Data Mining: WEKA Toolkit Analysis and Classification Report
VerifiedAdded on 2022/09/05
|22
|1558
|14
Report
AI Summary
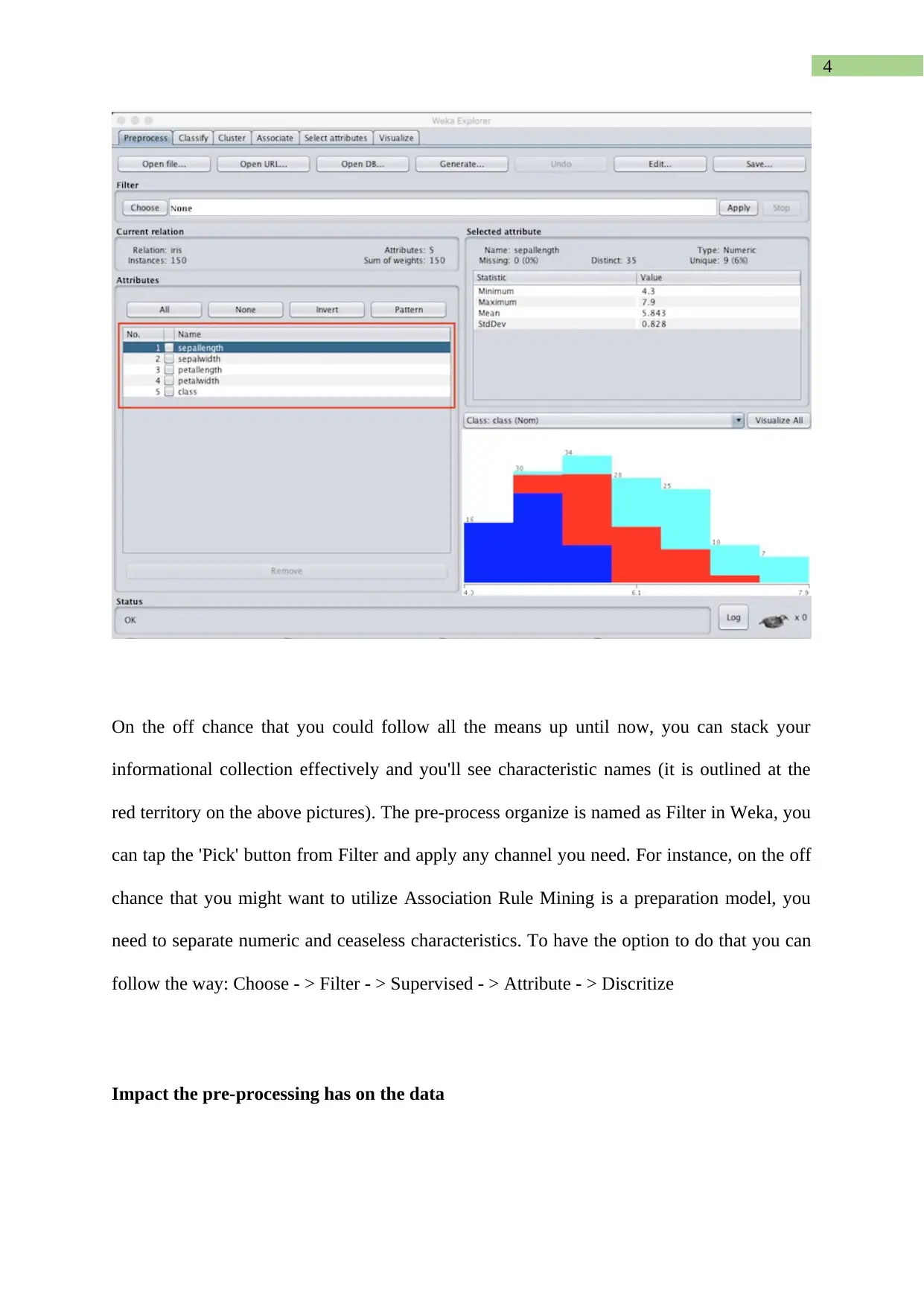
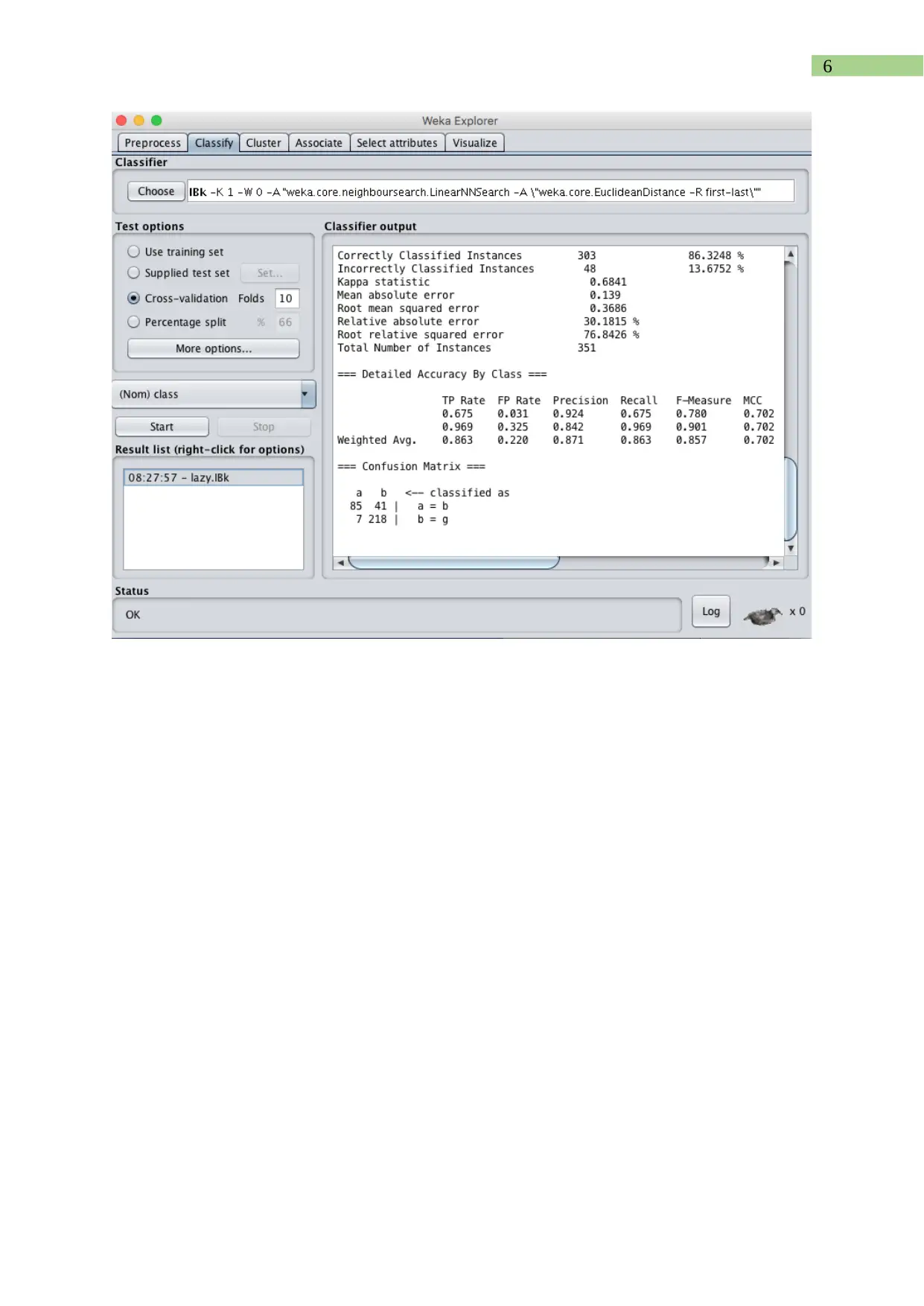
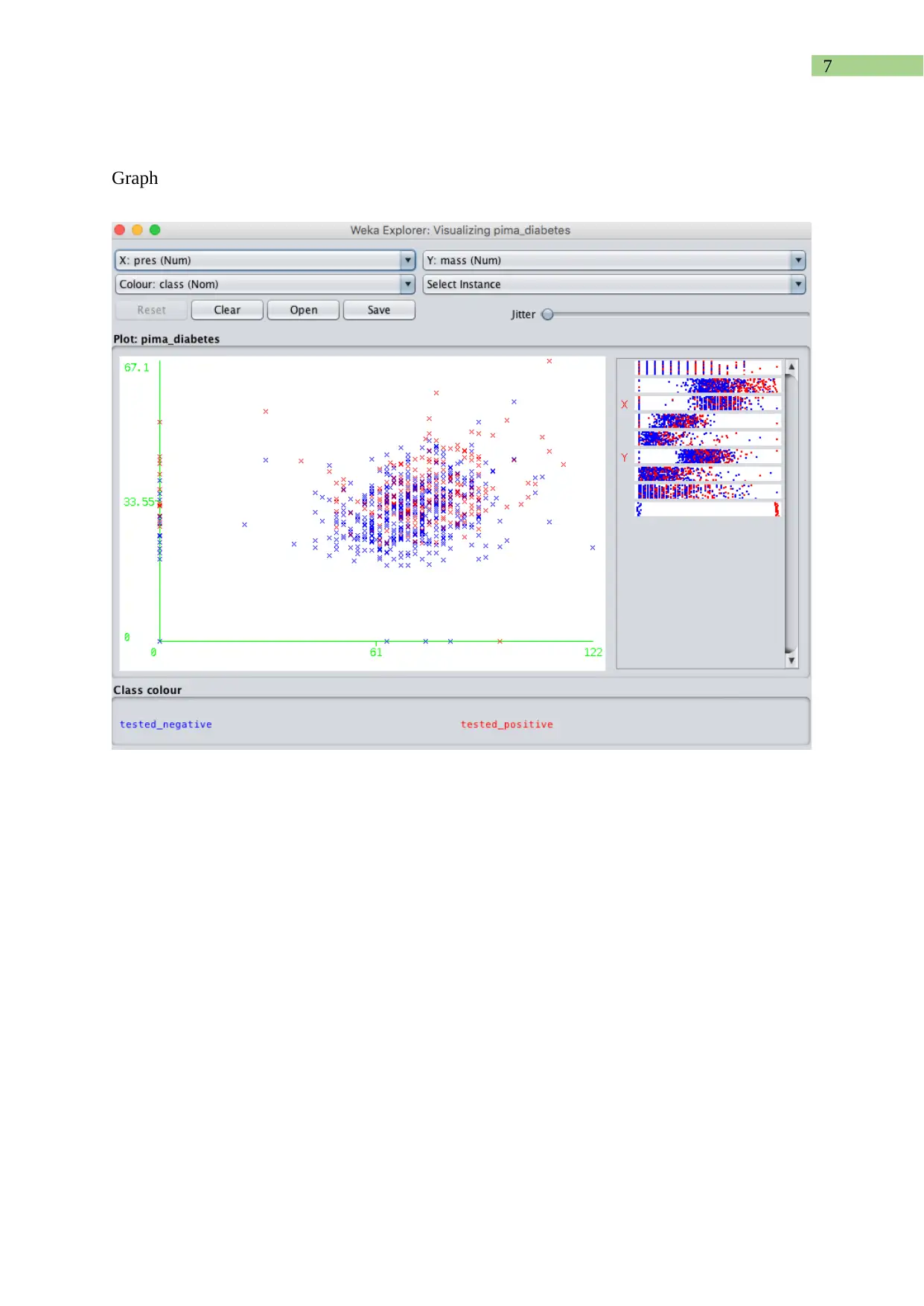
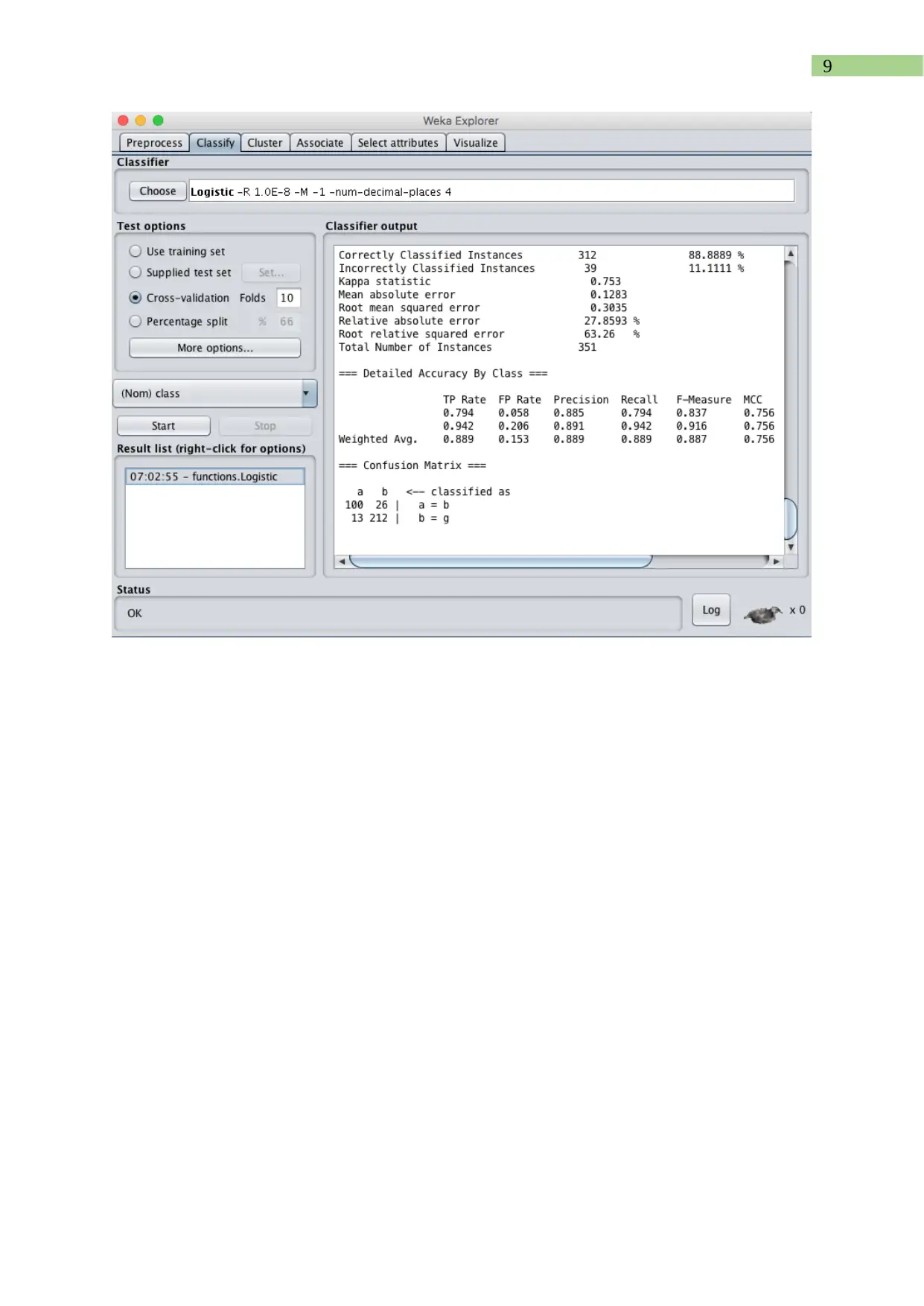
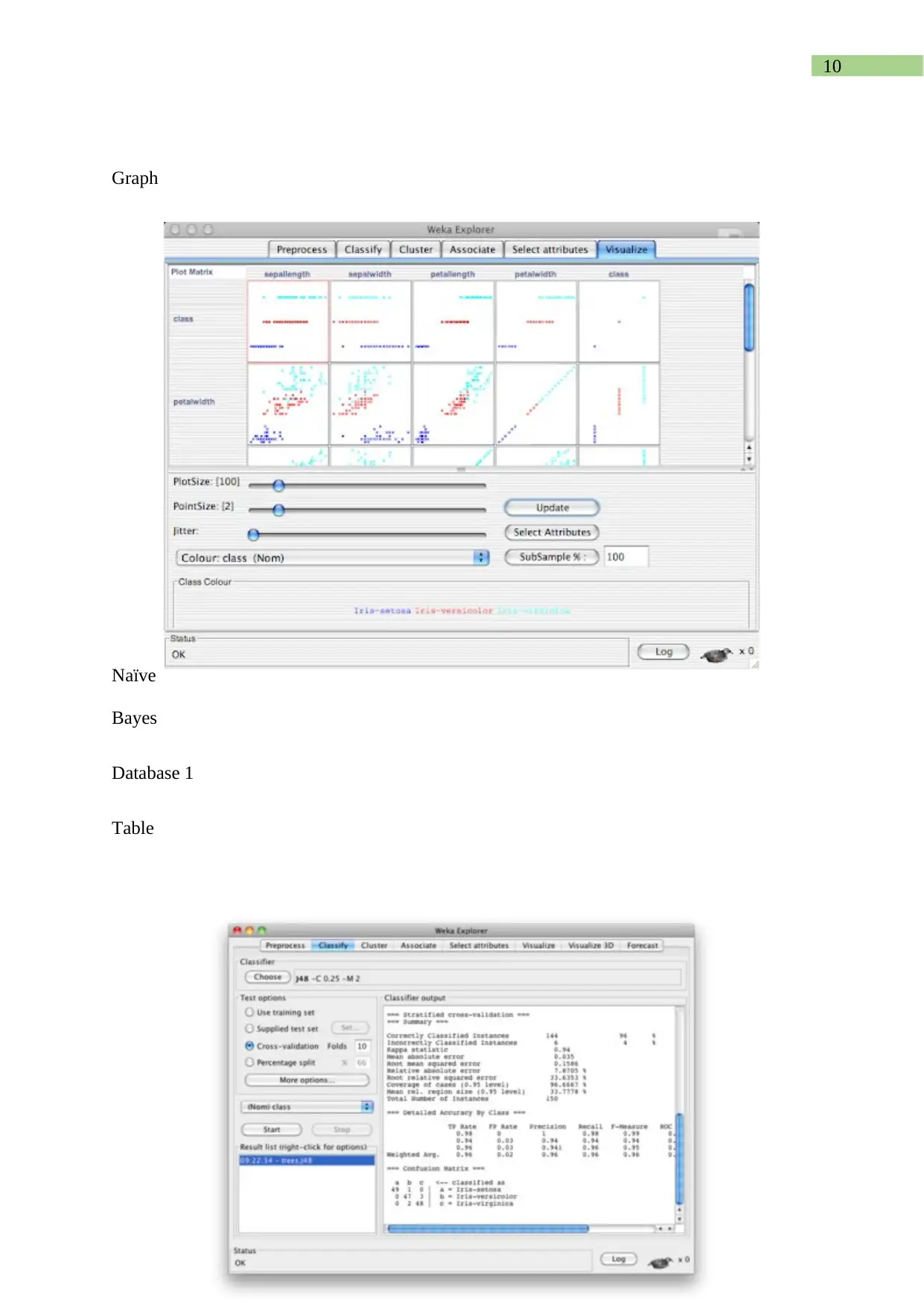
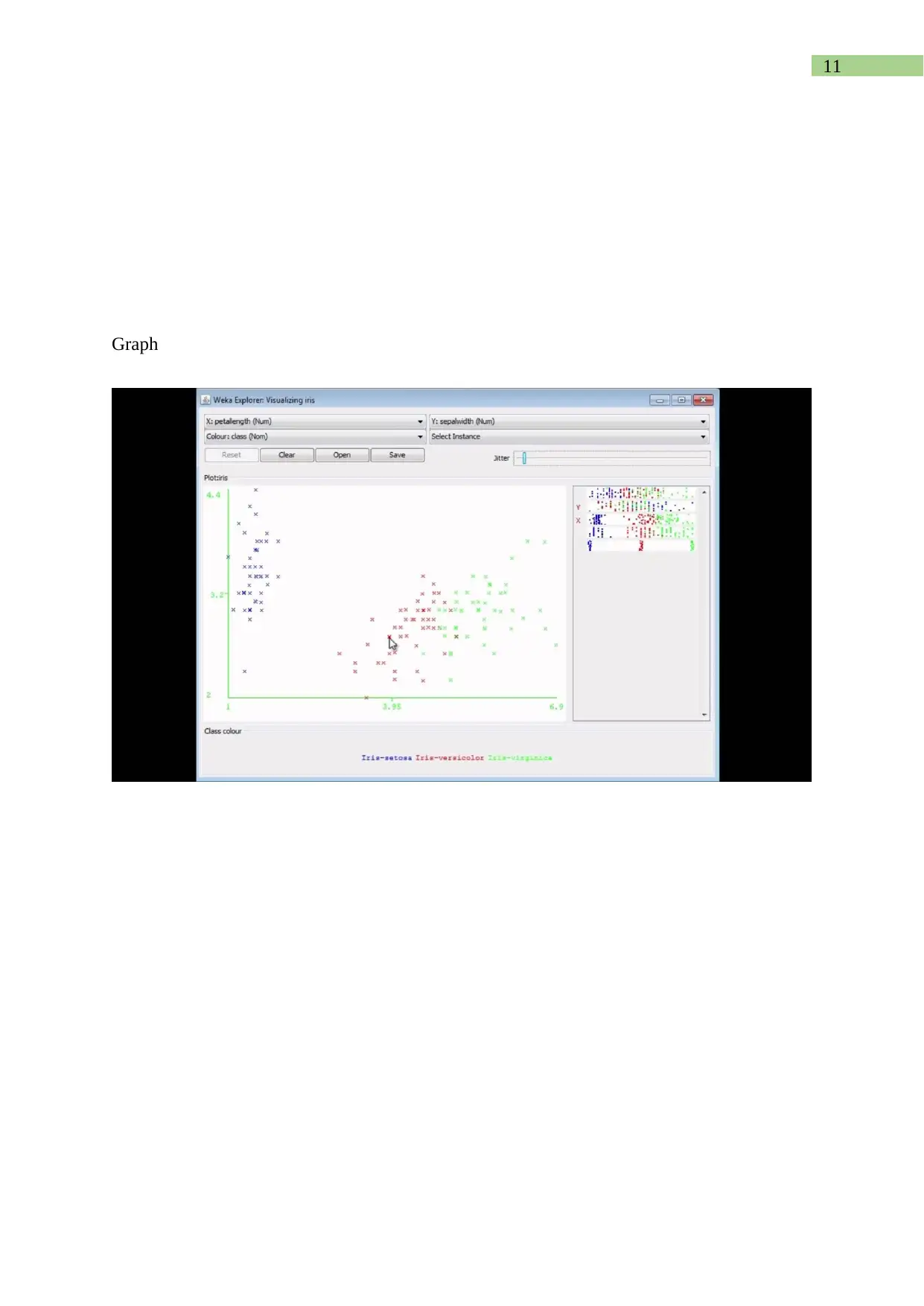
This report presents a comprehensive analysis of a text dataset using the WEKA data mining toolkit. The assignment involves identifying keywords, converting the dataset into ARFF format, and applying pre-processing techniques. The student explores the impact of these techniques on the data. Furthermore, the report evaluates the performance of decision-tree (J48), Naïve Bayes, and Support Vector Machine classifiers, generating tables and graphs to compare their performance against varying training set sizes. The report details the conversion techniques, pre-processing steps, and the rationale behind the choices made, providing insights into the practical application of data mining methodologies and the utility of the WEKA toolkit. The report also includes a conclusion summarizing the findings and the effectiveness of the methods used, along with a reference list.






1 out of 22


Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Copyright © 2020–2026 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.