Data Mining Assignment: Analysis of Association Rule and Clustering
VerifiedAdded on 2020/03/16
|12
|1914
|306
Homework Assignment
AI Summary
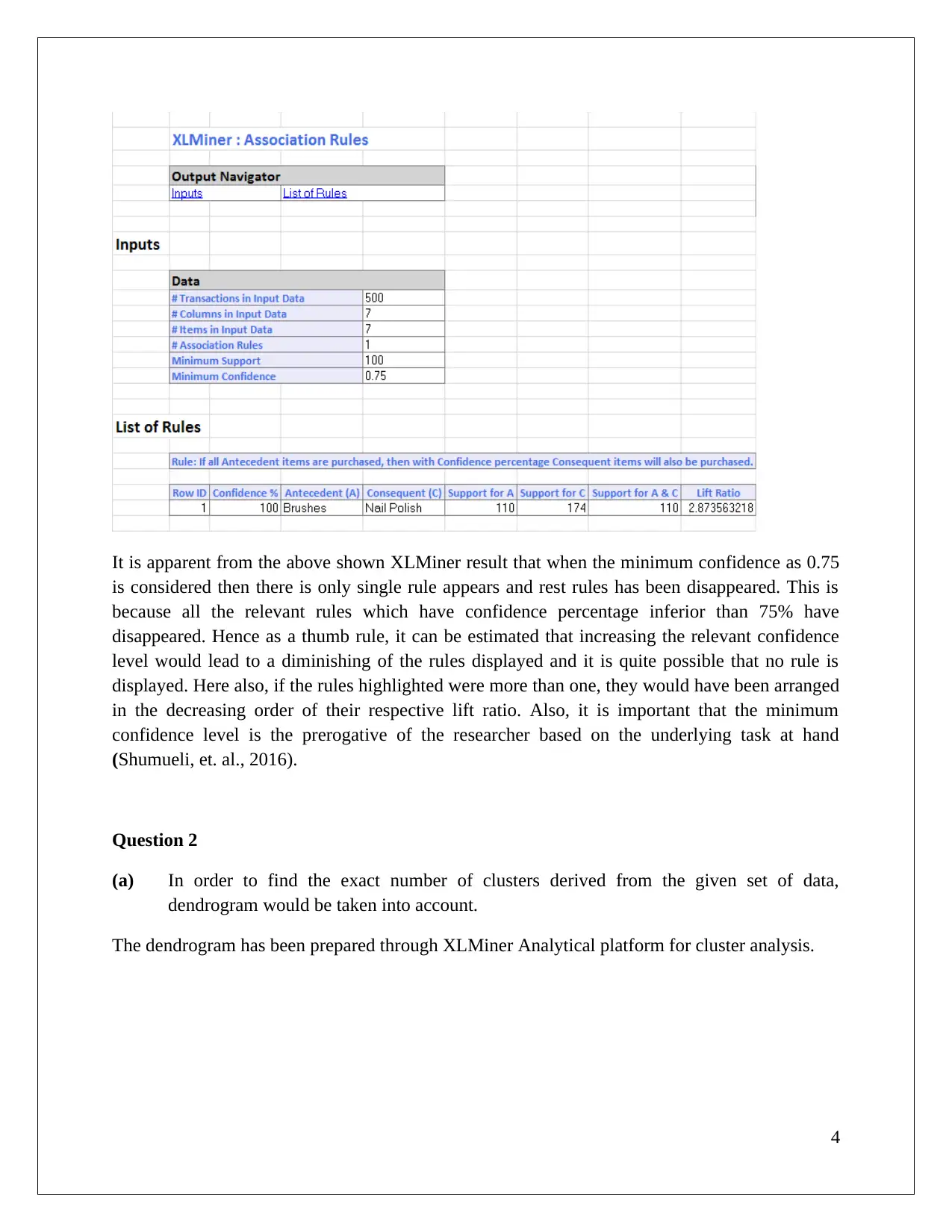
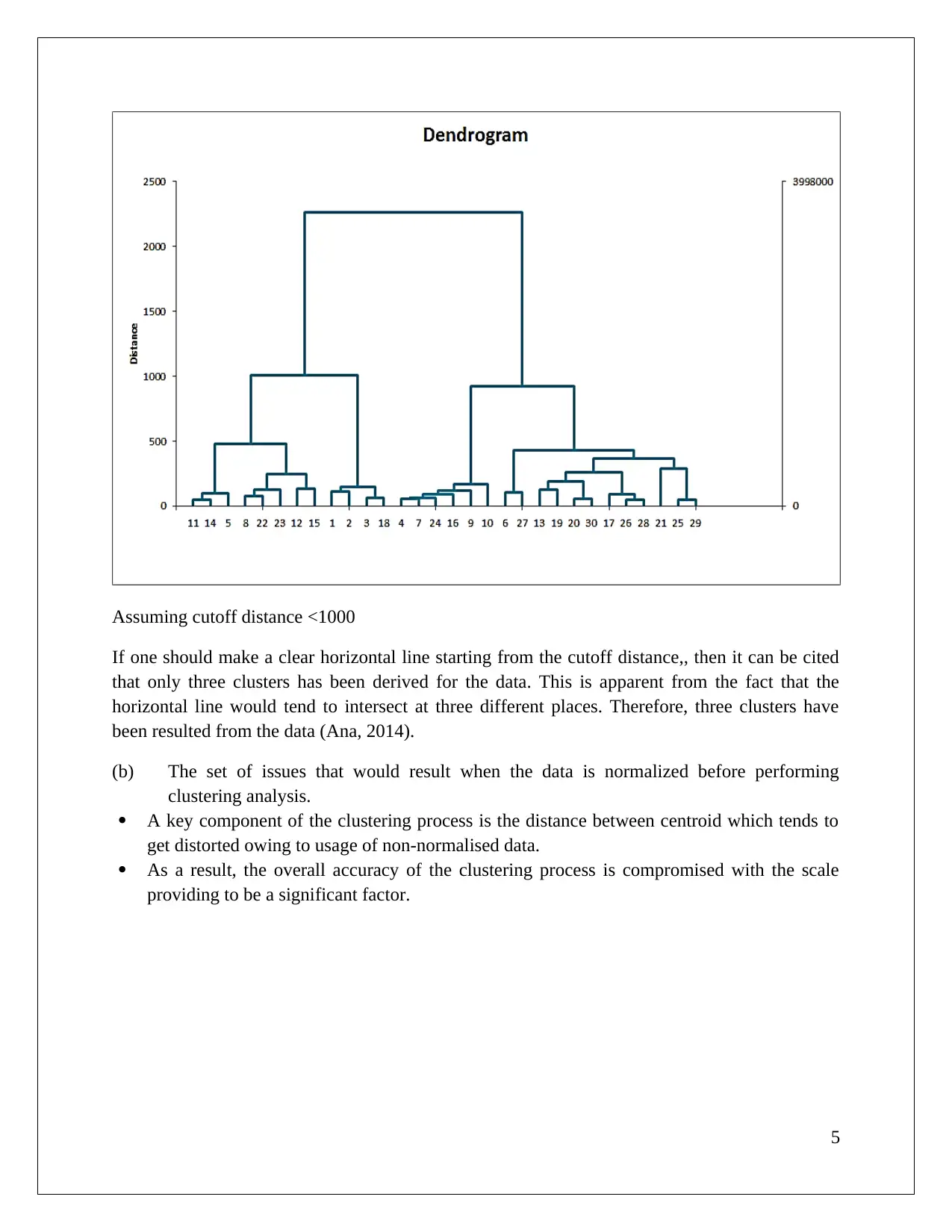
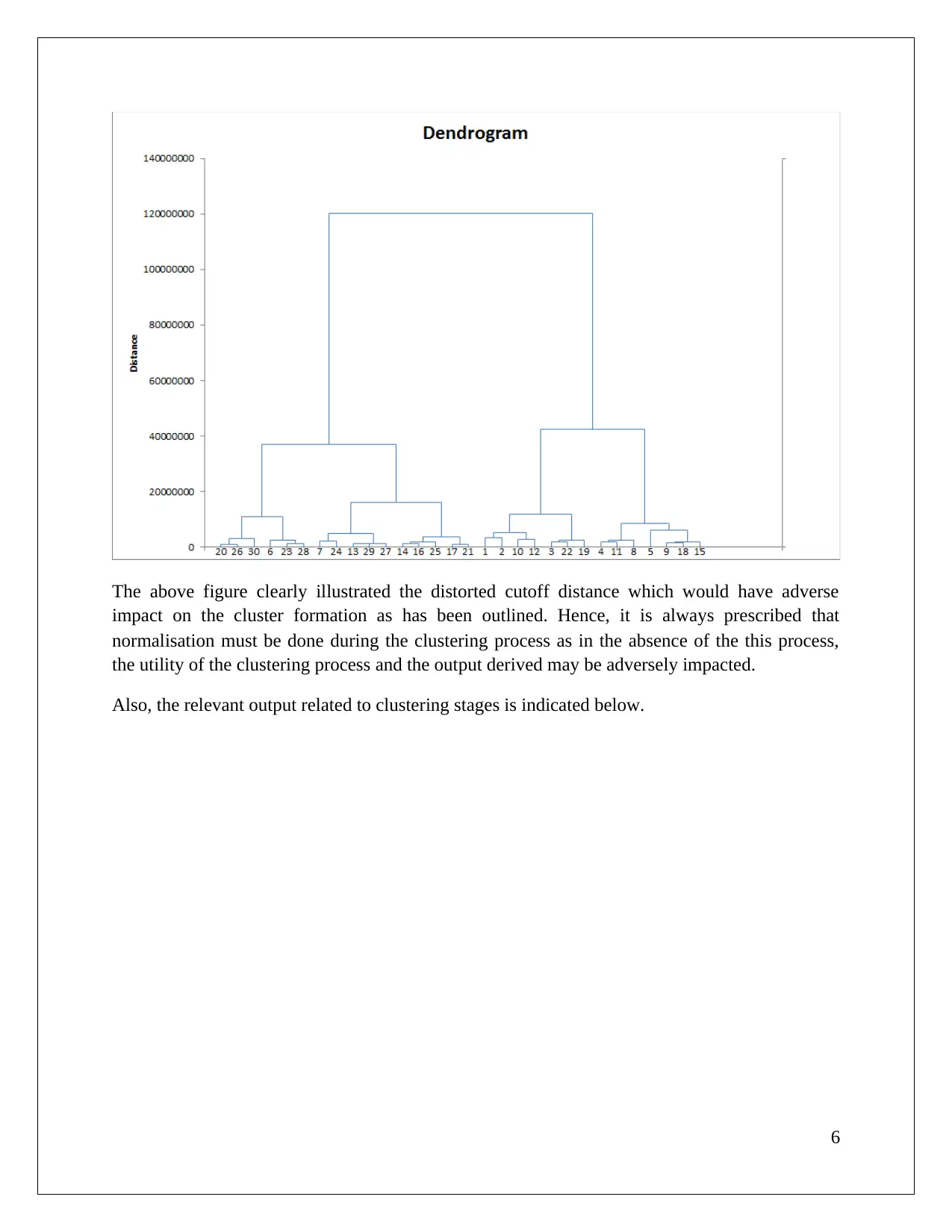
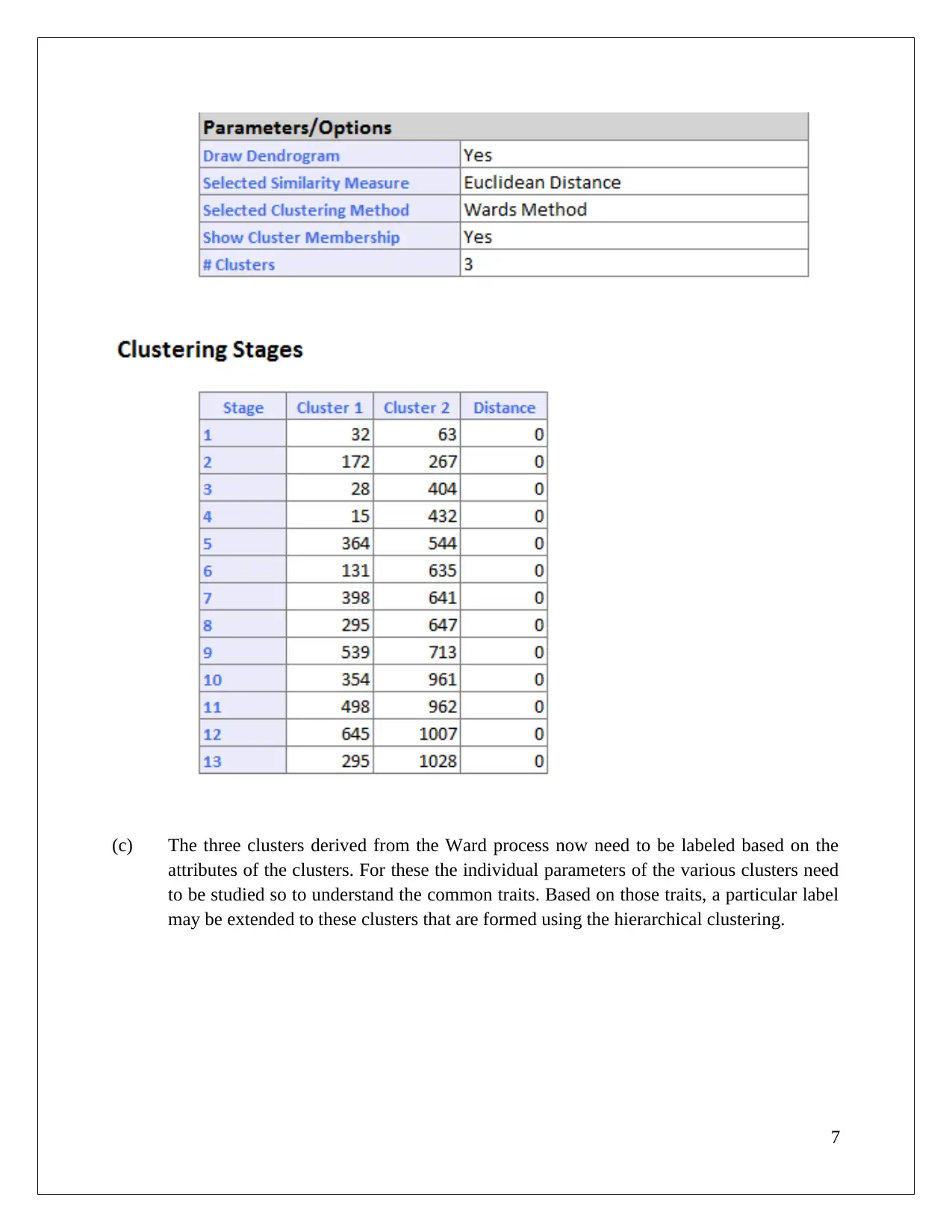
This data mining assignment utilizes the XLMiner analytical platform to explore association rules and clustering techniques. The analysis focuses on a cosmetic dataset, examining association rules with varying confidence levels and identifying redundant rules. The assignment delves into the concepts of lift ratio and confidence level, highlighting their significance in understanding consumer buying behavior. Furthermore, the assignment explores clustering analysis using dendrograms to determine the number of clusters and discusses the impact of data normalization on clustering accuracy. It also compares hierarchical and K-Means clustering methods, labeling clusters based on their attributes and proposing targeted offers to different customer segments. This document, available on Desklib, provides a comprehensive overview of the analysis, including the identification of key customer traits and actionable insights for business decision-making.






1 out of 12
Related Documents






Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Copyright © 2020–2026 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.