Data Mining and Visualization Business Case Analysis Solution - [Date]
VerifiedAdded on 2019/11/08
|9
|716
|138
Homework Assignment
AI Summary
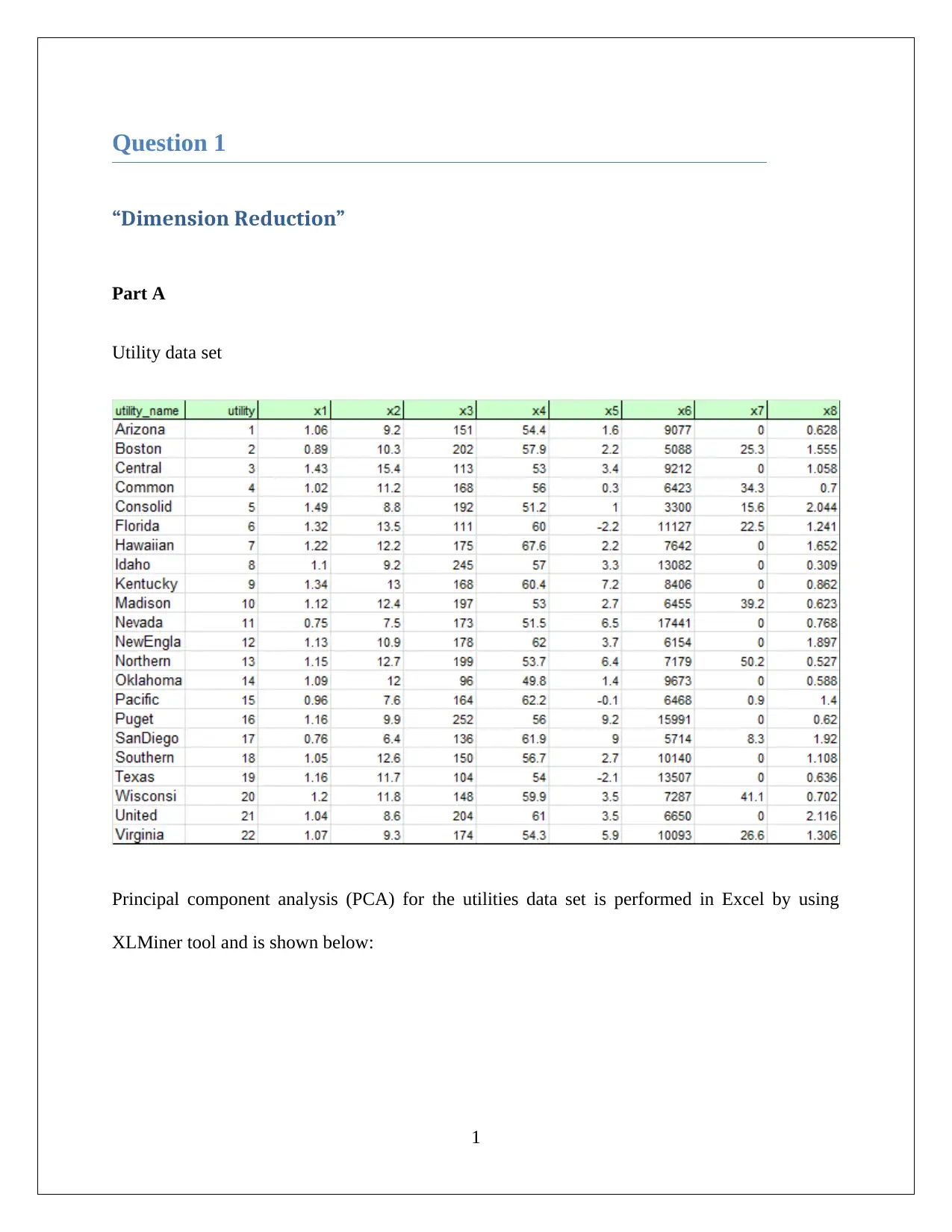
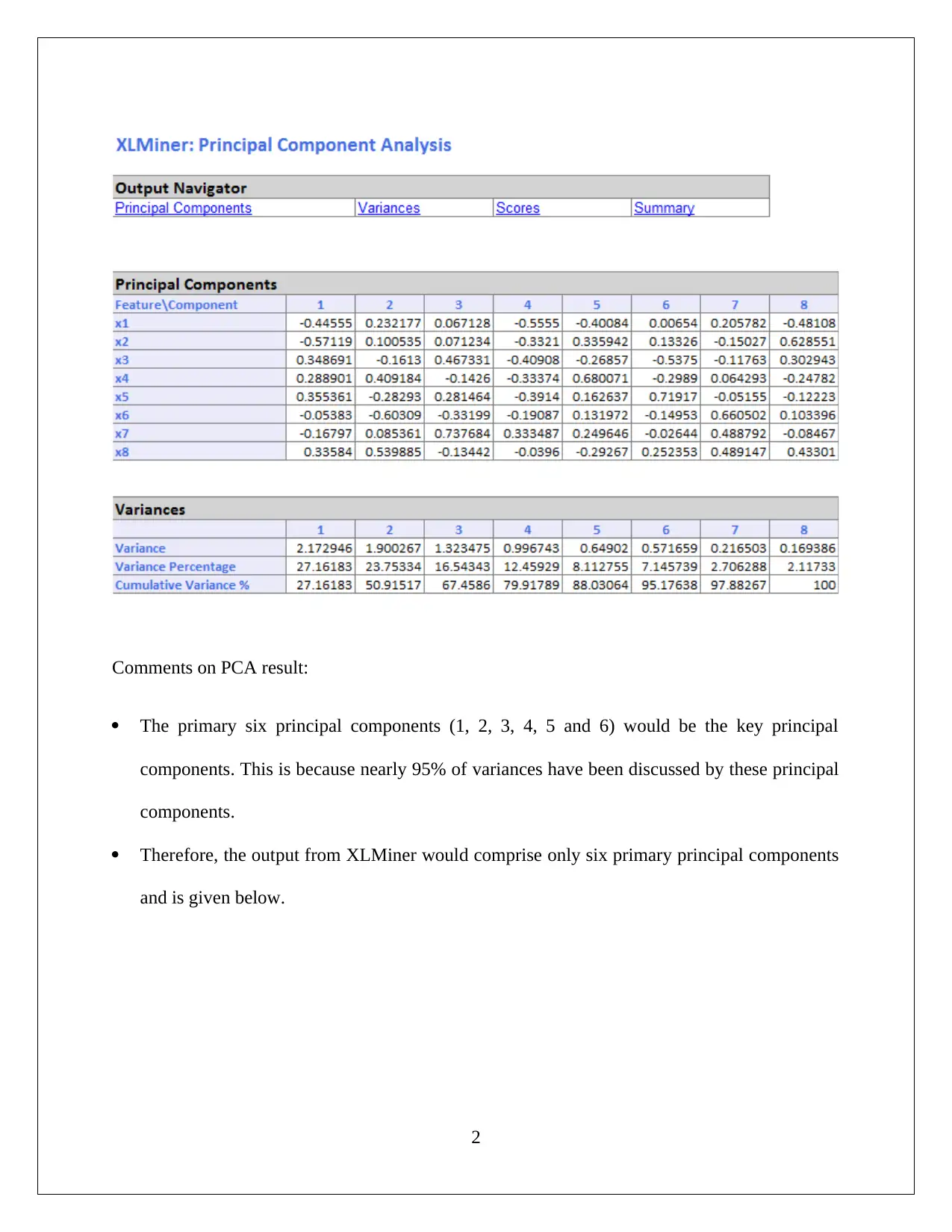
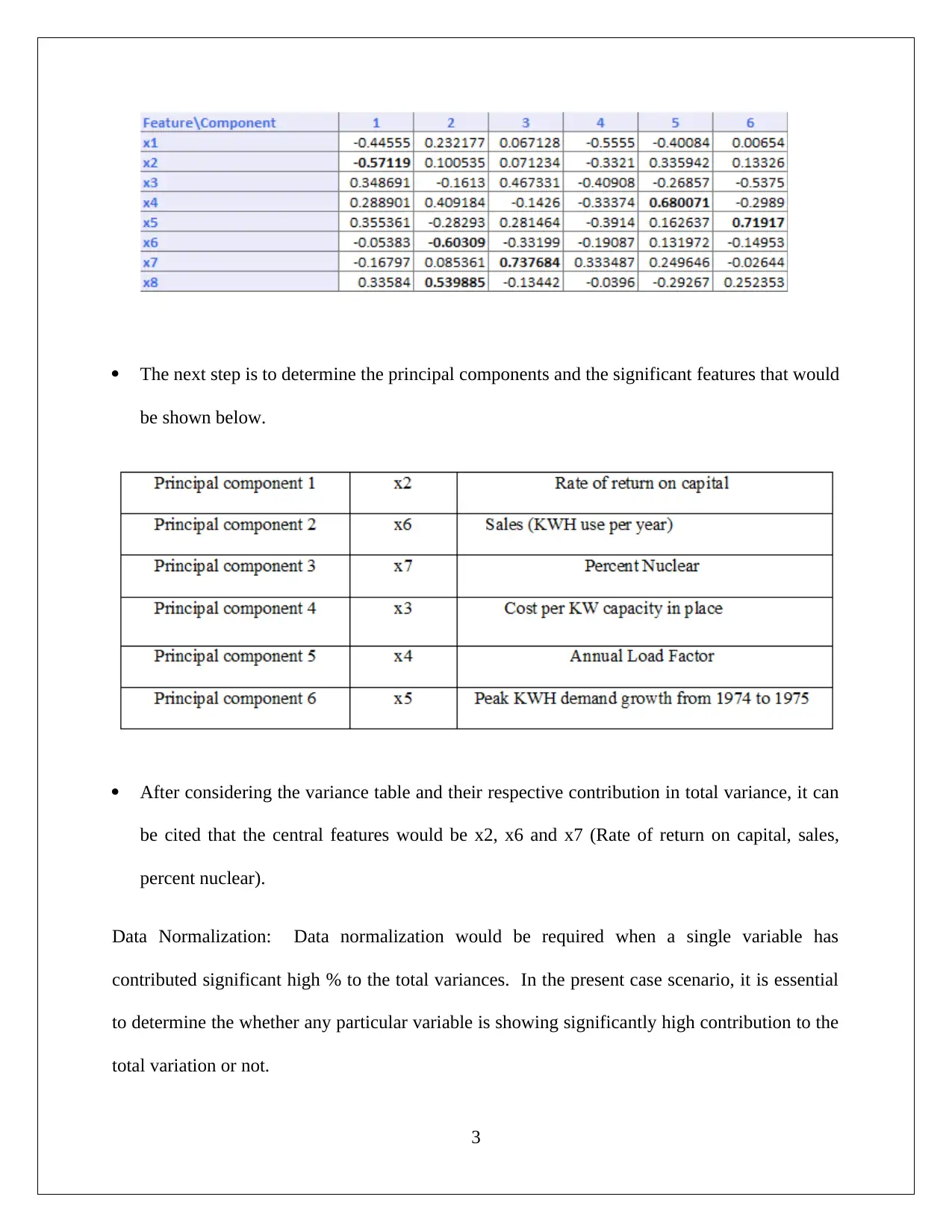
This assignment solution provides a detailed analysis of a business case in Data Mining and Visualization. It covers two main questions: the first focuses on Dimension Reduction using Principal Component Analysis (PCA) applied to a utilities dataset, including comments on PCA results, identification of key principal components, and the need for data normalization. The second question explores the Naive Bayes Classifier, involving pivot table analysis with online banking, credit card usage, and personal loan applications. The solution includes probability calculations, the proportion of credit card holders among loan acceptors, and the application of the Naive Bayes Probability. The conclusion highlights how online service usage and credit card ownership positively influence loan application success. The solution utilizes tools like XLMiner for PCA and pivot tables for data analysis.






1 out of 9
Related Documents






Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Copyright © 2020–2026 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.