Data Mining Business Case Analysis
VerifiedAdded on 2020/03/16
|10
|1041
|141
Report
AI Summary
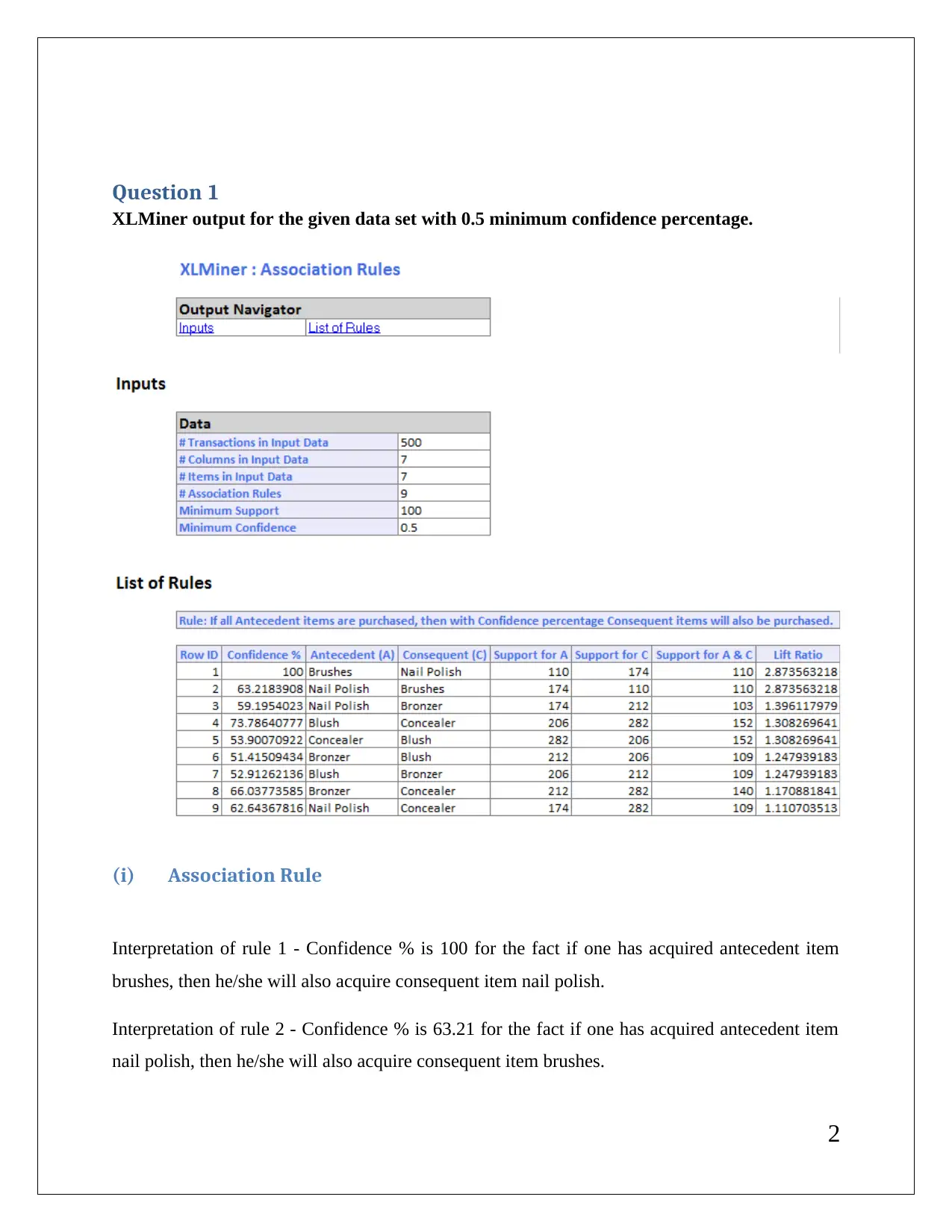
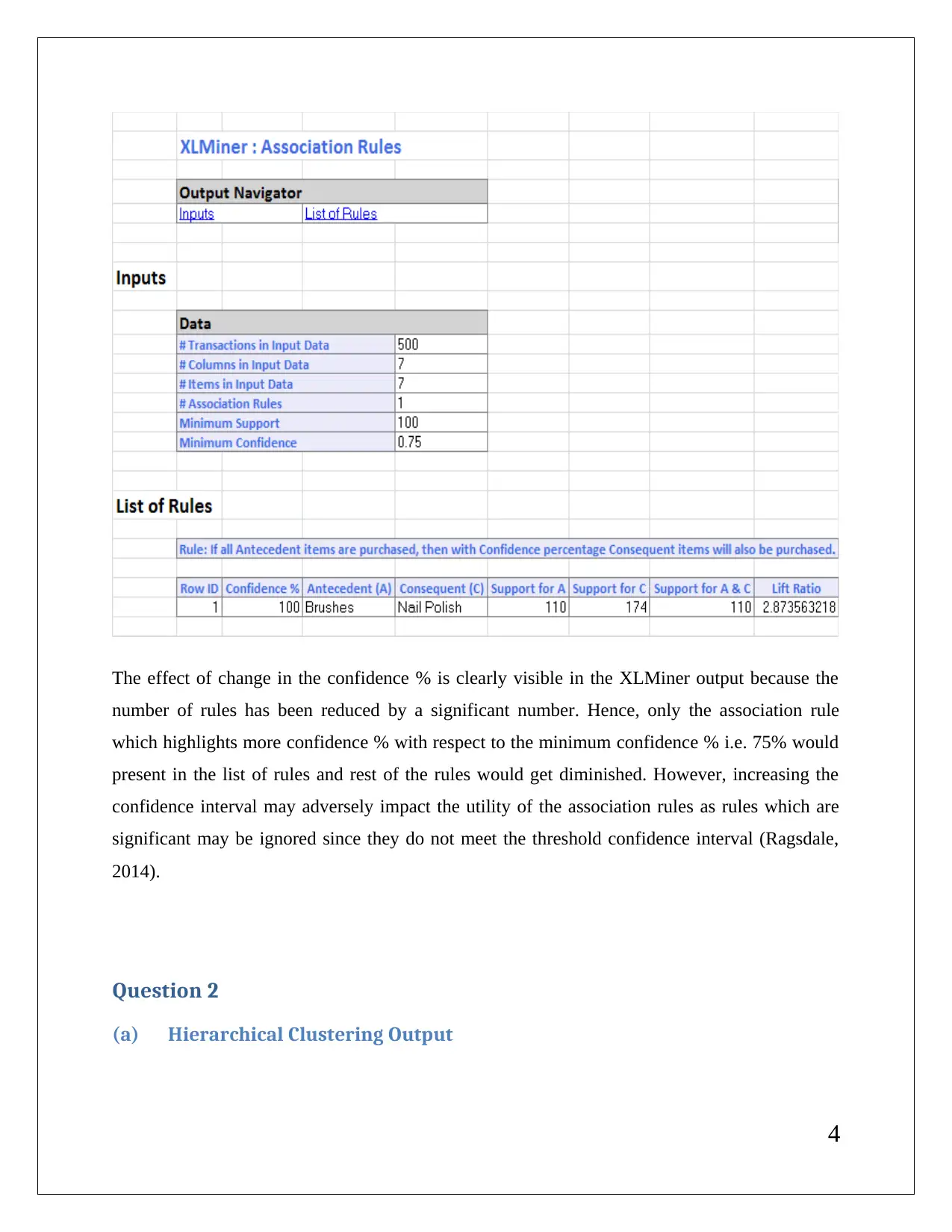
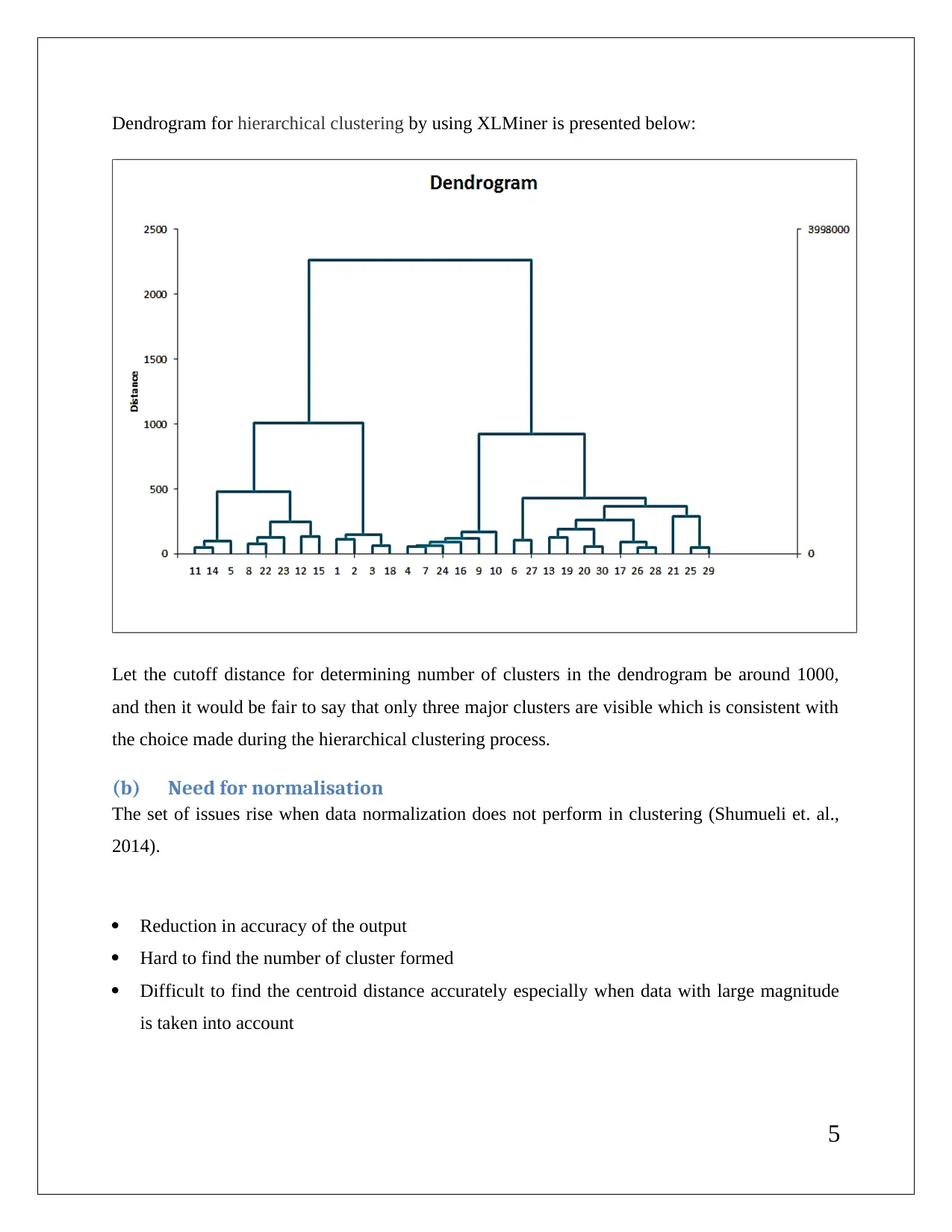
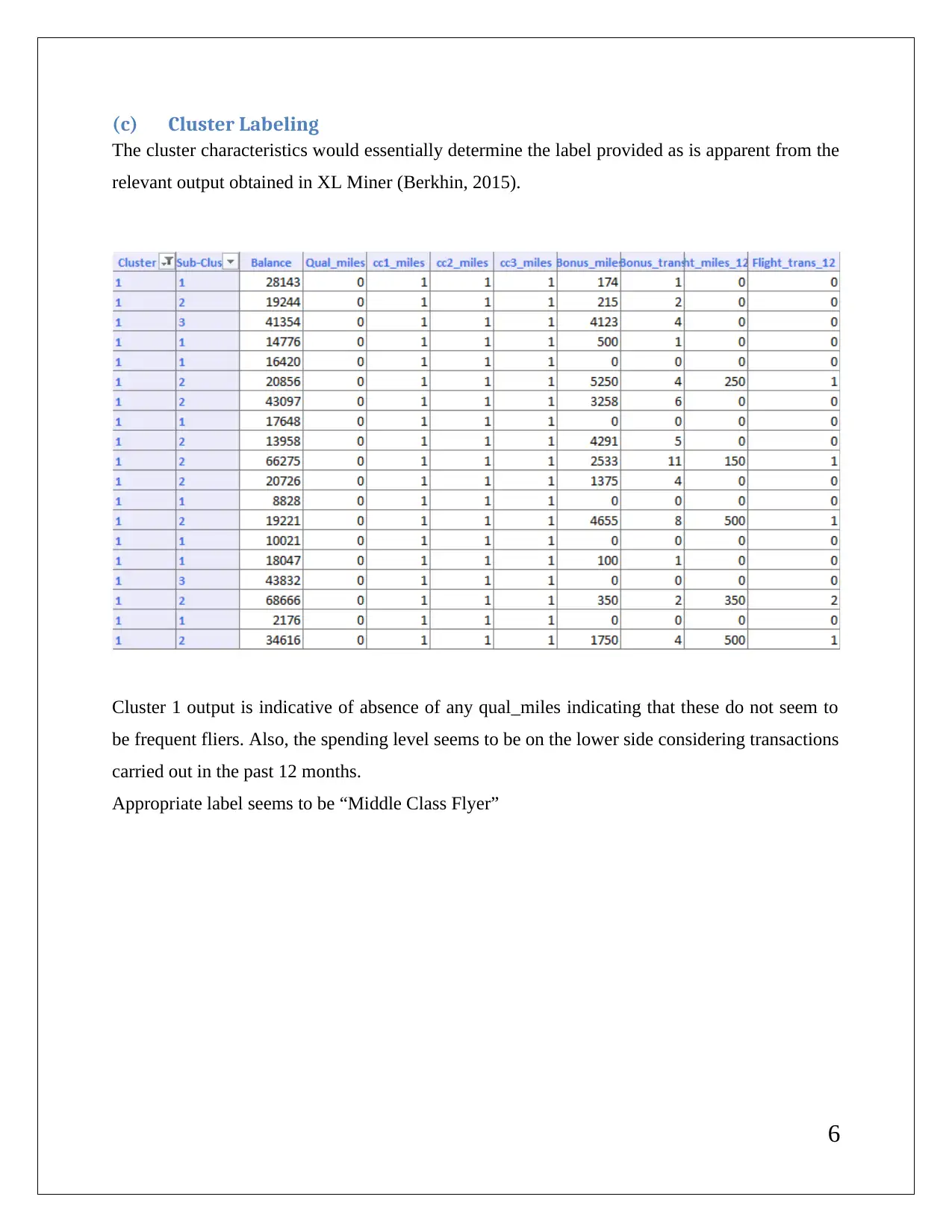
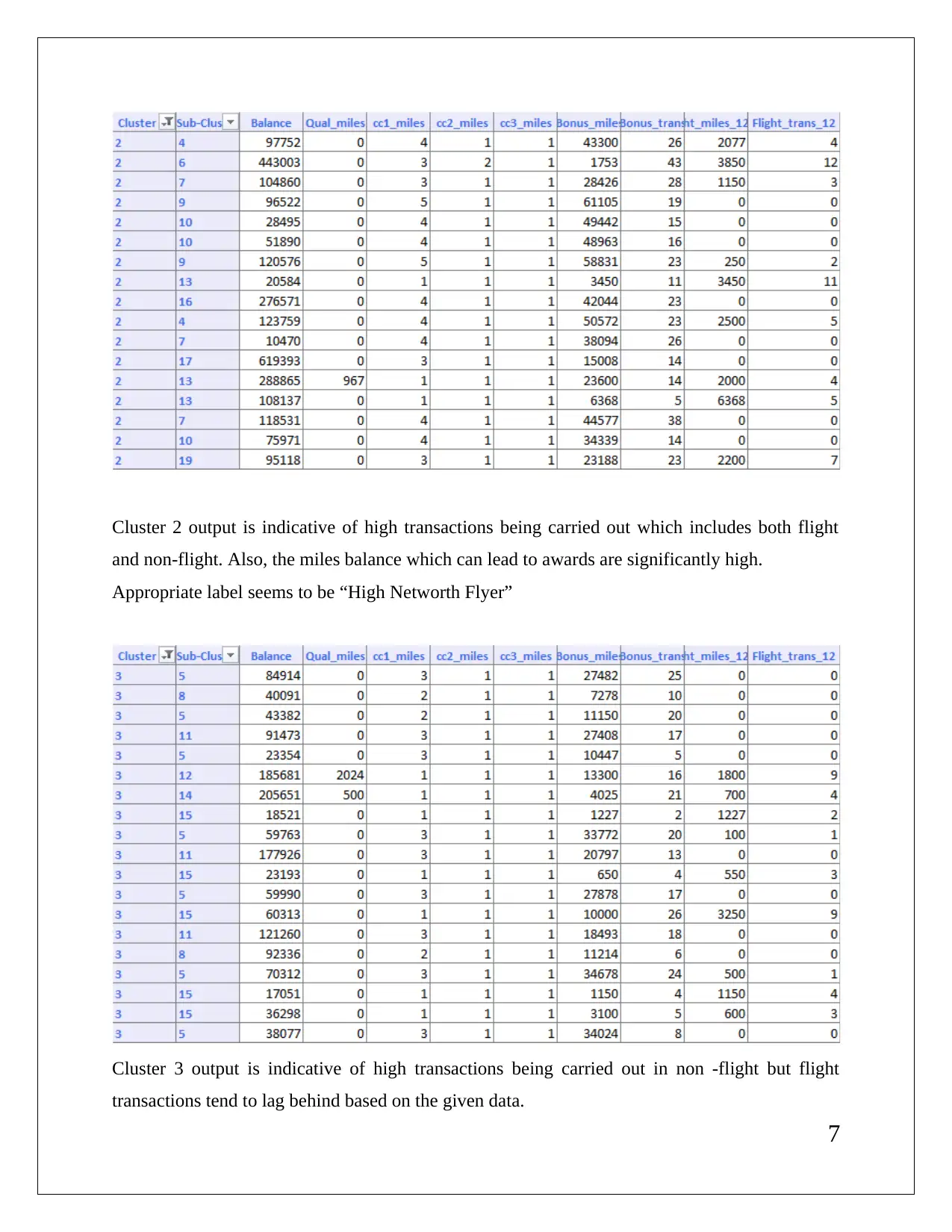
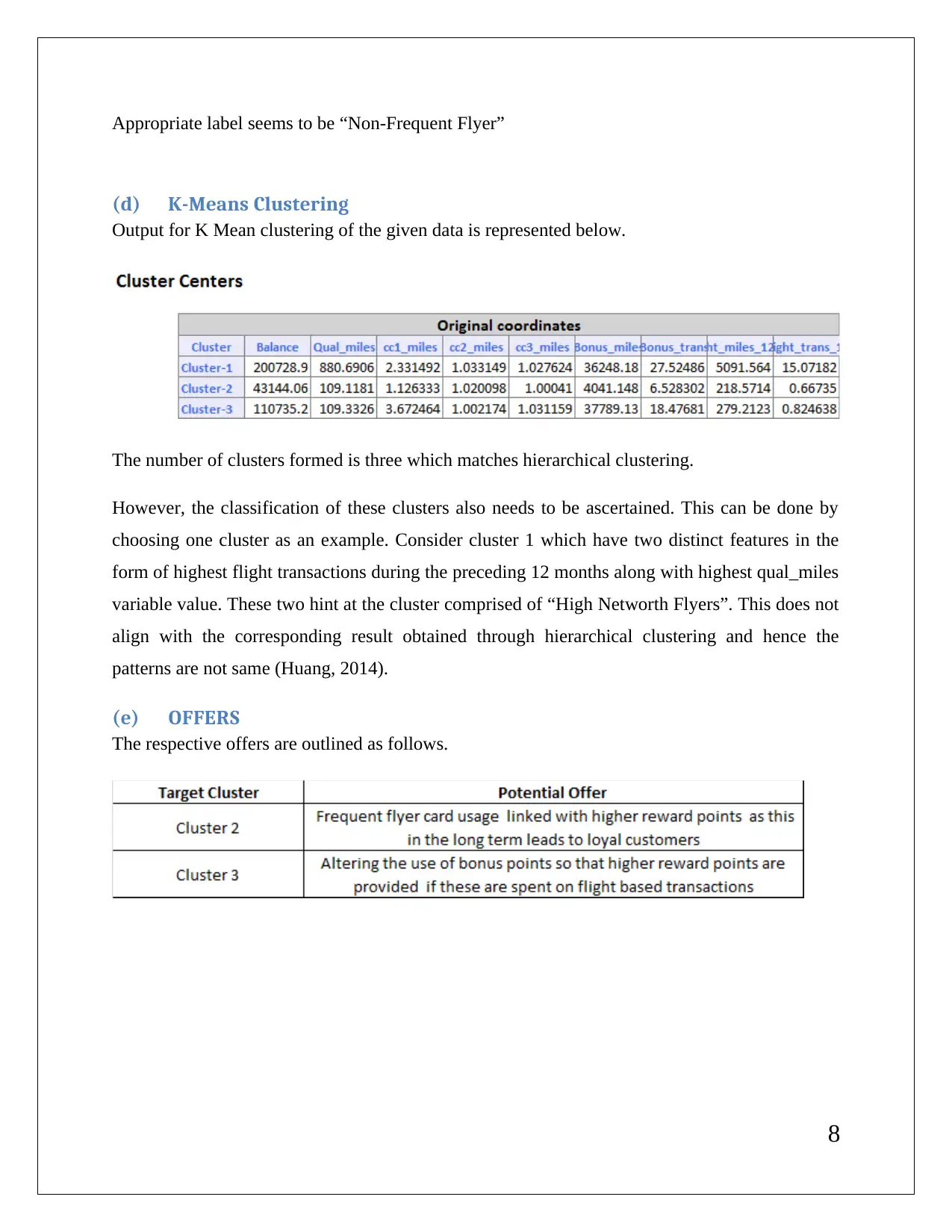
This report presents a comprehensive analysis of data mining techniques applied to a business case. It includes detailed interpretations of association rules, redundancy analysis, and clustering outputs using XLMiner. The report discusses the implications of minimum confidence intervals on rule utility and the necessity of data normalization in clustering. It also provides insights into cluster labeling and the results of K-Means clustering, highlighting the differences in patterns observed. References to relevant literature are included to support the findings.




1 out of 10
Related Documents






Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Copyright © 2020–2026 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.