Data Mining Assignment: Analyzing XL Miner Output and Clustering
VerifiedAdded on 2020/03/15
|7
|739
|219
Homework Assignment
AI Summary
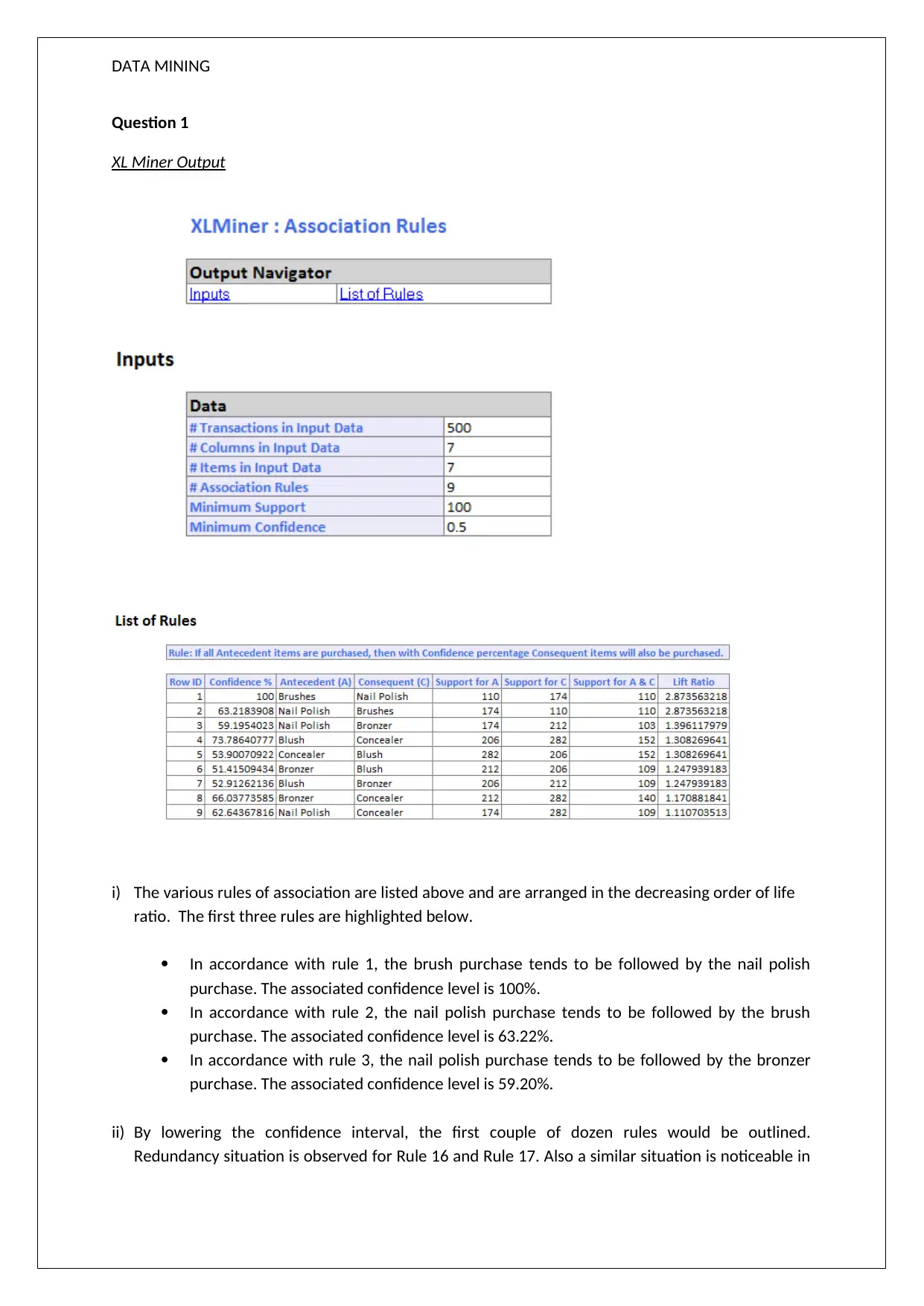
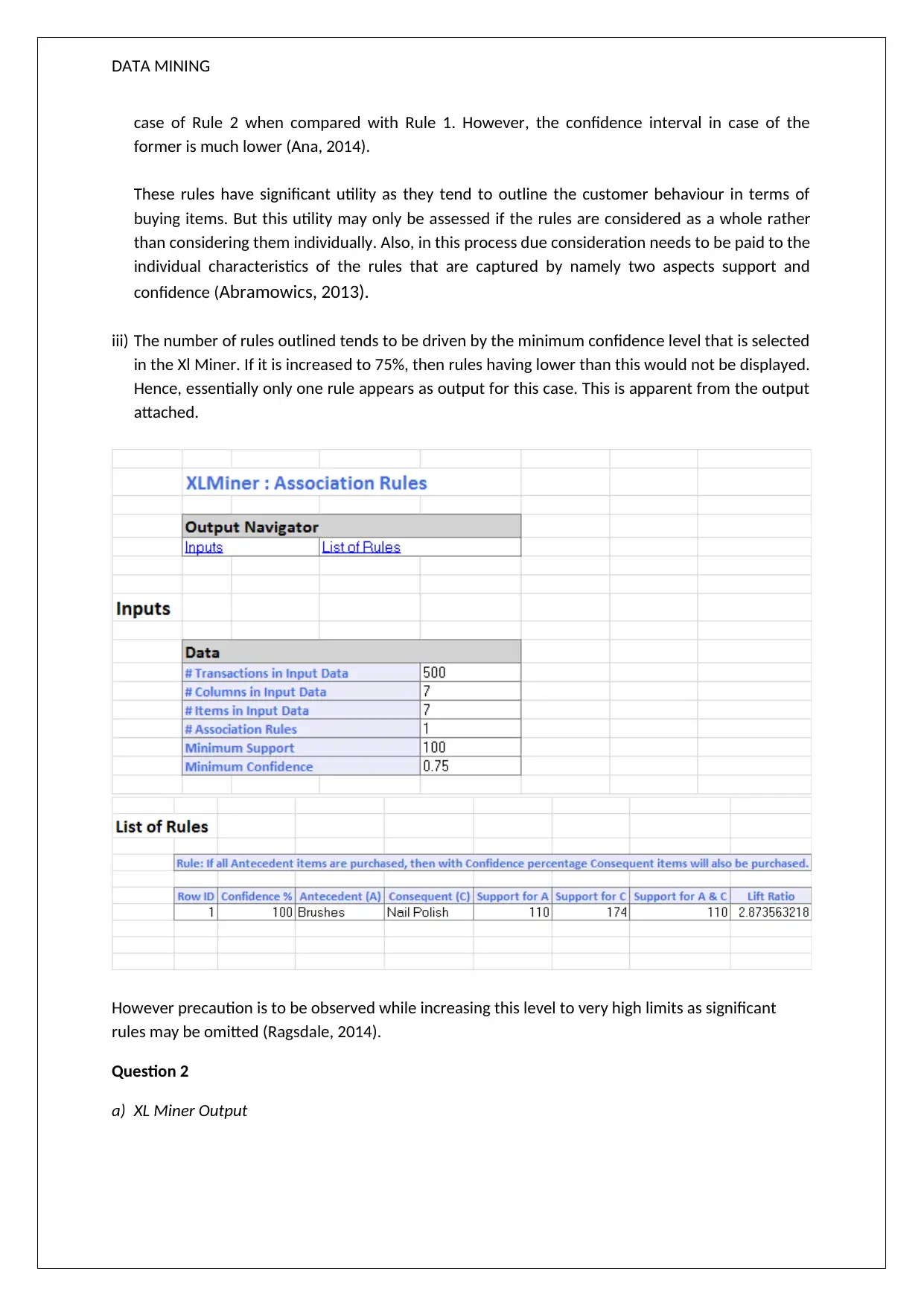
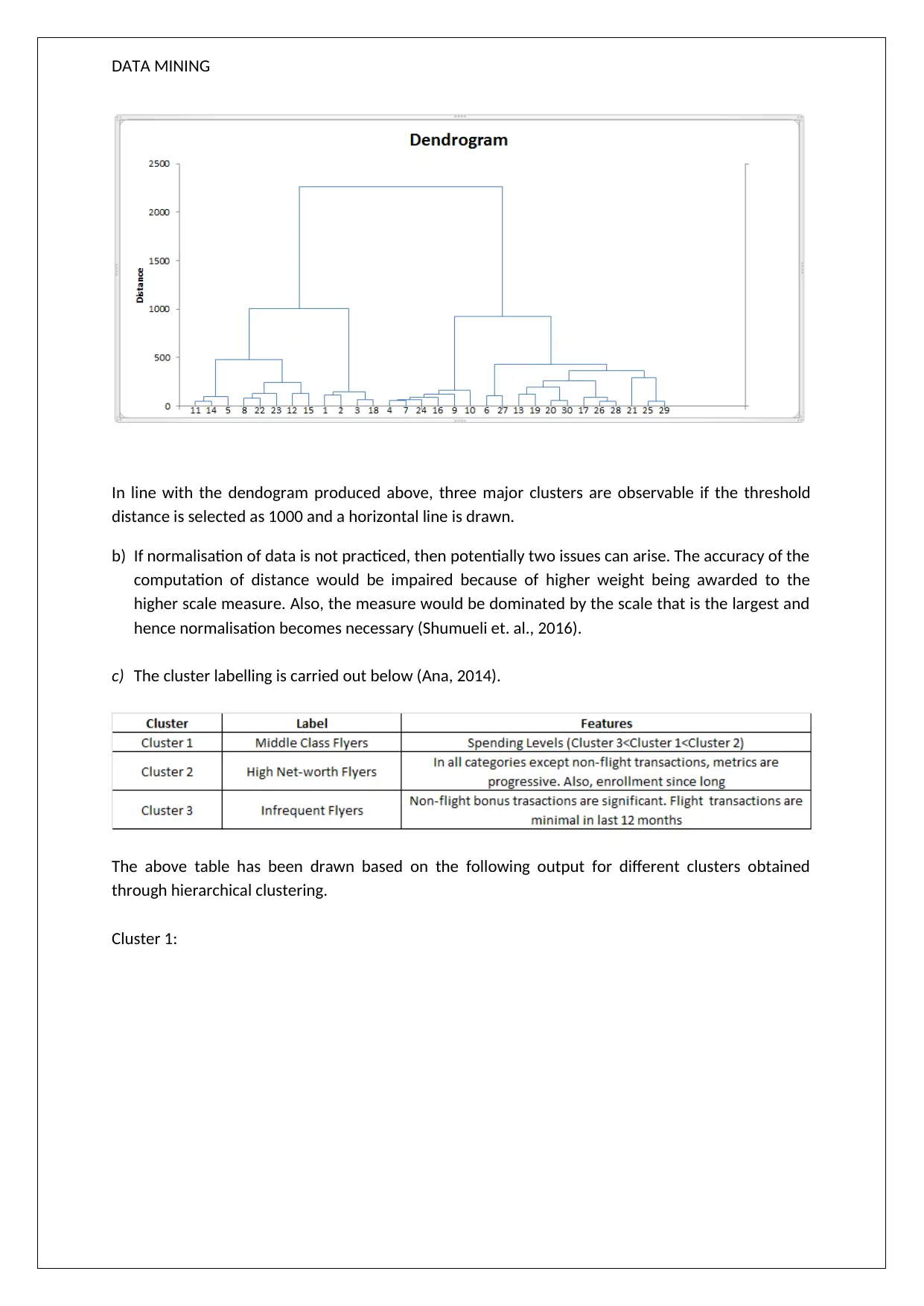
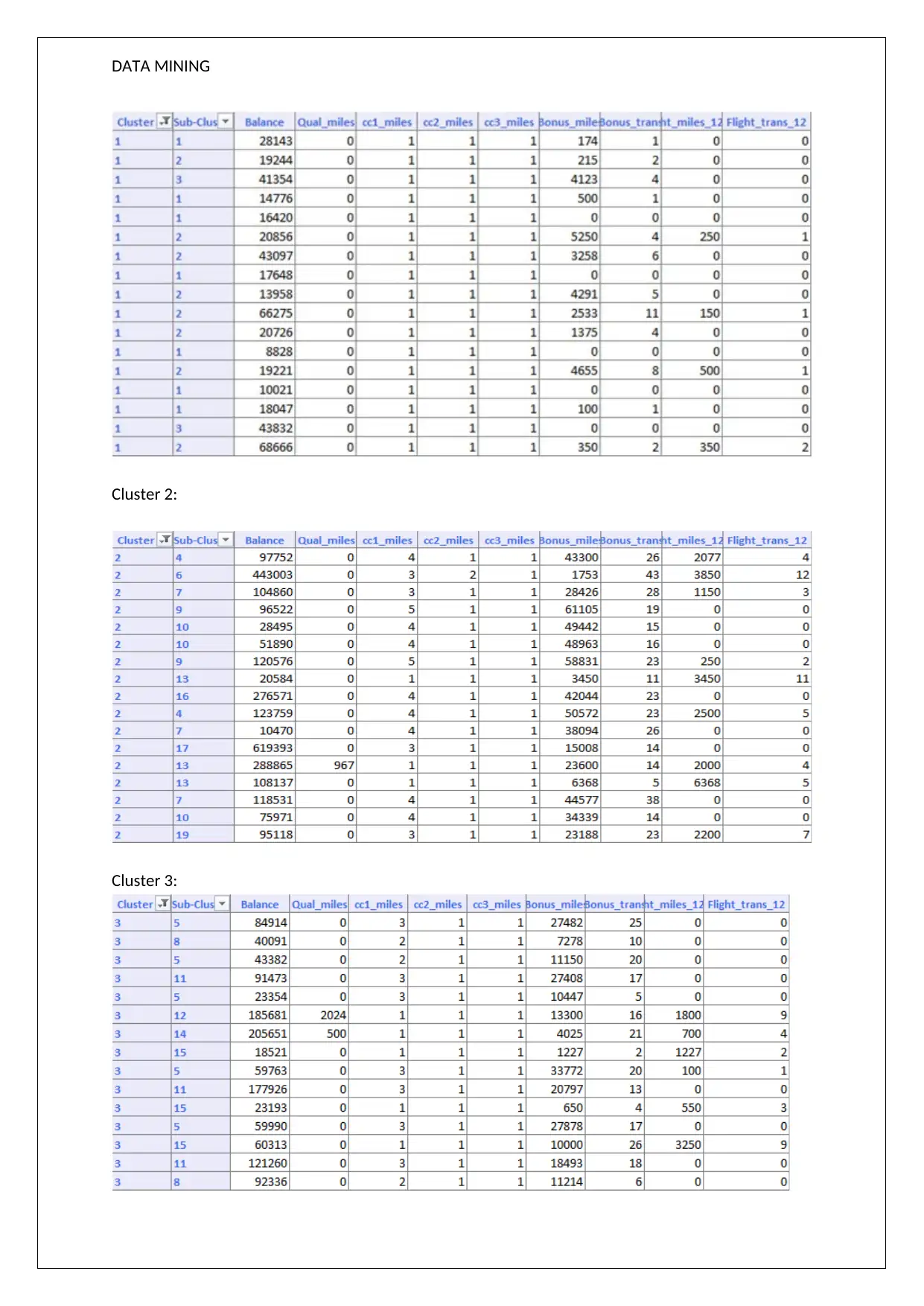
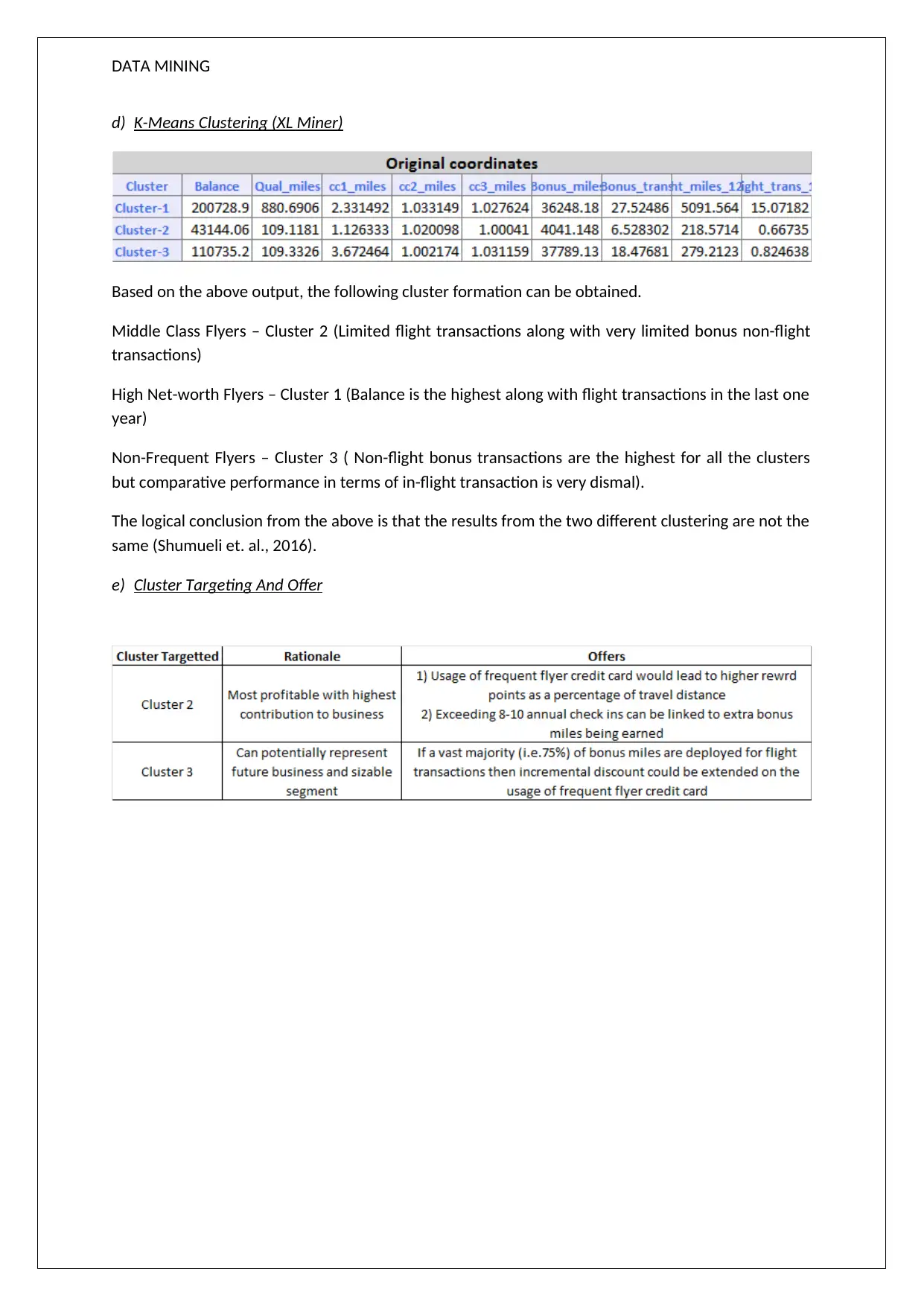
This data mining assignment solution analyzes XL Miner output to understand customer behavior through association rules and clustering techniques. The assignment begins by examining association rules, highlighting the relationship between product purchases and their confidence levels. It then delves into hierarchical clustering, identifying clusters based on a dendrogram and discussing the importance of data normalization. The solution further explores K-Means clustering, categorizing customers into different segments based on flight and non-flight transactions. The analysis emphasizes that the results from the two different clustering methods may not be the same. The assignment concludes with a discussion on cluster targeting and offers, along with references to relevant literature.


1 out of 7
Related Documents




![Data Mining Assignment for [Course Name] - Analysis and Findings](/_next/image/?url=https%3A%2F%2Fdesklib.com%2Fmedia%2Fimages%2Fml%2F8b9bb9b0c77d435887f2ac7476b3a62f.jpg&w=256&q=75)

Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Copyright © 2020–2026 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.