Data Mining Assignment: Association Rule, Clustering Analysis
VerifiedAdded on 2020/03/16
|11
|1296
|45
Homework Assignment
AI Summary
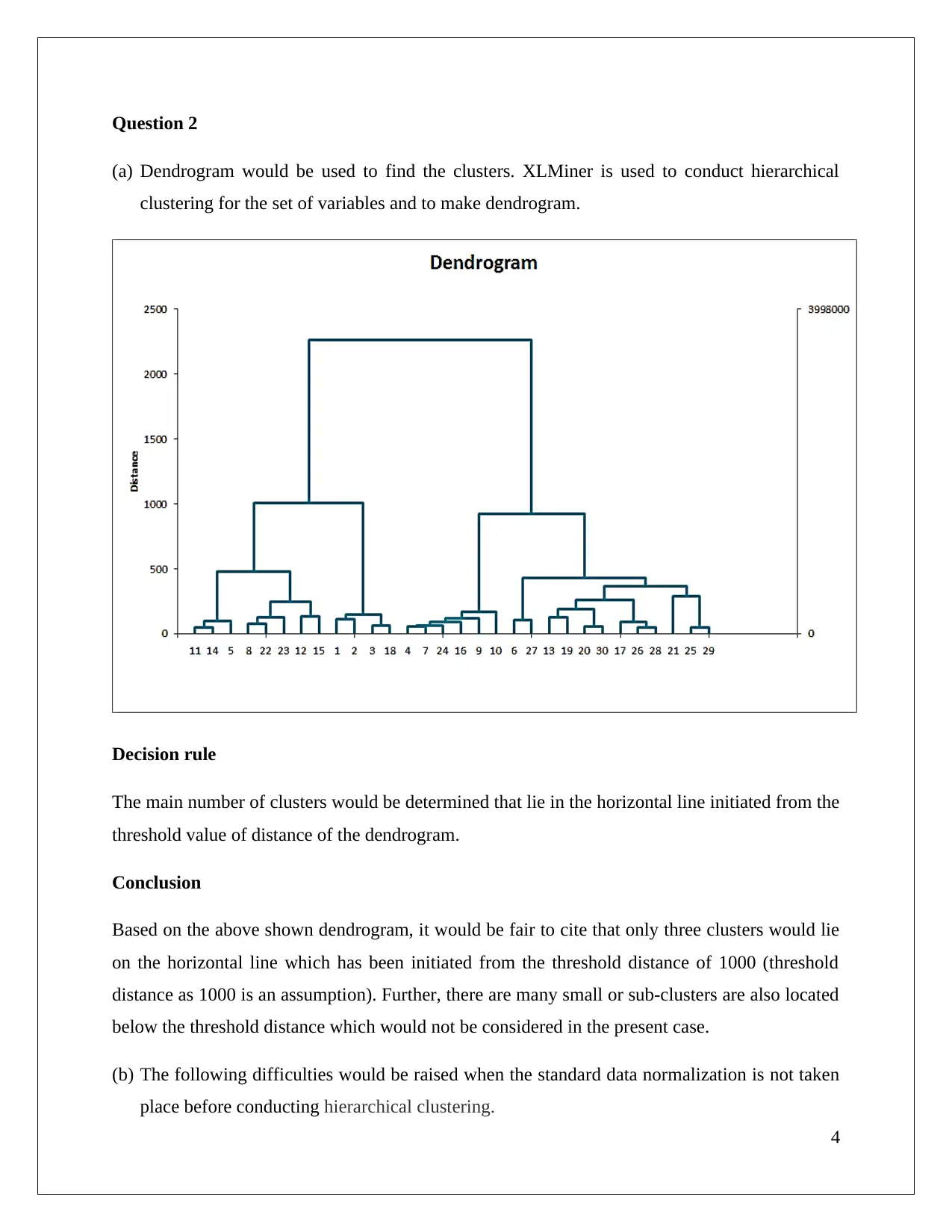
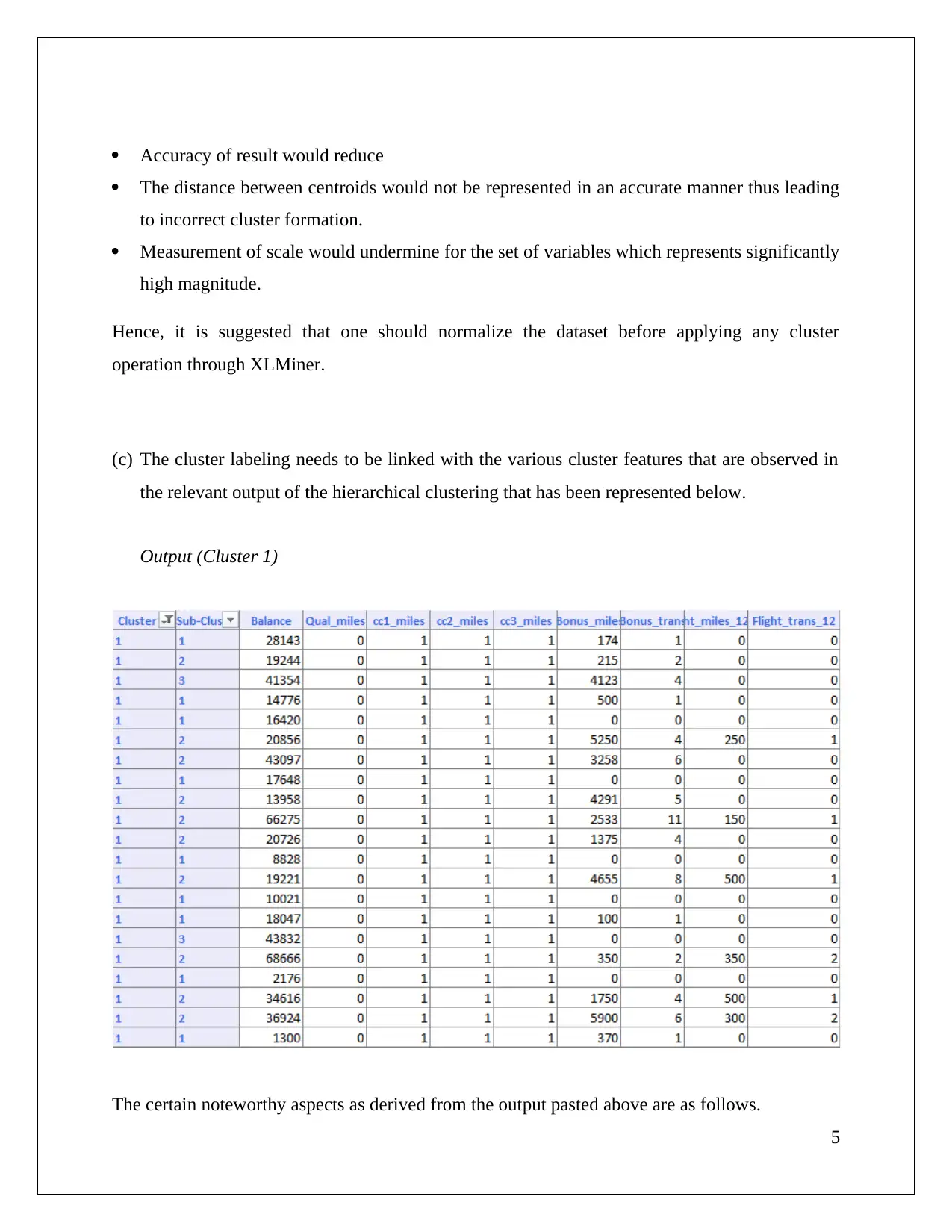
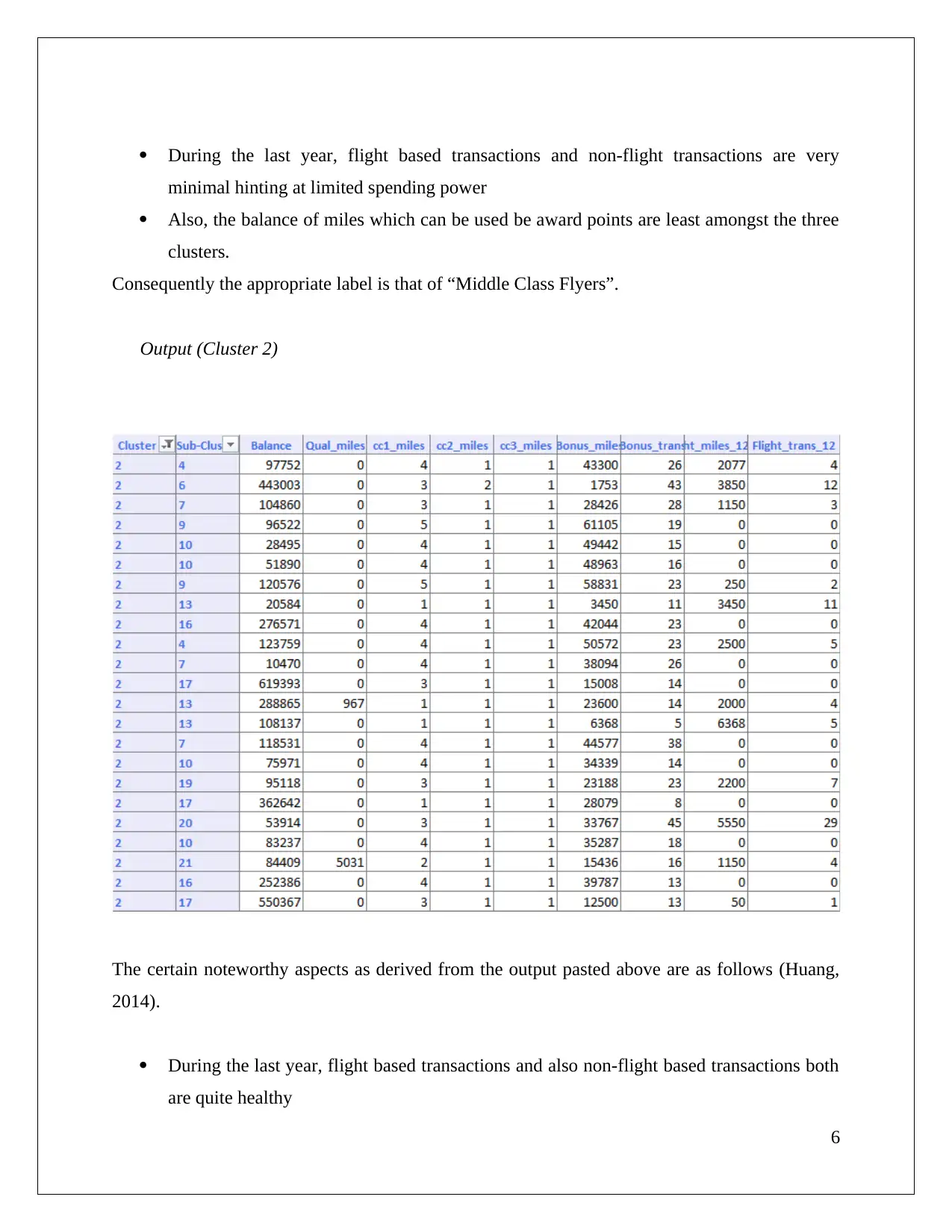
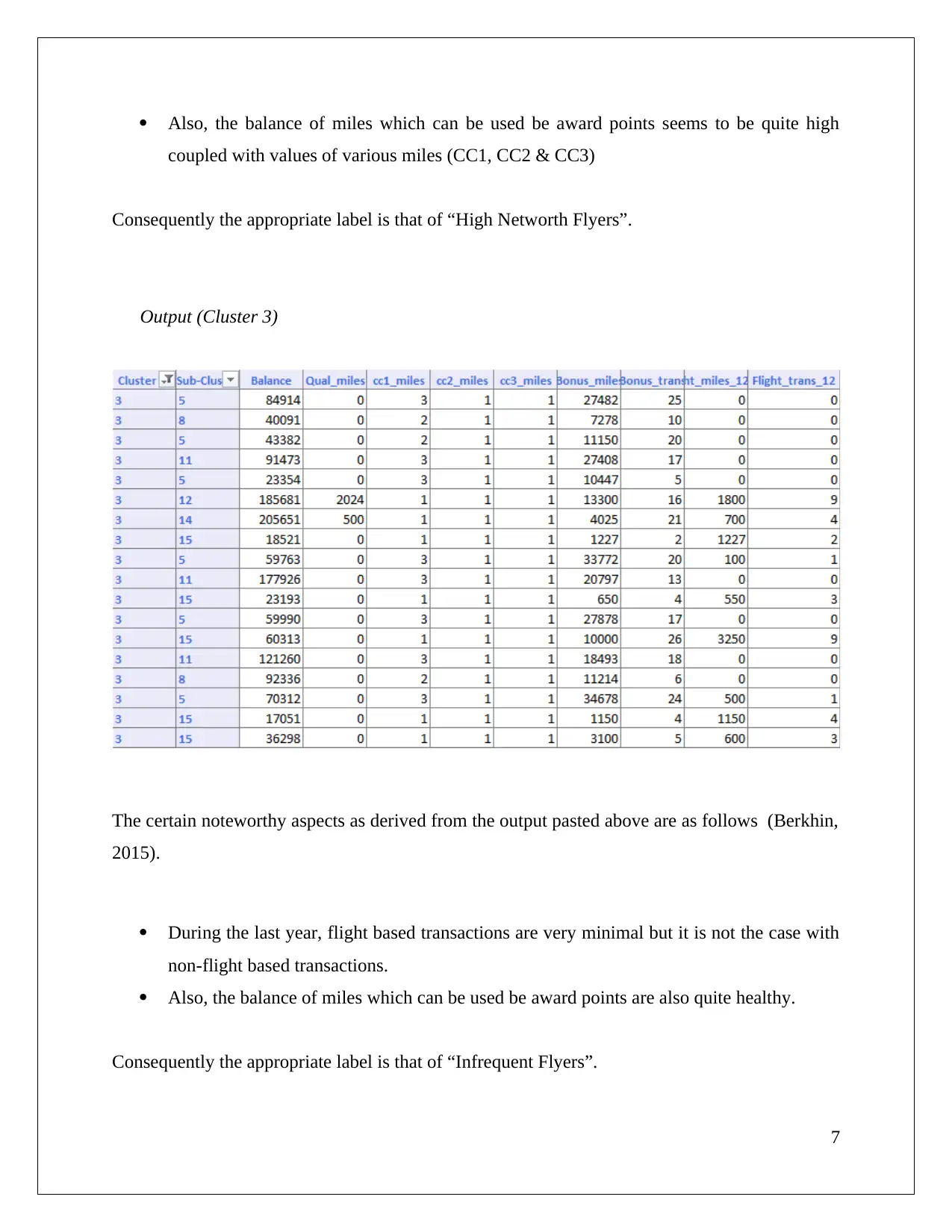
This assignment solution analyzes a cosmetic data set using association rule mining and clustering techniques. The student utilizes XLMiner to perform association rule analysis, exploring the impact of confidence levels on rule generation and identifying redundant rules. The solution then applies hierarchical clustering, using dendrograms to determine optimal cluster numbers and discusses the importance of data normalization. Finally, it compares hierarchical clustering with K-means clustering, analyzes cluster characteristics, and suggests targeted offers for each cluster based on flight and non-flight transaction data. The document references several academic sources to support the analysis.






1 out of 11
Related Documents






Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Copyright © 2020–2026 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.