Teesside University Data Mining Report: Employee Performance
VerifiedAdded on 2022/11/17
|20
|4116
|311
Report
AI Summary
This report explores the application of data mining techniques to predict and analyze employee performance. It begins with an executive summary and introduction, highlighting the significance of employee performance prediction in organizations. The report delves into the Decision Tree approach, explaining its structure, attribute selection, and application in evaluating employee performance based on various factors. It then discusses the CRISP-DM model, detailing its role in guiding the data mining lifecycle and its use of classification algorithms like C4.5, ID3, and Naïve Bayes. The report further examines data mining techniques, including data preprocessing with clustering using WEKA, and classification and association techniques. The classification technique is explained with a focus on the Decision Tree model. The association technique is used in prediction of the performance of the employees by finding the binary set of the variables affecting them. The report includes tables and figures to illustrate the concepts and models discussed, and a conclusion summarizing the findings. References are provided at the end.

Running head: DATA MINING 1
Data mining
Name
Institution
Professor
Course
Date
Data mining
Name
Institution
Professor
Course
Date
Paraphrase This Document
Need a fresh take? Get an instant paraphrase of this document with our AI Paraphraser

DATA MINING 2
Table of Contents
1.0 Executive summary 2
2.0 Introduction 3
3.0 Decision Tree approach in prediction of the employees’ performance 4
4.0 The CRISP-DM model in prediction of the employees’ performance 5
5.0 Data mining techniques 6
5.1 Data pre-processing and preparation by clustering of the dataset 7
6.0 Classification technique 8
7.0 Association technique 9
8.0 The process of data mining 10
8.1 Modeling and experiments in CIS4015-N: Data Mining and CIS4035-N:
Machine Learning 11
9.0 conclusion 12
10.0 references 13
1.0 Executive summary
Table of Contents
1.0 Executive summary 2
2.0 Introduction 3
3.0 Decision Tree approach in prediction of the employees’ performance 4
4.0 The CRISP-DM model in prediction of the employees’ performance 5
5.0 Data mining techniques 6
5.1 Data pre-processing and preparation by clustering of the dataset 7
6.0 Classification technique 8
7.0 Association technique 9
8.0 The process of data mining 10
8.1 Modeling and experiments in CIS4015-N: Data Mining and CIS4035-N:
Machine Learning 11
9.0 conclusion 12
10.0 references 13
1.0 Executive summary

DATA MINING 3
The prediction of the employee’s performance is an essential requirement in any
organization. The performance of the employees is determined by various factors such as social,
personal, dependability and environmental factors among others. Data mining is one of the tools
used in the determination of the performance of the employees in an organization. Data mining
techniques are used in discovering the hidden information and dataset patterns. Besides, it is used
in the determination of the relationship between the large volumes of data during the decision-
making process in an organization. The report indicates that a single data contains a lot of the
datasets and information required in determination of employees’ performance. The type of
information used in evaluation of employees’ performance in an organization is determined by
the datasets used. It is significant in deciding which data processing method will be used in the
report.
2.0 Introduction
The performance of the employees is determined by the monitoring of the organizational
outcomes and evaluation of employees’ datasets. The data mining technique is a combination of
the machine learning, visualization techniques and statistics in discovering new knowledge
regarding the datasets. The retention of the employees is an indication of organizational
enrollment and performance. By use of the data mining techniques, the problems in an
organization will be identified in advance to avoid major damages (Valle, Varas and Ruz 2012
pp.9939). The raw data will be pre-processed in this report by filling up the values which are
missing, the transformation of the benefits which are given in the form and attribution of the
relevant variables. In this case, one of the used methods is Decision Tree technique (Huang, Tsou
and Lee 2016 pp.396). The report involves classification of the datasets into groups of classes
pre-defined. In other words, this is defined as supervised machine learning because the
The prediction of the employee’s performance is an essential requirement in any
organization. The performance of the employees is determined by various factors such as social,
personal, dependability and environmental factors among others. Data mining is one of the tools
used in the determination of the performance of the employees in an organization. Data mining
techniques are used in discovering the hidden information and dataset patterns. Besides, it is used
in the determination of the relationship between the large volumes of data during the decision-
making process in an organization. The report indicates that a single data contains a lot of the
datasets and information required in determination of employees’ performance. The type of
information used in evaluation of employees’ performance in an organization is determined by
the datasets used. It is significant in deciding which data processing method will be used in the
report.
2.0 Introduction
The performance of the employees is determined by the monitoring of the organizational
outcomes and evaluation of employees’ datasets. The data mining technique is a combination of
the machine learning, visualization techniques and statistics in discovering new knowledge
regarding the datasets. The retention of the employees is an indication of organizational
enrollment and performance. By use of the data mining techniques, the problems in an
organization will be identified in advance to avoid major damages (Valle, Varas and Ruz 2012
pp.9939). The raw data will be pre-processed in this report by filling up the values which are
missing, the transformation of the benefits which are given in the form and attribution of the
relevant variables. In this case, one of the used methods is Decision Tree technique (Huang, Tsou
and Lee 2016 pp.396). The report involves classification of the datasets into groups of classes
pre-defined. In other words, this is defined as supervised machine learning because the
⊘ This is a preview!⊘
Do you want full access?
Subscribe today to unlock all pages.
Trusted by 1+ million students worldwide

DATA MINING 4
performance of the employees is determined through an examination of the data available in an
organization regarding their performance. In the process of improving the way employees
perform in an organization, the managers will have to monitor the daily performance of those
employees (Shazmeen, Baig and Pawar 2013 pp.1). In this process, data mining process will be
used in the prediction of the employees’ performance. Some of the questions that will be
answered based on the provided data in the report include the following.
1. What is the generation of the predictive variable data sources?
2. What are the different factors which affect the performance of the employees in an
organization?
3. How the Decision Tree model is constructed by use of the classified data mining techniques
in regard to the identified variables predicted with their values?
4. How is the dataset of the predictive valuables gathered?
5. What is the relationship between the factors affecting the efficiency of the model used?
The chosen analytics approaches suitable for this analysis is Decision Tree approach on the
performance of the employees and the CRISP-DM method (Sung, Chang and Lee 2019 pp.63).
The approaches used in this report are used to answer the proposed questions with valid
adaptation and clear justifications.
3.0 Decision Tree approach in prediction of the employees’ performance
The Decision Tree approach is a tree-like model or graph used for making the decisions
and the possible consequences in an organization. It includes the chances of the outcomes, utility
and resources costs. It is one of the ways of applying the algorithm in data mining technique
performance of the employees is determined through an examination of the data available in an
organization regarding their performance. In the process of improving the way employees
perform in an organization, the managers will have to monitor the daily performance of those
employees (Shazmeen, Baig and Pawar 2013 pp.1). In this process, data mining process will be
used in the prediction of the employees’ performance. Some of the questions that will be
answered based on the provided data in the report include the following.
1. What is the generation of the predictive variable data sources?
2. What are the different factors which affect the performance of the employees in an
organization?
3. How the Decision Tree model is constructed by use of the classified data mining techniques
in regard to the identified variables predicted with their values?
4. How is the dataset of the predictive valuables gathered?
5. What is the relationship between the factors affecting the efficiency of the model used?
The chosen analytics approaches suitable for this analysis is Decision Tree approach on the
performance of the employees and the CRISP-DM method (Sung, Chang and Lee 2019 pp.63).
The approaches used in this report are used to answer the proposed questions with valid
adaptation and clear justifications.
3.0 Decision Tree approach in prediction of the employees’ performance
The Decision Tree approach is a tree-like model or graph used for making the decisions
and the possible consequences in an organization. It includes the chances of the outcomes, utility
and resources costs. It is one of the ways of applying the algorithm in data mining technique
Paraphrase This Document
Need a fresh take? Get an instant paraphrase of this document with our AI Paraphraser

DATA MINING 5
(COE 2012 pp.201). Decision Tree approach is commonly used in operation research especially
when there is a significant decision to be made. It helps in identifying the strategy for the
purpose of reaching the goals of an organization. The process of constructing the Decision Tree
is not complicated because it requires selection of the variables for training such as nodes and
variable branches. The data is generally created into different sub-set of datasets (Thakar 2015
pp.5176). In each of the branch, training of the sample is done to correspond to each subset of
the branch of the parent node. When the nodes of all the chapters are classified, the attributes
remaining are used for further sub-divisions based on characteristics of the individual employees
and their performance (Cortez et al., 2009 pp.547).
The approach is organized similar to the tree structure in which all of the used nodes
indicate the value of the attributed target value. The decision node specifies the test to be carried
out by the single value attribute of the branches and sub-branches of the outcome tests.
Source: file:///C:/Users/user/Documents/fa84c2e3ad0e2ca07148ed000e98a5cc4d44.pdf
(COE 2012 pp.201). Decision Tree approach is commonly used in operation research especially
when there is a significant decision to be made. It helps in identifying the strategy for the
purpose of reaching the goals of an organization. The process of constructing the Decision Tree
is not complicated because it requires selection of the variables for training such as nodes and
variable branches. The data is generally created into different sub-set of datasets (Thakar 2015
pp.5176). In each of the branch, training of the sample is done to correspond to each subset of
the branch of the parent node. When the nodes of all the chapters are classified, the attributes
remaining are used for further sub-divisions based on characteristics of the individual employees
and their performance (Cortez et al., 2009 pp.547).
The approach is organized similar to the tree structure in which all of the used nodes
indicate the value of the attributed target value. The decision node specifies the test to be carried
out by the single value attribute of the branches and sub-branches of the outcome tests.
Source: file:///C:/Users/user/Documents/fa84c2e3ad0e2ca07148ed000e98a5cc4d44.pdf
DATA MINING 6
The attribute selection is usually made by use of the information in the decision tree model. In
the process of creating the Decision Tree in the prediction of the employees’ performance, there
is a need to find all information in each of the attributes (Jantan, Hamdan and Othman 2009
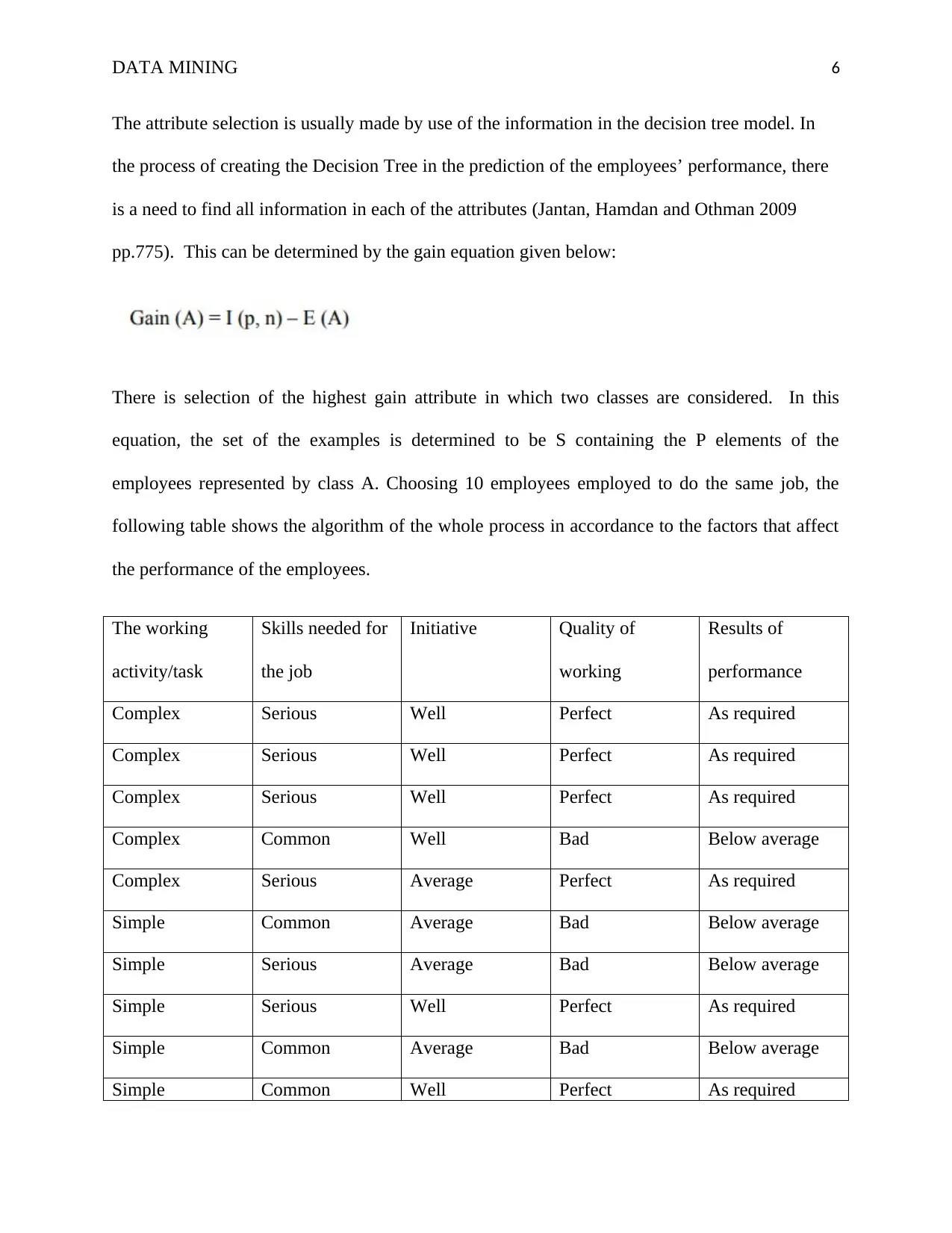
pp.775). This can be determined by the gain equation given below:
There is selection of the highest gain attribute in which two classes are considered. In this
equation, the set of the examples is determined to be S containing the P elements of the
employees represented by class A. Choosing 10 employees employed to do the same job, the
following table shows the algorithm of the whole process in accordance to the factors that affect
the performance of the employees.
The working
activity/task
Skills needed for
the job
Initiative Quality of
working
Results of
performance
Complex Serious Well Perfect As required
Complex Serious Well Perfect As required
Complex Serious Well Perfect As required
Complex Common Well Bad Below average
Complex Serious Average Perfect As required
Simple Common Average Bad Below average
Simple Serious Average Bad Below average
Simple Serious Well Perfect As required
Simple Common Average Bad Below average
Simple Common Well Perfect As required
The attribute selection is usually made by use of the information in the decision tree model. In
the process of creating the Decision Tree in the prediction of the employees’ performance, there
is a need to find all information in each of the attributes (Jantan, Hamdan and Othman 2009
pp.775). This can be determined by the gain equation given below:
There is selection of the highest gain attribute in which two classes are considered. In this
equation, the set of the examples is determined to be S containing the P elements of the
employees represented by class A. Choosing 10 employees employed to do the same job, the
following table shows the algorithm of the whole process in accordance to the factors that affect
the performance of the employees.
The working
activity/task
Skills needed for
the job
Initiative Quality of
working
Results of
performance
Complex Serious Well Perfect As required
Complex Serious Well Perfect As required
Complex Serious Well Perfect As required
Complex Common Well Bad Below average
Complex Serious Average Perfect As required
Simple Common Average Bad Below average
Simple Serious Average Bad Below average
Simple Serious Well Perfect As required
Simple Common Average Bad Below average
Simple Common Well Perfect As required
⊘ This is a preview!⊘
Do you want full access?
Subscribe today to unlock all pages.
Trusted by 1+ million students worldwide

DATA MINING 7
4.0 The CRISP-DM model in prediction of the employees’ performance
This model is suitable in the prediction of the employment performance because it
provides general guidance in developing the Data mining lifecycle. The performance of the
employees is collected from the human resources database in organization concerned (Gera and
Goel 2015 pp.18). The series of various experiences are conducted and tested by use of the
employees’ form model. In case of the multiple and complexity of the datasets, the generic
process of the knowledge discovery database is reformed using the effective results. The
classification process is carried out by use of the three different data mining algorithms, which
includes; C4.5, ID3 and Naïve Bayes. The three data mining algorithm are used in identifying the
best algorithm of classification approach (Strohmeier and Piazza 2013 pp.2410). The chosen type
of algorithm is improvised through obtaining the best rate of classification. The predictions of
the employees' attributions appraisal form provide the results of their performance. The factors
which need to be considered in this aspect are; marital status, age, gender, specialization, the job
group, the level of training, salary, experience and qualification. The attribution factors are
classified into three categories. The first category is D which represents the age, marital status
and gender. The second category is E which represents the specialization and the level of
training. The last category is P which represents the experience, salary, designation and PAS.
The attributes in this framework are normally put in the performance target class (Wu 2010
pp.2371).
4.0 The CRISP-DM model in prediction of the employees’ performance
This model is suitable in the prediction of the employment performance because it
provides general guidance in developing the Data mining lifecycle. The performance of the
employees is collected from the human resources database in organization concerned (Gera and
Goel 2015 pp.18). The series of various experiences are conducted and tested by use of the
employees’ form model. In case of the multiple and complexity of the datasets, the generic
process of the knowledge discovery database is reformed using the effective results. The
classification process is carried out by use of the three different data mining algorithms, which
includes; C4.5, ID3 and Naïve Bayes. The three data mining algorithm are used in identifying the
best algorithm of classification approach (Strohmeier and Piazza 2013 pp.2410). The chosen type
of algorithm is improvised through obtaining the best rate of classification. The predictions of
the employees' attributions appraisal form provide the results of their performance. The factors
which need to be considered in this aspect are; marital status, age, gender, specialization, the job
group, the level of training, salary, experience and qualification. The attribution factors are
classified into three categories. The first category is D which represents the age, marital status
and gender. The second category is E which represents the specialization and the level of
training. The last category is P which represents the experience, salary, designation and PAS.
The attributes in this framework are normally put in the performance target class (Wu 2010
pp.2371).
Paraphrase This Document
Need a fresh take? Get an instant paraphrase of this document with our AI Paraphraser

DATA MINING 8
Source: https://pdfs.semanticscholar.org/c26e/ecb0736bb494afdba29b9fdb6b2d8da7293c.pdf
The target classes are discrete in natures and they have an outstanding improvement to
meet the minimal requirements possible. The same data can be represented in algorithm rate of
accuracy which offers the comparison of the accuracy obtained rates. They can as well be
classified into the different categories as shown in the table below.
Number The technique Accuracy
classification
A. ID3 63.67%
B. Naïve Bayes 81.15%
C. C4.5 93.23%
Source: https://pdfs.semanticscholar.org/c26e/ecb0736bb494afdba29b9fdb6b2d8da7293c.pdf
The target classes are discrete in natures and they have an outstanding improvement to
meet the minimal requirements possible. The same data can be represented in algorithm rate of
accuracy which offers the comparison of the accuracy obtained rates. They can as well be
classified into the different categories as shown in the table below.
Number The technique Accuracy
classification
A. ID3 63.67%
B. Naïve Bayes 81.15%
C. C4.5 93.23%

DATA MINING 9
In this model, the attributes of the datasets can be revealed that P is the predominant and it is
controlled by the whole process of predicting the employees’ performance. The classification is
considered as the label attributes. The C4.5 algorithm is applied in this dataset to know the
results obtained by the set rule in the training phase. Also, the classification of the rule set in the
pre-processed dataset in the testing phase helps in analyzing the data obtained. The same data
can be represented by the prediction model, which offers the appraisal of the employees’
performance. The prediction model is illustrated below.
Source:https://pdfs.semanticscholar.org/c26e/ecb0736bb494afdba29b9fdb6b2d8da7293c.pdf
5.0 Data mining techniques
5.1 Data pre-processing and preparation by clustering of the dataset
In this analysis, the tool kit which is used as a machine learning platform is WEKA but in
the process, JAVA is used in prediction of the language to be used in the process. It provides the
combined application which is used by the users to access the updated information regarding
how the employees perform in an organization. There are several tasks which are applied in
In this model, the attributes of the datasets can be revealed that P is the predominant and it is
controlled by the whole process of predicting the employees’ performance. The classification is
considered as the label attributes. The C4.5 algorithm is applied in this dataset to know the
results obtained by the set rule in the training phase. Also, the classification of the rule set in the
pre-processed dataset in the testing phase helps in analyzing the data obtained. The same data
can be represented by the prediction model, which offers the appraisal of the employees’
performance. The prediction model is illustrated below.
Source:https://pdfs.semanticscholar.org/c26e/ecb0736bb494afdba29b9fdb6b2d8da7293c.pdf
5.0 Data mining techniques
5.1 Data pre-processing and preparation by clustering of the dataset
In this analysis, the tool kit which is used as a machine learning platform is WEKA but in
the process, JAVA is used in prediction of the language to be used in the process. It provides the
combined application which is used by the users to access the updated information regarding
how the employees perform in an organization. There are several tasks which are applied in
⊘ This is a preview!⊘
Do you want full access?
Subscribe today to unlock all pages.
Trusted by 1+ million students worldwide
DATA MINING 10
clustering model. The clustering data set tool is supported by the WEKA based on the
algorithms used in statistical evaluations. In this case, WEKA users are able to make the
comparisons of the various results provided for accuracy determinations of the machine learning
and DM algorithms used (Jantan, Hamdan and Othman 2011 pp.1). The flexible dataset is one
of the flexible procedures used to detect the suitable algorithm in the provided dataset. The
clustering groups of the available is not predefined and therefore, the use of the clustering
technique identify the sparse regions and dense one in objective space of the prediction of the
employees’ performance in an organization or industry. The table below provided the various
types of the clustering techniques.
The type Algorithm
Measure of distance and similarity distance and similarity measure
Hierarchical Divisive and agglomerative
Outlier Outlier
Clustering of complex data DB Scan, BIRCH, Cure Categorical ROCK
Partitional Squared matrix, PAM, Minimum spanning
tree, clustering by use of the neural networks,
Bond energy.
Clustering prediction of the job description by use of the variable symbols and the variables
The data is shown in the table below.
clustering model. The clustering data set tool is supported by the WEKA based on the
algorithms used in statistical evaluations. In this case, WEKA users are able to make the
comparisons of the various results provided for accuracy determinations of the machine learning
and DM algorithms used (Jantan, Hamdan and Othman 2011 pp.1). The flexible dataset is one
of the flexible procedures used to detect the suitable algorithm in the provided dataset. The
clustering groups of the available is not predefined and therefore, the use of the clustering
technique identify the sparse regions and dense one in objective space of the prediction of the
employees’ performance in an organization or industry. The table below provided the various
types of the clustering techniques.
The type Algorithm
Measure of distance and similarity distance and similarity measure
Hierarchical Divisive and agglomerative
Outlier Outlier
Clustering of complex data DB Scan, BIRCH, Cure Categorical ROCK
Partitional Squared matrix, PAM, Minimum spanning
tree, clustering by use of the neural networks,
Bond energy.
Clustering prediction of the job description by use of the variable symbols and the variables
The data is shown in the table below.
Paraphrase This Document
Need a fresh take? Get an instant paraphrase of this document with our AI Paraphraser

DATA MINING 11
Resource:https://www.researchgate.net/publication/
331165269_A_proposed_Model_for_Predicting_Employees'_Performance_Using_Data_Mining
_Techniques_Egyptian_Case_Study
6.0 Classification technique
The estimation and prediction of the employees’ performance in an organization is
similar to classification frameworks. The classification technique is used when evaluating the
training dataset and applied developed models in an organization concerning how employees
perform. The data mining classification is used to get the knowledge on prediction of the how
employees perform in their respective areas of specialization. The Decision Tree technique is
used to build the classification model used in this report (Chien and Chen 2018 pp.280). There is
several classification rules used in this process. In the process of validating the classification
model developed, the prototype is constructed and relevant data collected from the human
Resource:https://www.researchgate.net/publication/
331165269_A_proposed_Model_for_Predicting_Employees'_Performance_Using_Data_Mining
_Techniques_Egyptian_Case_Study
6.0 Classification technique
The estimation and prediction of the employees’ performance in an organization is
similar to classification frameworks. The classification technique is used when evaluating the
training dataset and applied developed models in an organization concerning how employees
perform. The data mining classification is used to get the knowledge on prediction of the how
employees perform in their respective areas of specialization. The Decision Tree technique is
used to build the classification model used in this report (Chien and Chen 2018 pp.280). There is
several classification rules used in this process. In the process of validating the classification
model developed, the prototype is constructed and relevant data collected from the human

DATA MINING 12
resources department regarding the employees’ performance. The results are used to show the
performance of the employees through observation of their experiences, qualifications, ages and
other factors as mentioned above. The classification model used propose the predictions the
performance various employees in the organization. The classification model helps the human
resources staffs to focus on the capacity of the employees on how they can do certain tasks
within the organization. The information in analysis of the classification technique is shown in
the table below.
Type of classification model Algorithm
Distance K nearest neighbors, simple distance
Statistical Bayesian, regression
Decision tree CART, SPRINT, C4.5, ID3
Neural network INN supervised learning, propagation
7.0 Association technique
The association technique is used in prediction of the performance of the employees by
finding the binary set of the variables affecting them. In this technique, the employees’
characteristics are evaluated and monitored to identify their performance race in an organization.
The associated rules in mining algorithms used in this technique include Apriori, DDA, CDA
and investigating measures.
8.0 The process of data mining
The data mining process involves determination of the employees’ performance in each
department of the organization by use of classification model. In data mining technique, data
resources department regarding the employees’ performance. The results are used to show the
performance of the employees through observation of their experiences, qualifications, ages and
other factors as mentioned above. The classification model used propose the predictions the
performance various employees in the organization. The classification model helps the human
resources staffs to focus on the capacity of the employees on how they can do certain tasks
within the organization. The information in analysis of the classification technique is shown in
the table below.
Type of classification model Algorithm
Distance K nearest neighbors, simple distance
Statistical Bayesian, regression
Decision tree CART, SPRINT, C4.5, ID3
Neural network INN supervised learning, propagation
7.0 Association technique
The association technique is used in prediction of the performance of the employees by
finding the binary set of the variables affecting them. In this technique, the employees’
characteristics are evaluated and monitored to identify their performance race in an organization.
The associated rules in mining algorithms used in this technique include Apriori, DDA, CDA
and investigating measures.
8.0 The process of data mining
The data mining process involves determination of the employees’ performance in each
department of the organization by use of classification model. In data mining technique, data
⊘ This is a preview!⊘
Do you want full access?
Subscribe today to unlock all pages.
Trusted by 1+ million students worldwide
1 out of 20
Related Documents






Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Unlock your academic potential
Copyright © 2020–2026 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.