BUS 105 Business Information Systems: Data Mining & Management Report
VerifiedAdded on 2023/04/21
|9
|1578
|474
Report
AI Summary
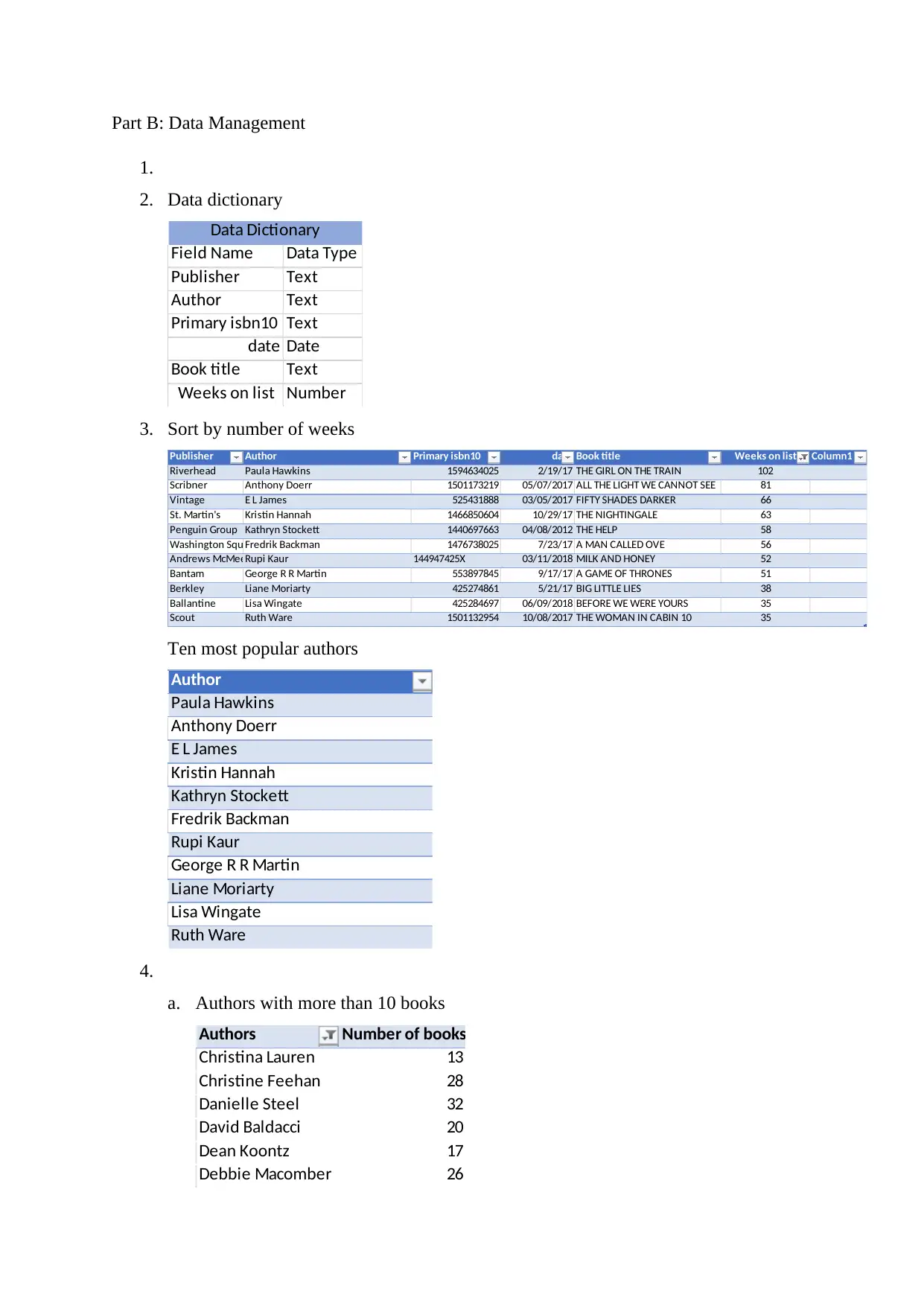
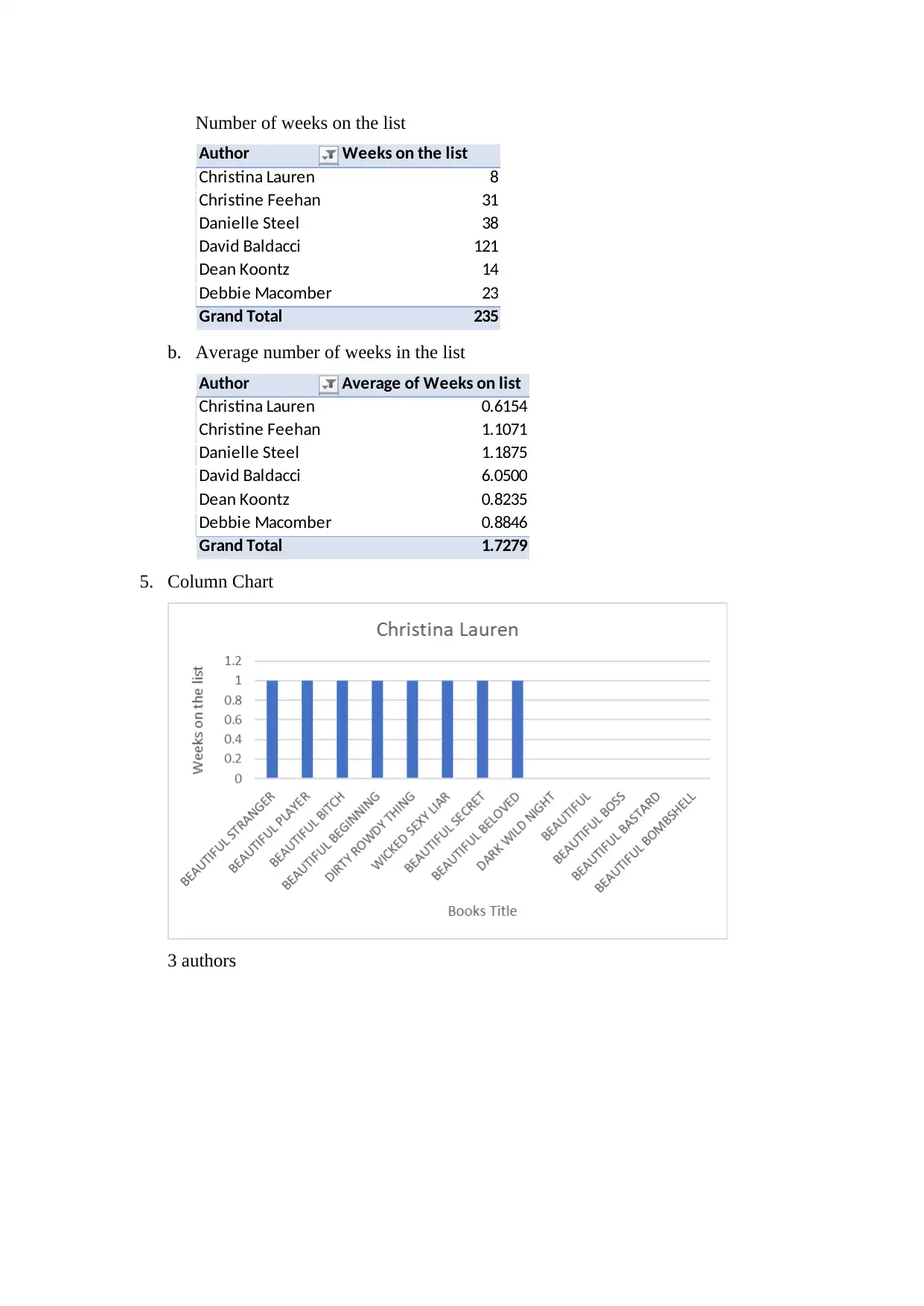
This report explores data mining and data management within the context of Business Information Systems (BUS 105). It defines data mining, outlines the phases of the Cross-Industry Standard Process for Data Mining (CRISP-DM), and discusses the importance and key elements of data mining, such as accuracy, relevancy, and specificity. The report also addresses common problems in data mining, including poor data quality and privacy concerns. The second part focuses on data management, presenting a data dictionary and analyzing book data, including sorting by weeks on the list, identifying popular authors, and calculating average weeks on the list. The analysis reveals insights into book popularity trends and author performance, highlighting the practical application of data mining techniques for understanding information and making business decisions. Desklib provides access to this document and a wealth of similar resources for students.







1 out of 9
Related Documents





Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Copyright © 2020–2026 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.