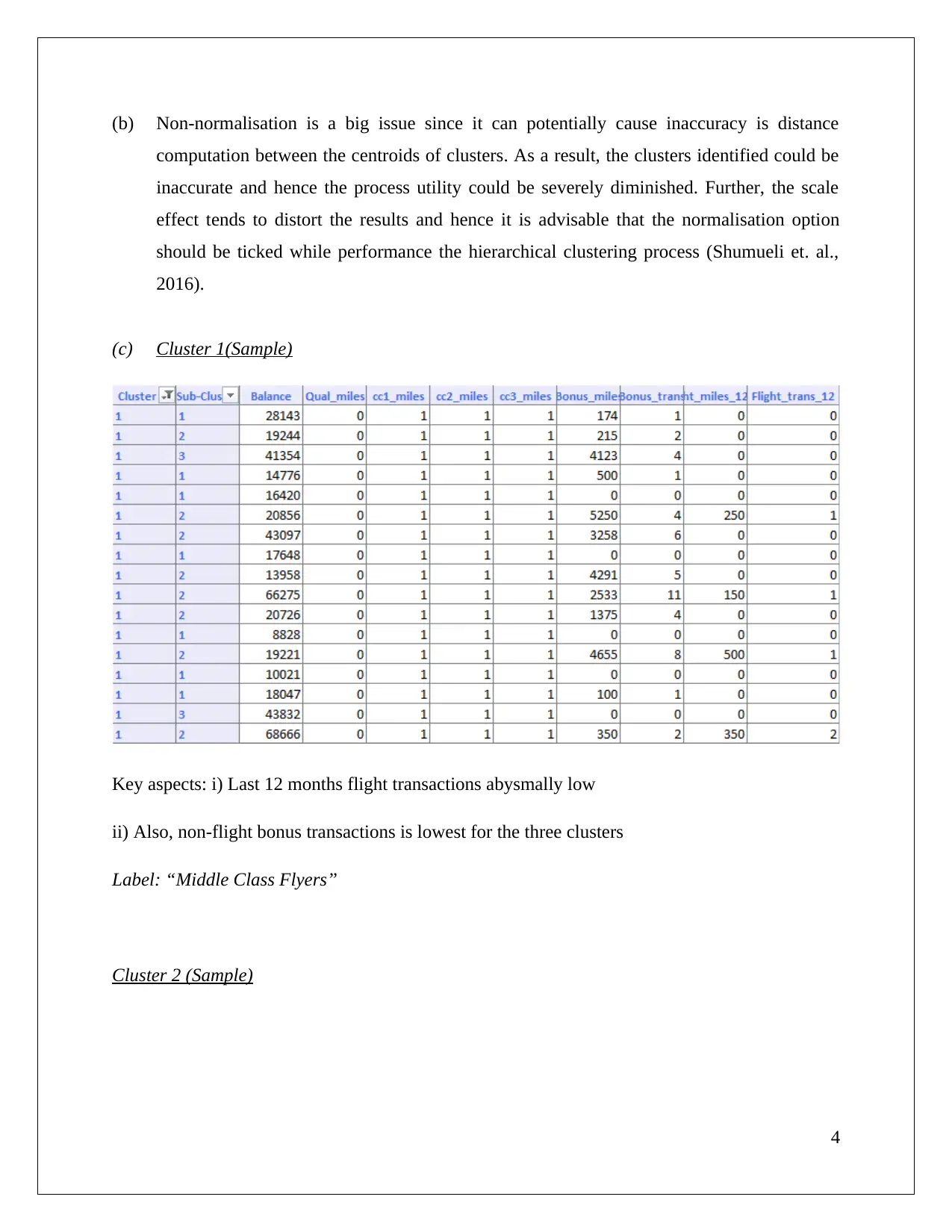
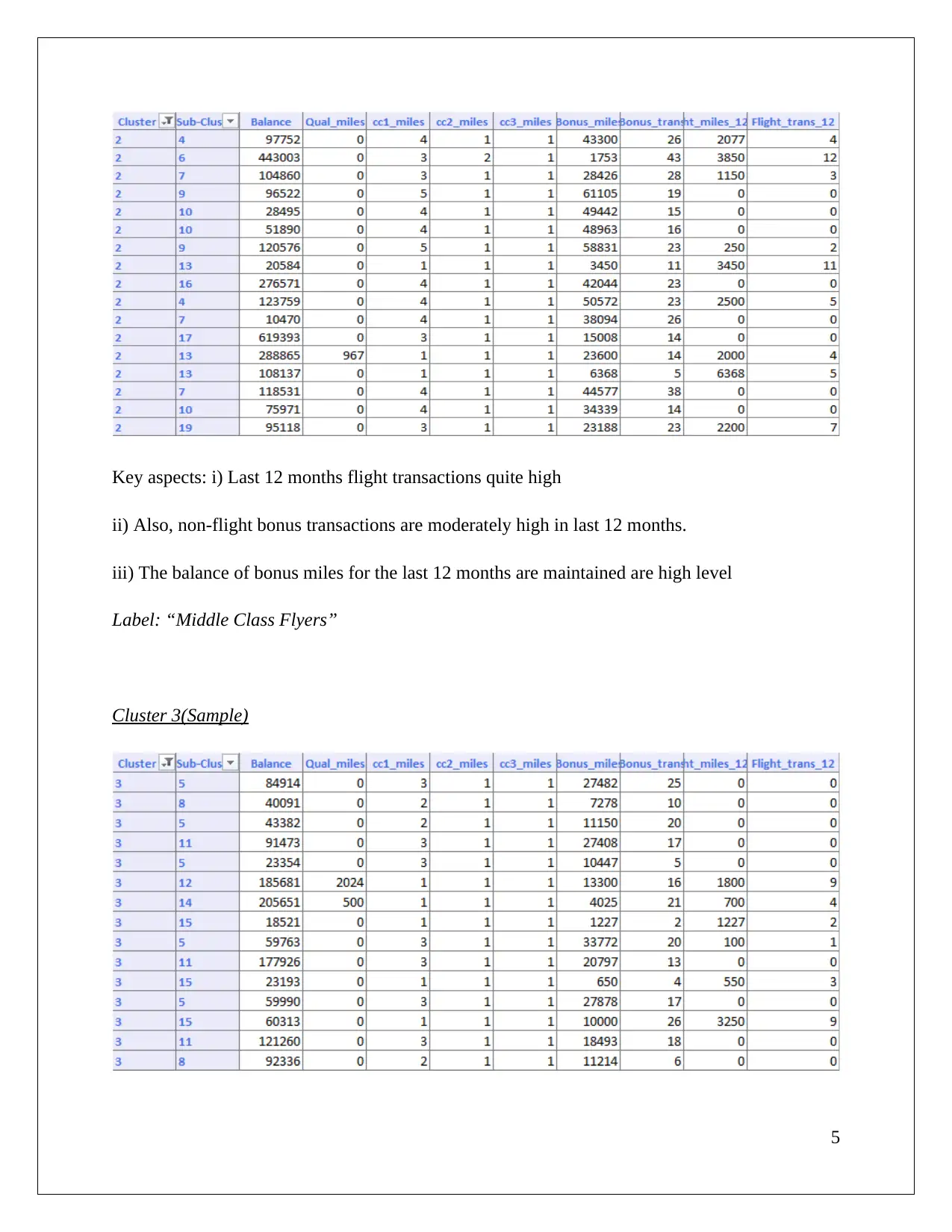
|8
|876
|157
Homework Assignment
AI Summary
The homework assignment explores the use of association rules within data mining. It discusses the identification and redundancy of these rules based on confidence levels and lift ratios, emphasizing the importance of collective utility analysis over individual rule assessment. The task also involves examining hierarchical and k-means clustering methods applied to airline data, highlighting discrepancies between cluster formations and discussing the impact of non-normalization on distance computations. Key aspects include evaluating clusters based on flight transactions and bonus miles, leading to labels like 'Middle Class Flyers' and 'Non-frequent Flyers'. References from literature support the methodologies discussed.




1 out of 8
Related Documents


![Data Mining Assignment for [Course Name] - Analysis and Findings](/_next/image/?url=https%3A%2F%2Fdesklib.com%2Fmedia%2Fimages%2Fml%2F8b9bb9b0c77d435887f2ac7476b3a62f.jpg&w=256&q=75)



Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Copyright © 2020–2026 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.