Data Mining Assignment: Association Rules, Clustering Analysis Report
VerifiedAdded on 2020/03/16
|8
|936
|155
Homework Assignment
AI Summary
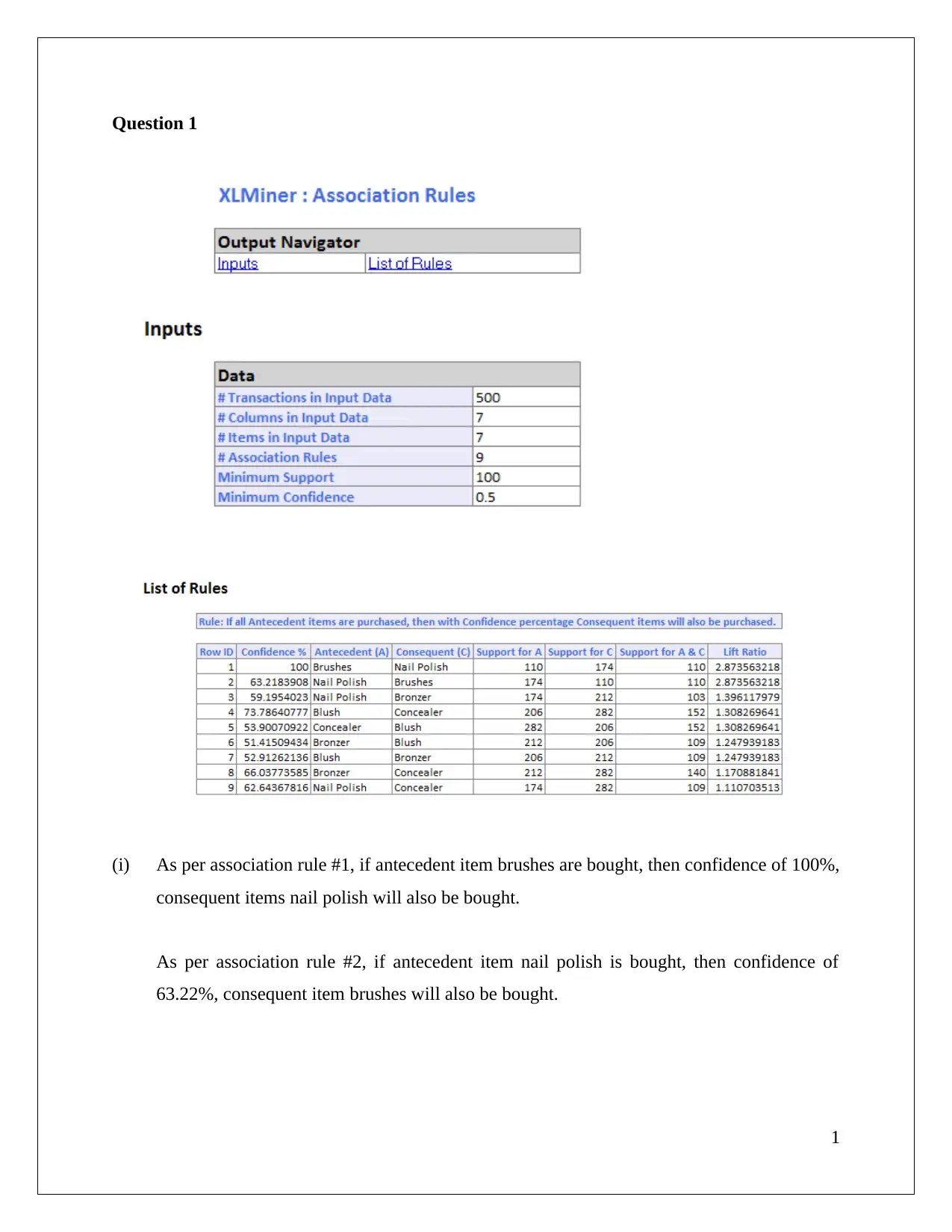
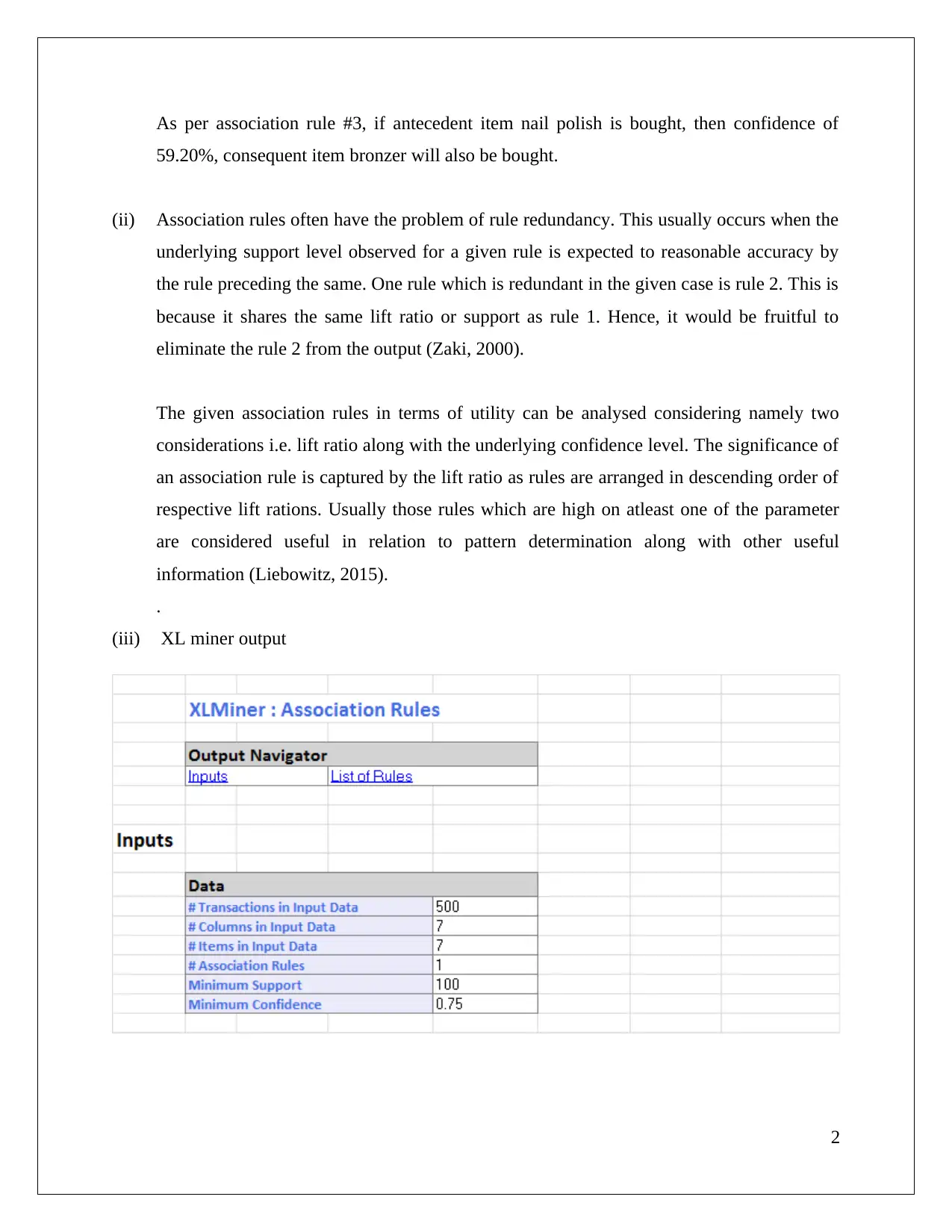
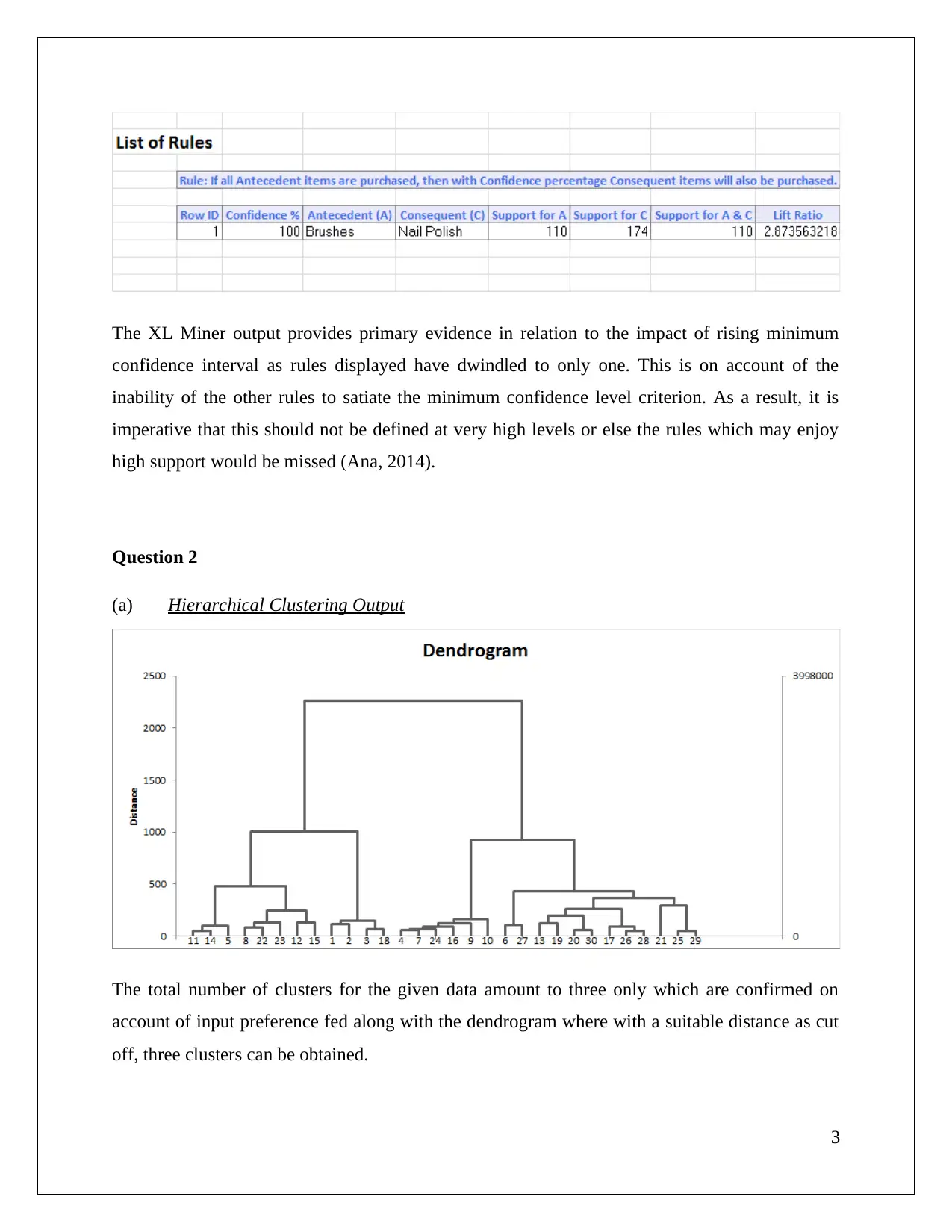
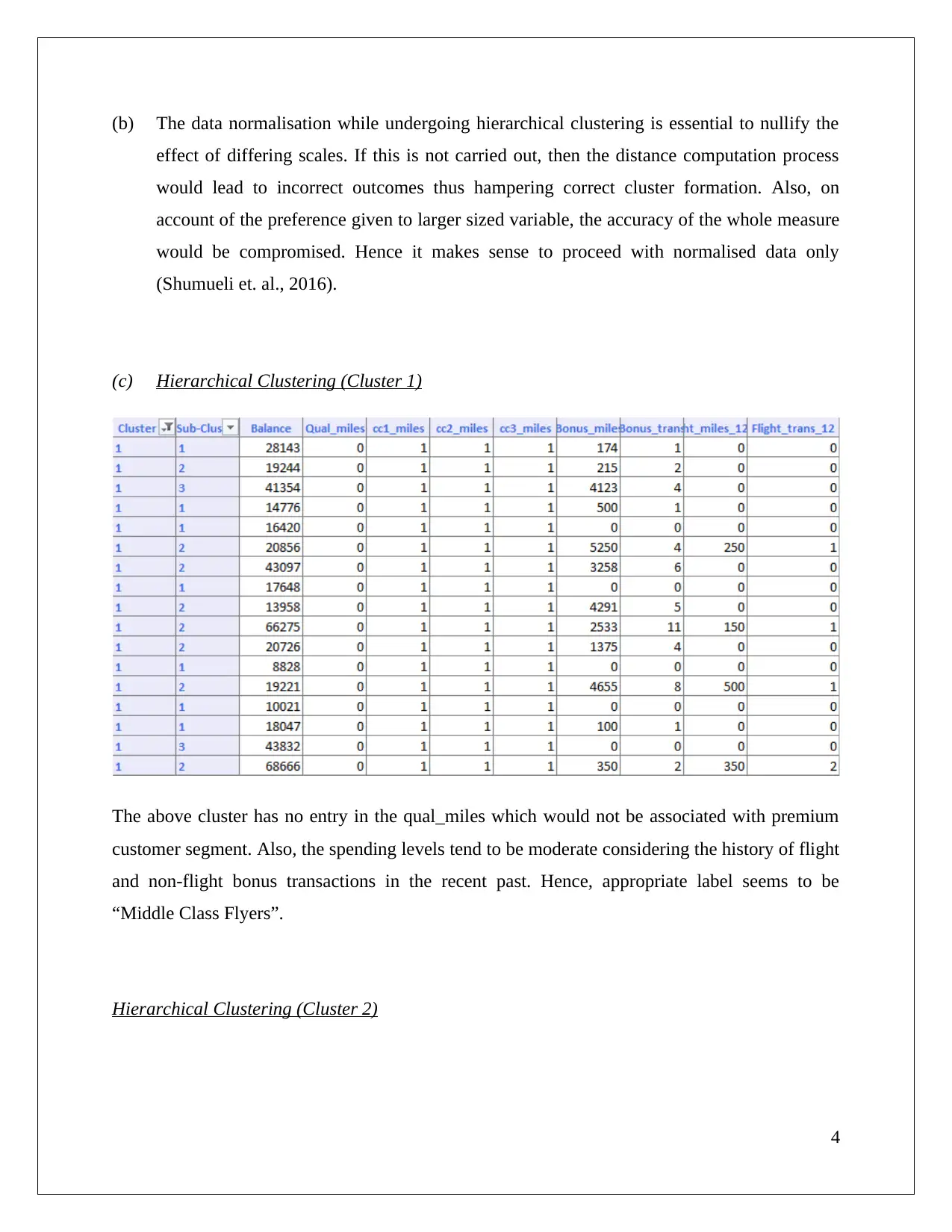
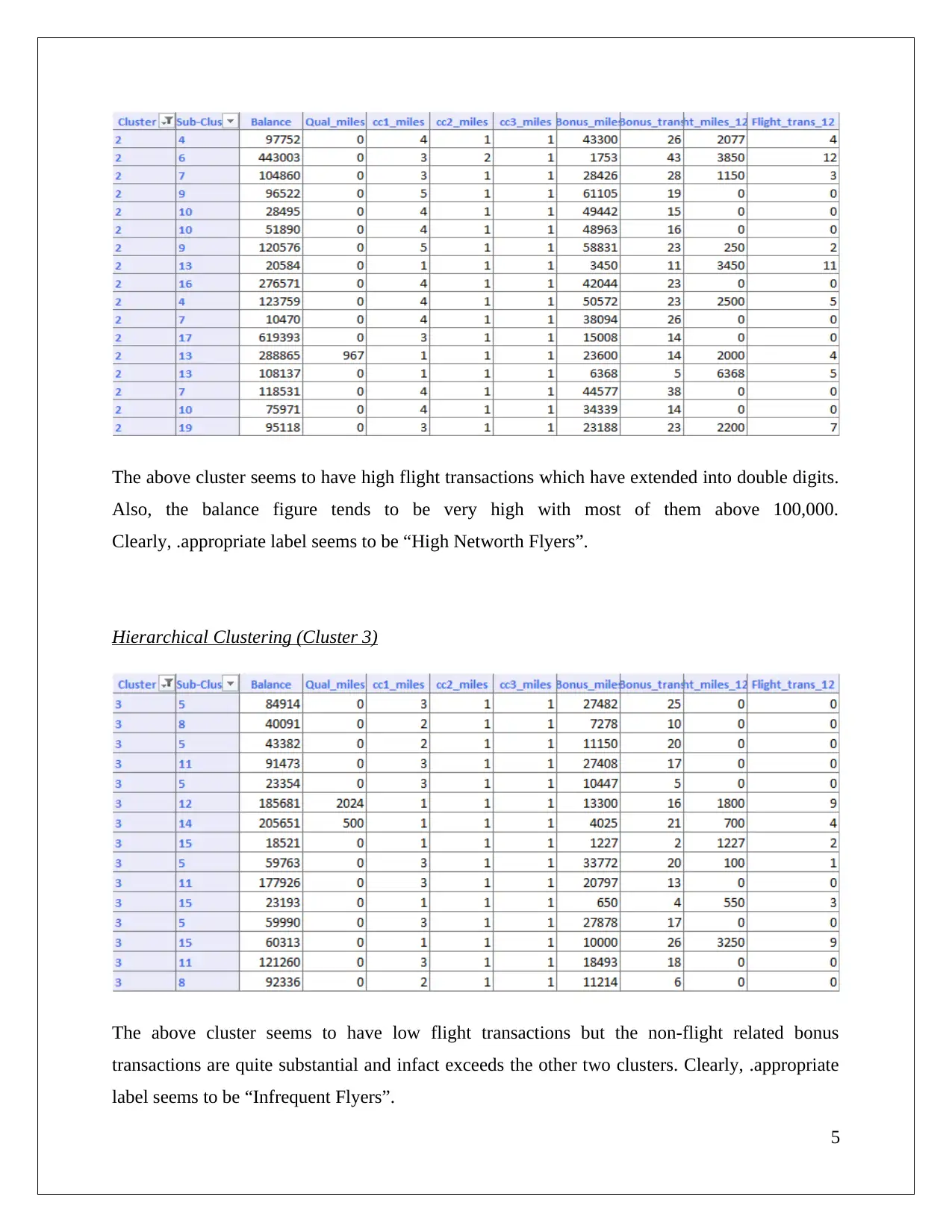
This data mining assignment analyzes association rules and clustering techniques using XL Miner, hierarchical clustering, and K-means clustering. The solution begins by examining association rules, identifying rule redundancy, and evaluating the impact of the minimum confidence interval. It then delves into hierarchical clustering, explaining the importance of data normalization and labeling clusters based on customer characteristics such as flight transactions, balance, and bonus transactions, categorizing customers into "Middle Class Flyers", "High Networth Flyers", and "Infrequent Flyers". A comparison is made with K-means clustering, highlighting pattern differences and labeling clusters accordingly. The assignment emphasizes the importance of matching clusters and understanding the key attributes for customer segmentation, providing a comprehensive analysis of the data mining methods.



1 out of 8
Related Documents






Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Copyright © 2020–2026 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.