Analysis of Principal Components in Data Mining with XL Miner
VerifiedAdded on 2020/04/01
|8
|1179
|111
AI Summary
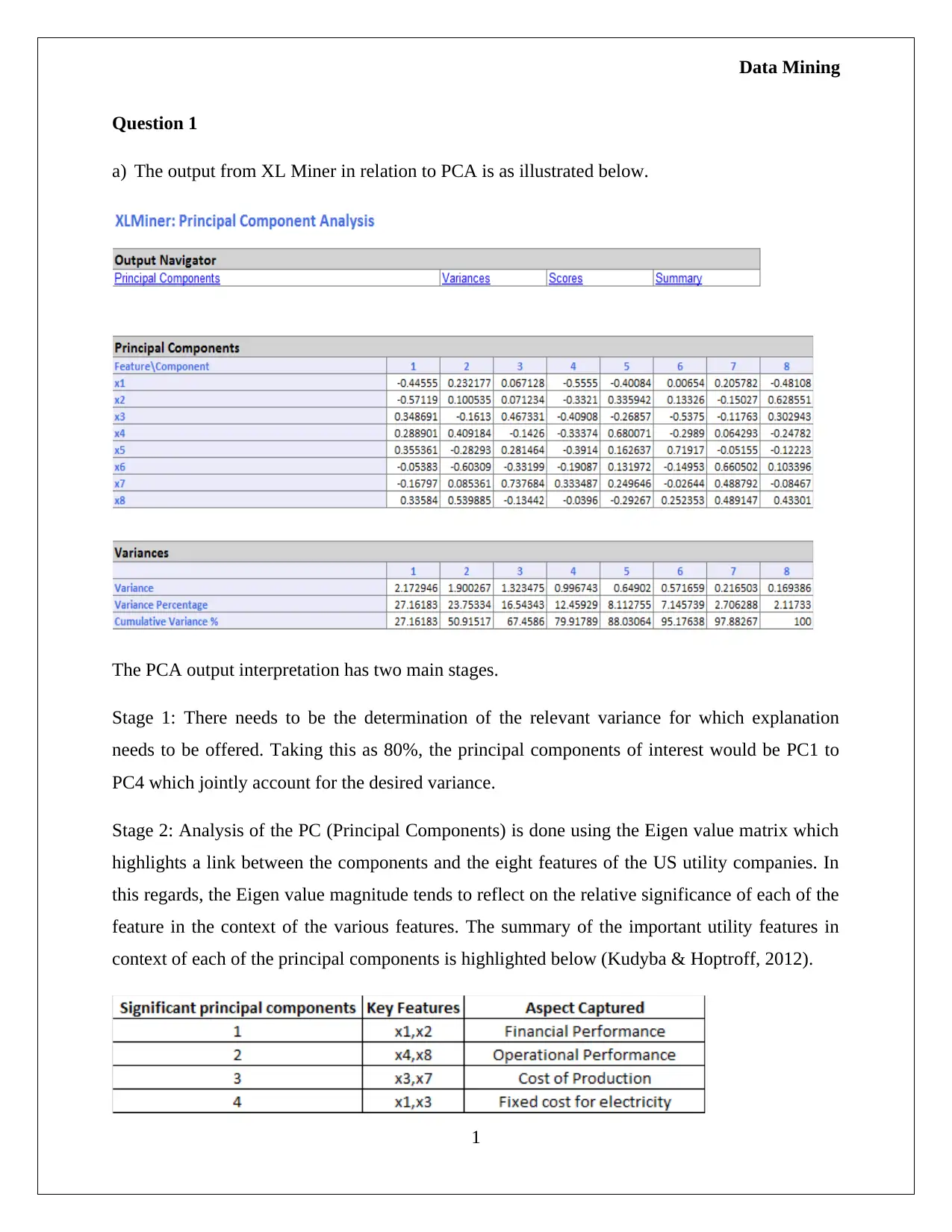
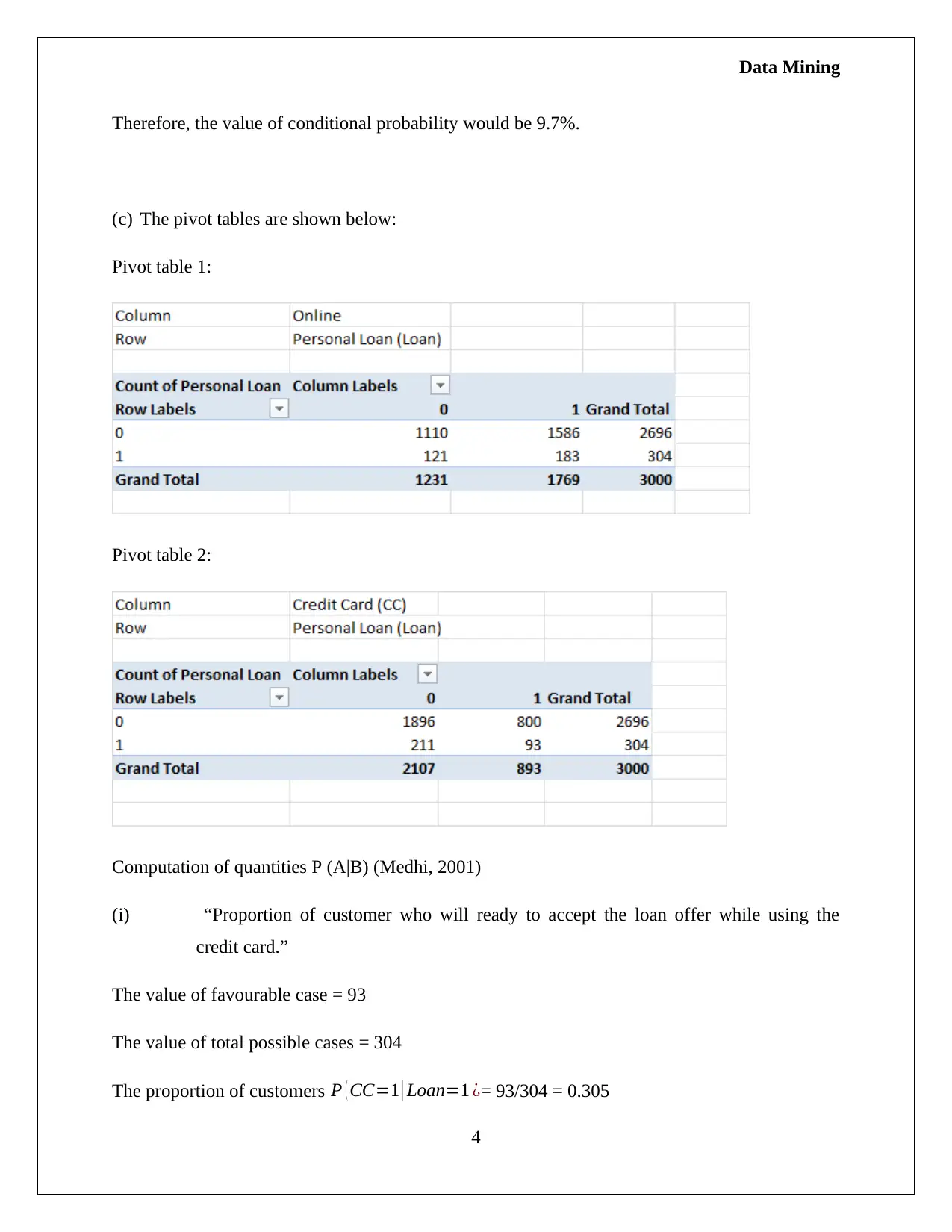
This assignment requires interpreting PCA outputs in the context of US utility companies using XL Miner, focusing on variance explanation and feature significance through eigenvalues. It involves determining principal components accounting for 80% variance and discussing their implications. The task also extends to analyzing a dataset of Universal Bank customers, calculating conditional probabilities related to loan acceptance based on credit card usage and online services, demonstrating the application of data mining techniques in practical scenarios.






1 out of 8
Related Documents






Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Copyright © 2020–2026 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.