Data Mining Assignment: Rules, Clustering, and XL Miner Analysis
VerifiedAdded on 2020/03/16
|9
|973
|68
Homework Assignment
AI Summary
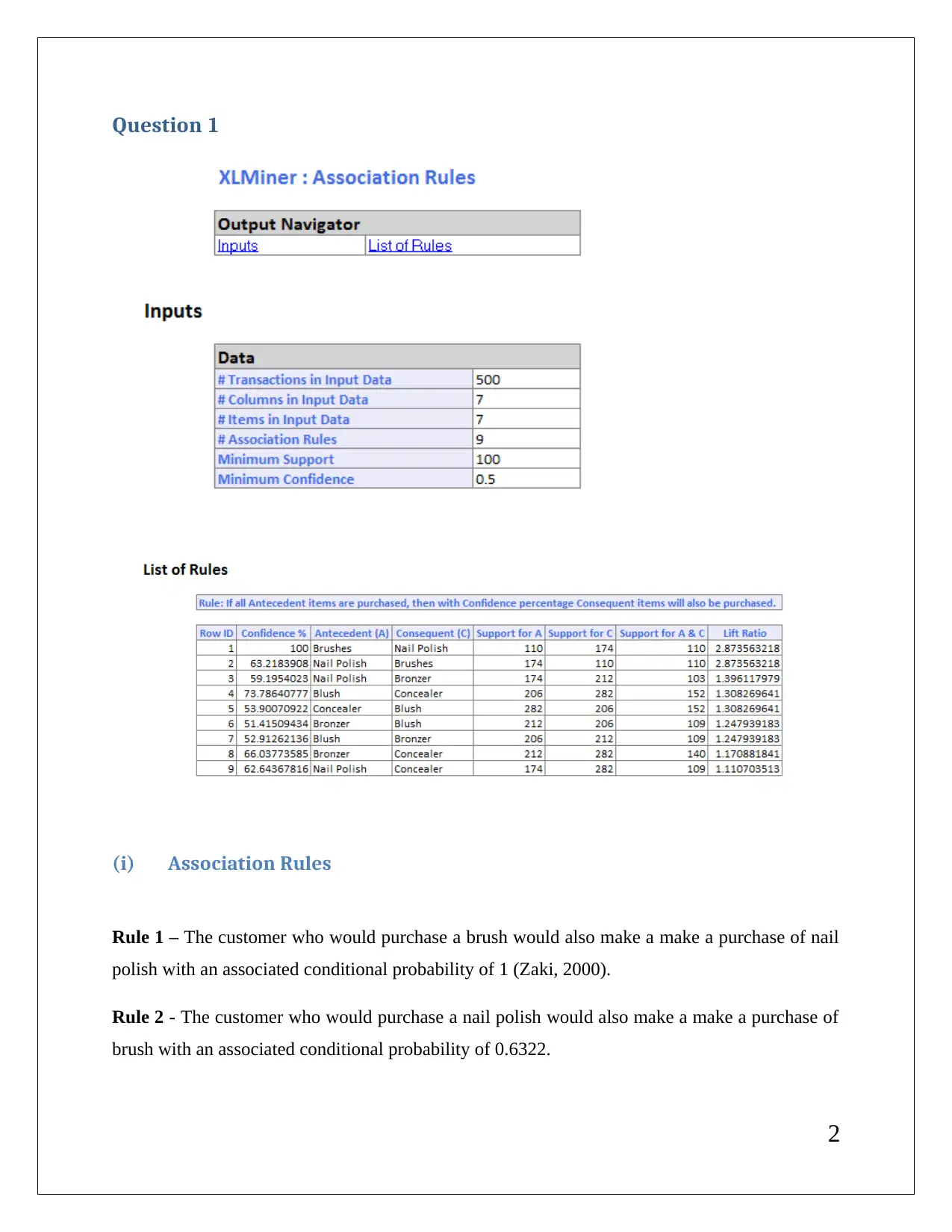
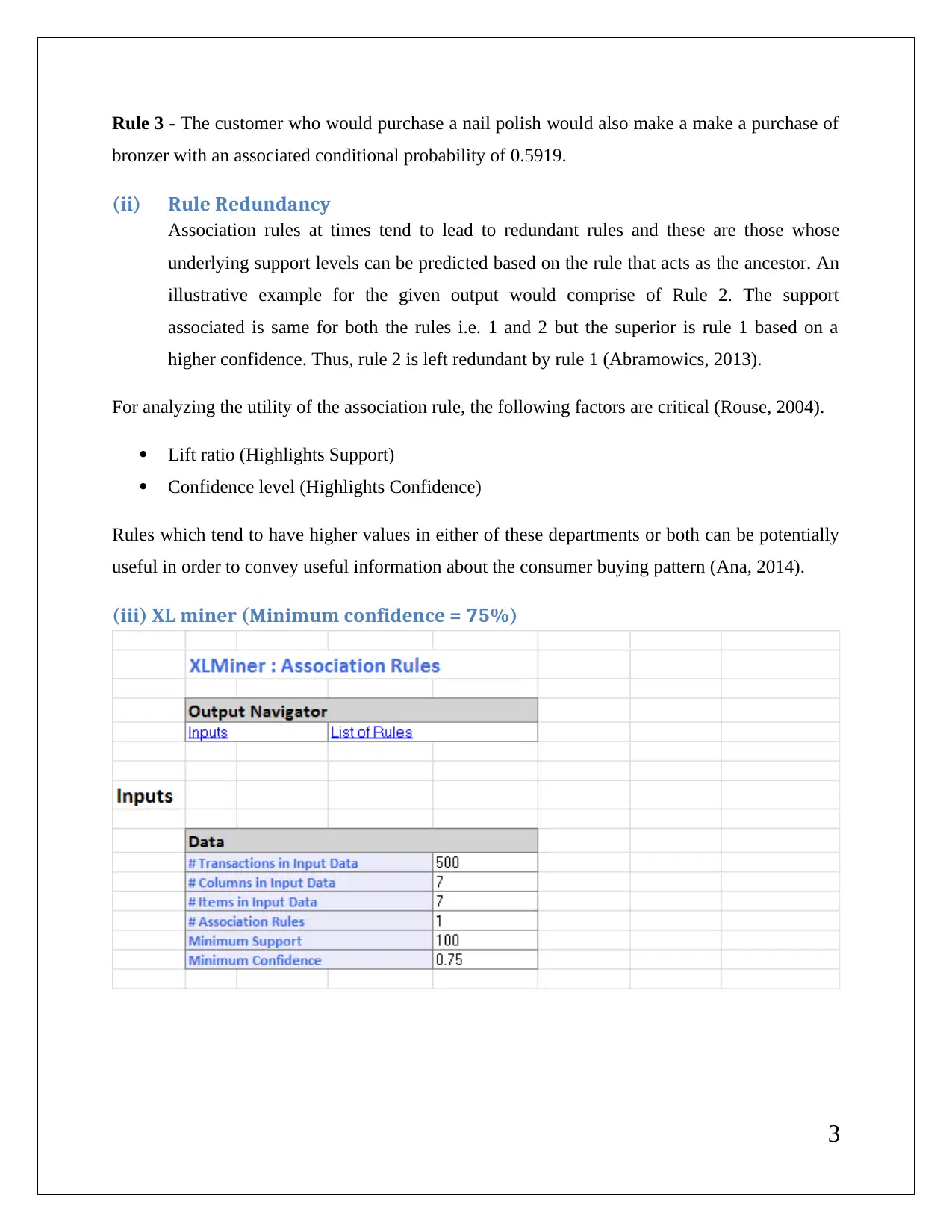
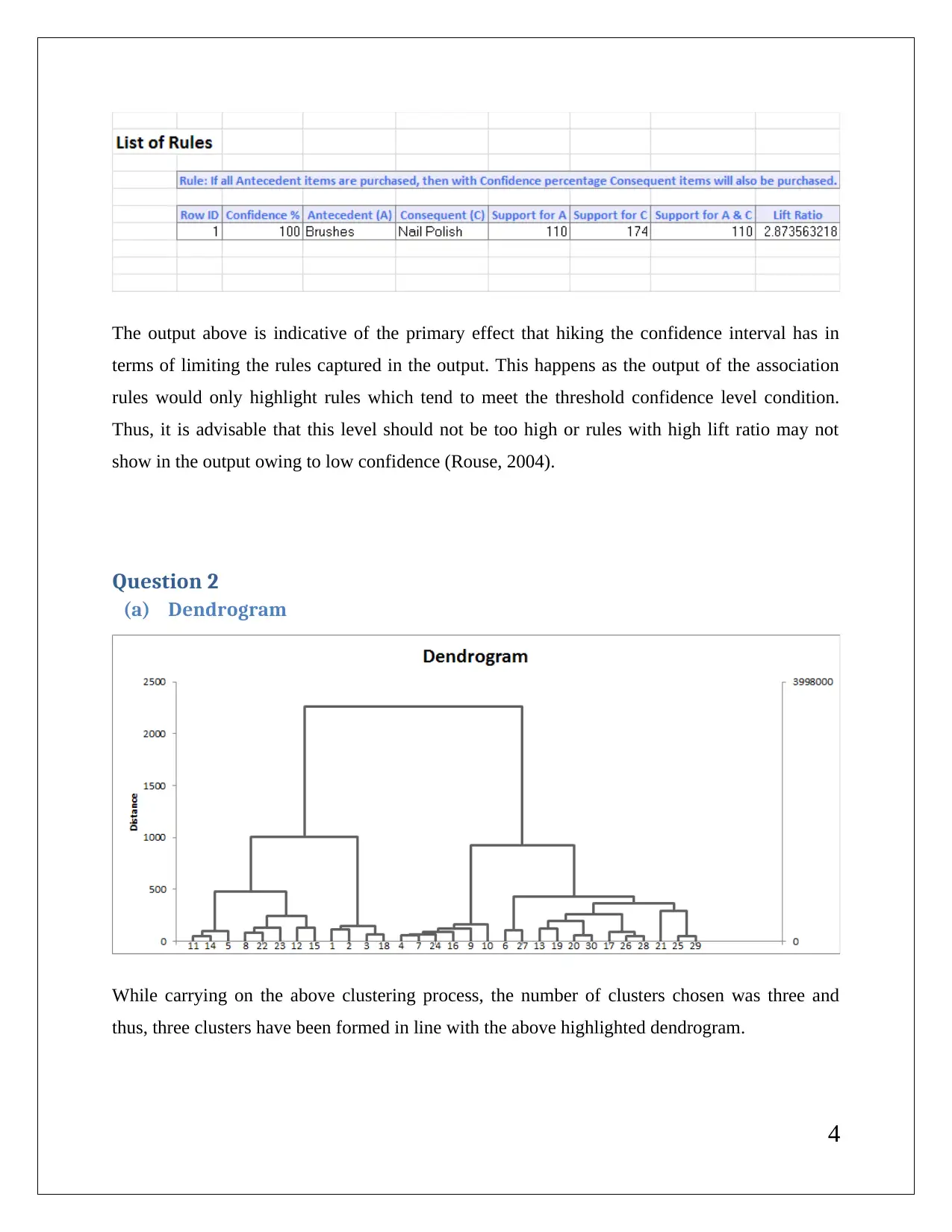
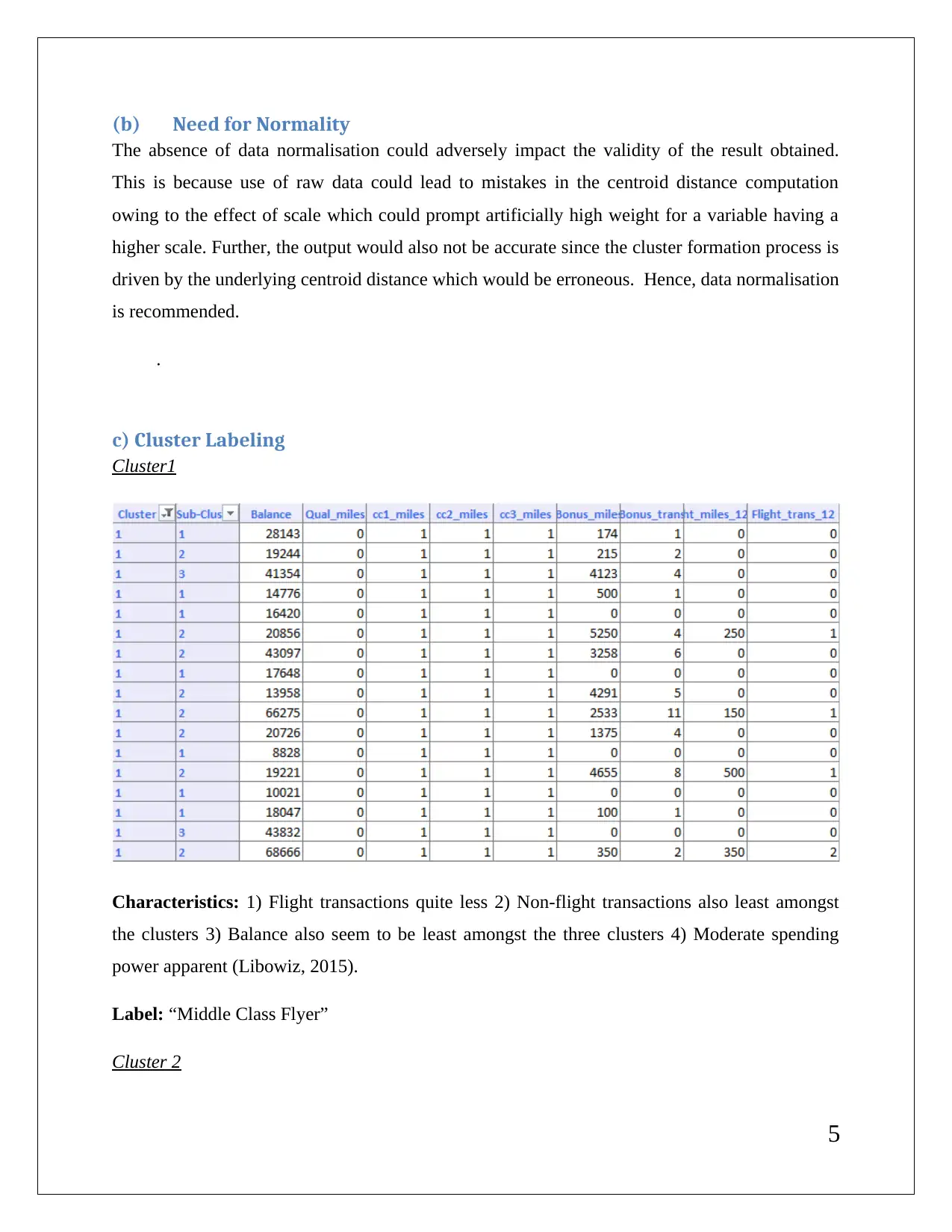
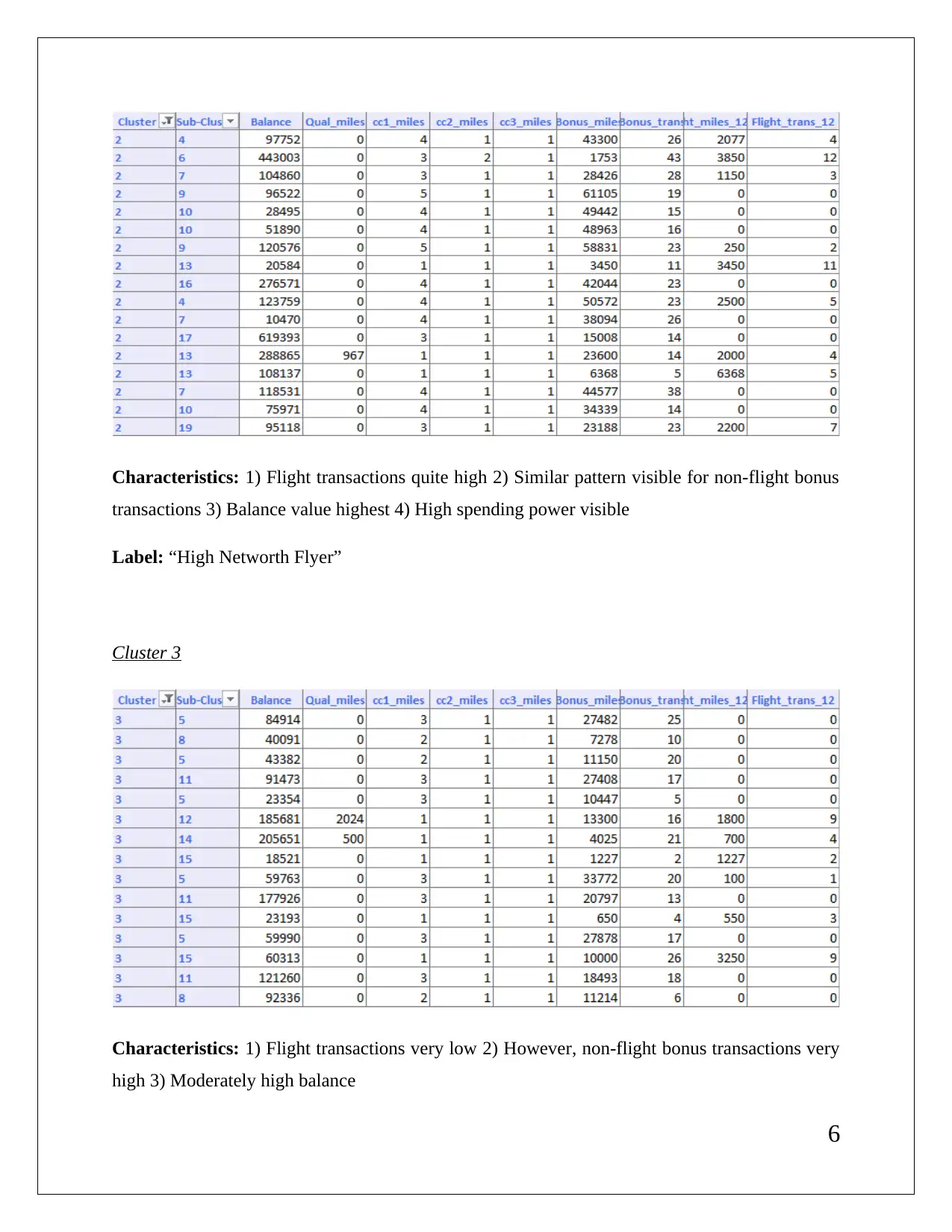
This data mining assignment delves into association rules, rule redundancy, and the application of XL miner with a minimum confidence level of 75%. It explores the significance of lift ratio and confidence levels in evaluating association rules. The assignment also covers hierarchical clustering using dendrograms, emphasizing the need for data normalization to ensure accurate centroid distance computations and cluster formation. It involves cluster labeling based on characteristics like flight and non-flight transactions and balance. K-means clustering is also discussed, comparing its classification with hierarchical clustering. Finally, the assignment outlines strategies for targeting specific clusters with tailored offers, such as providing reward points to frequent flyers and those with high bonus point usage.




1 out of 9
Related Documents






Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Copyright © 2020–2026 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.