ITC563 Data Mining Assignment 2: PCA, Naive Bayes Analysis and Results
VerifiedAdded on 2020/04/01
|8
|1369
|444
Homework Assignment
AI Summary
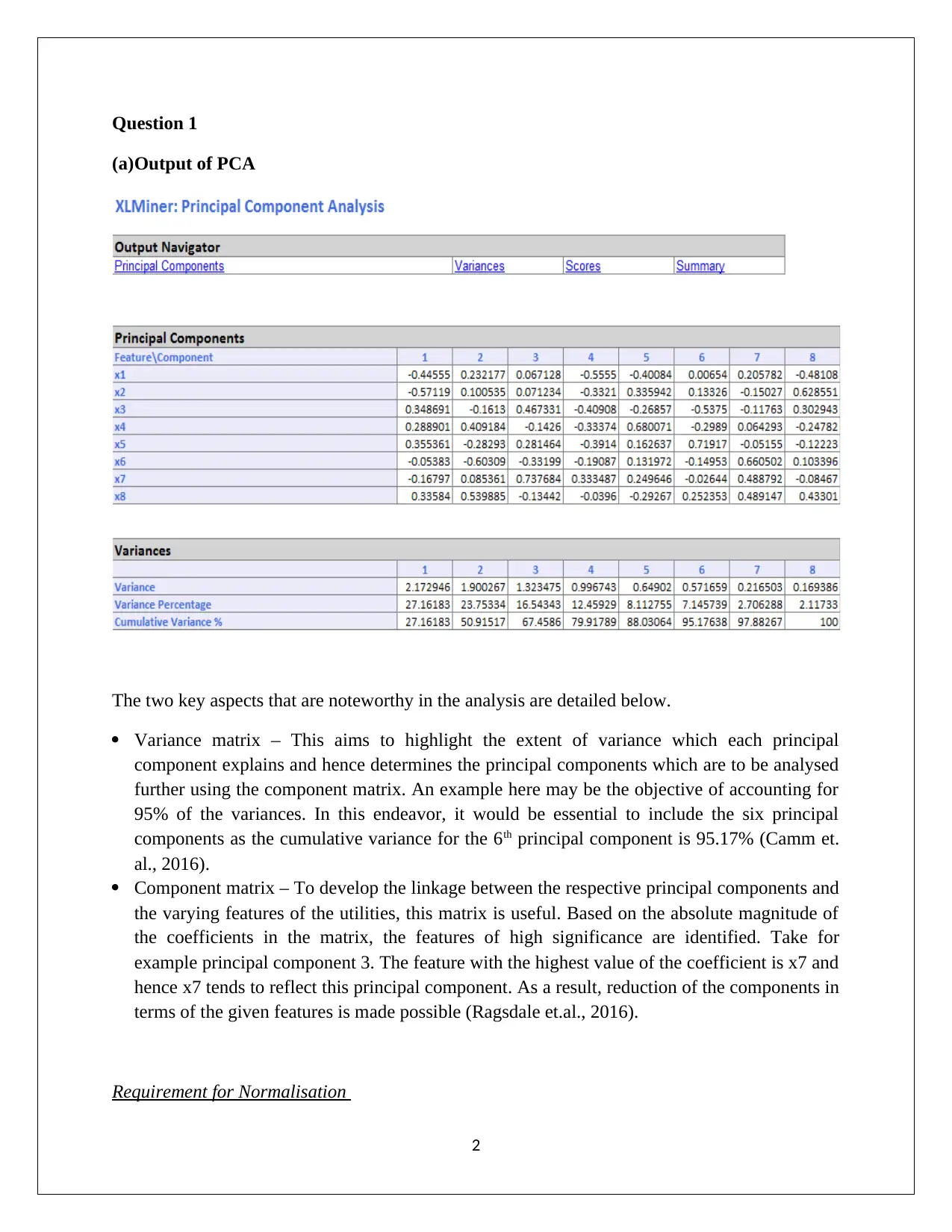
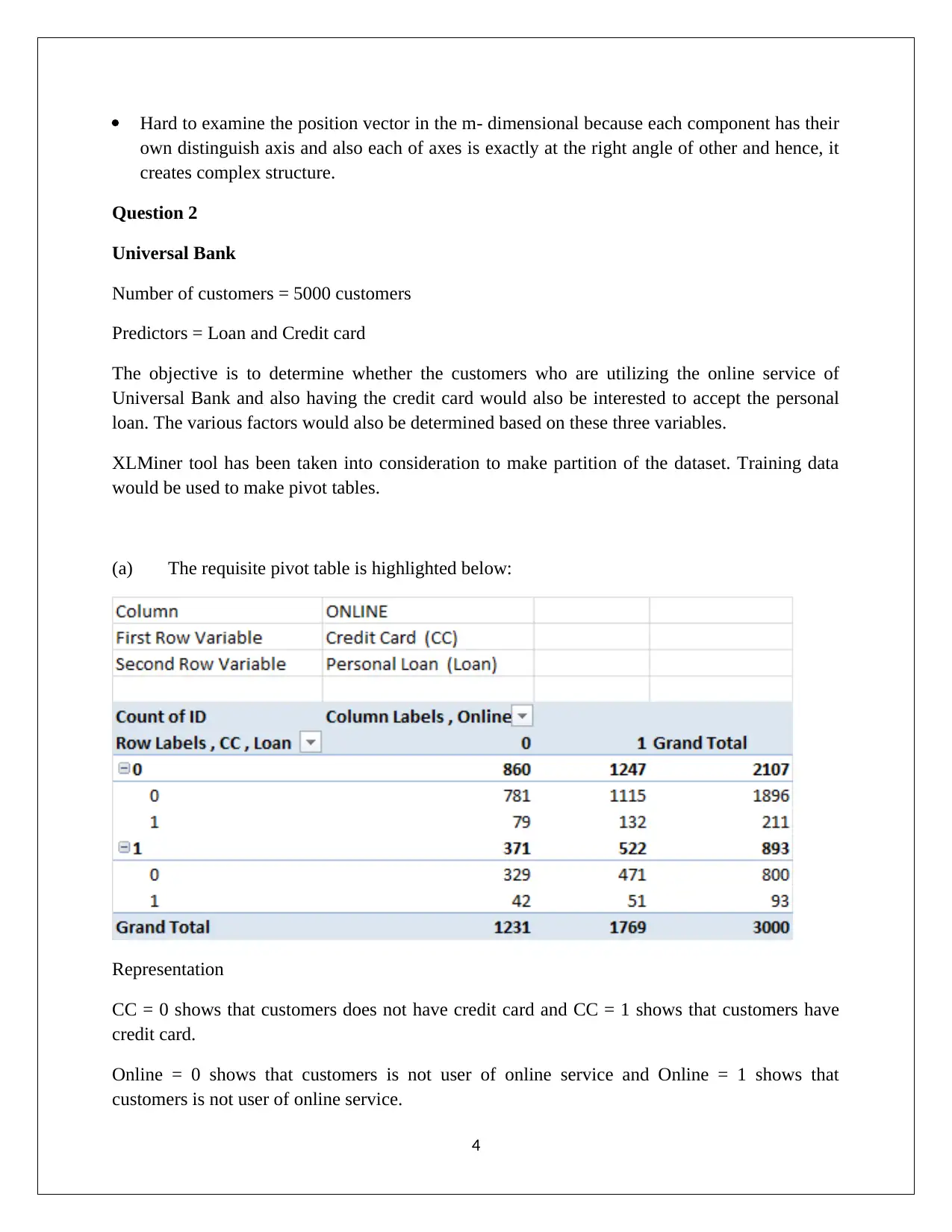
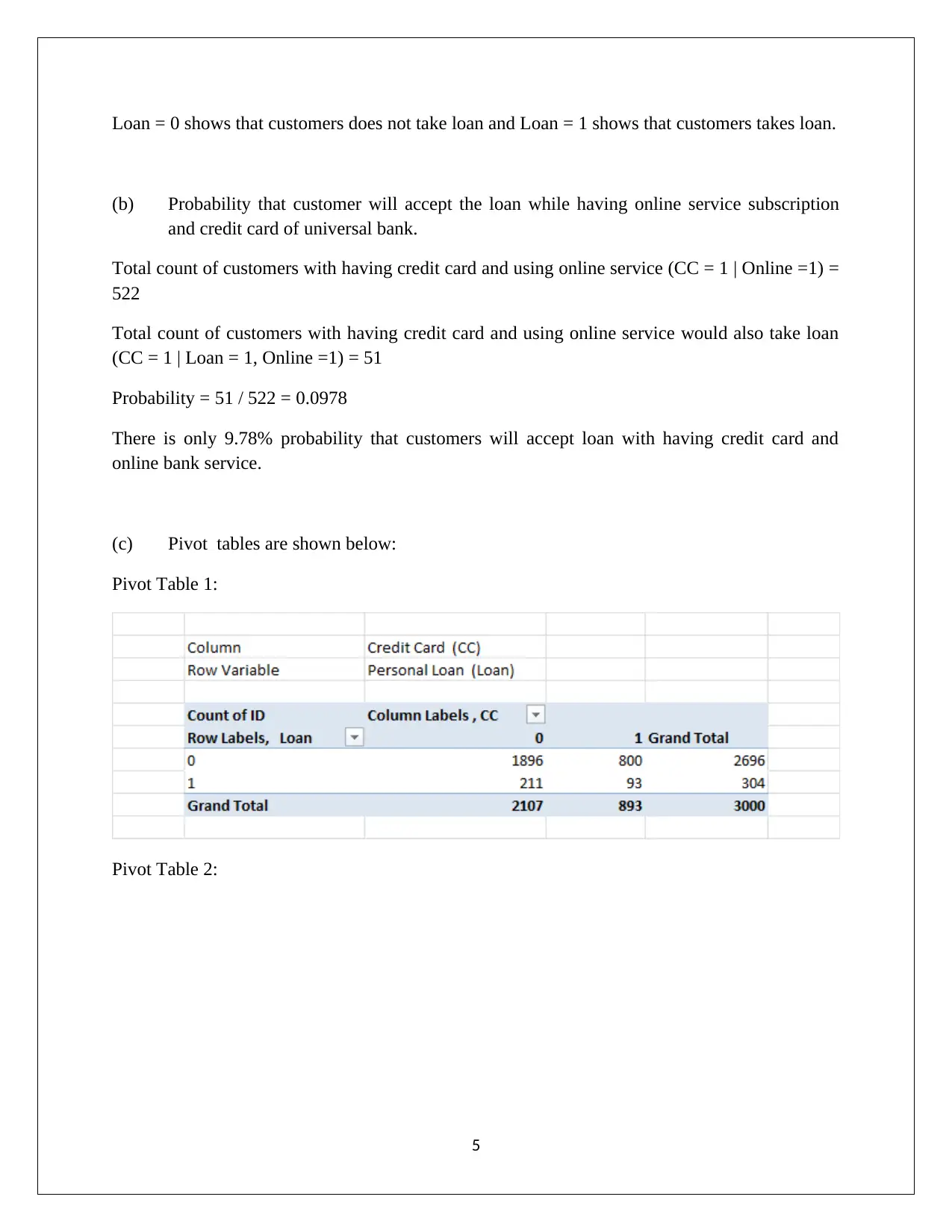
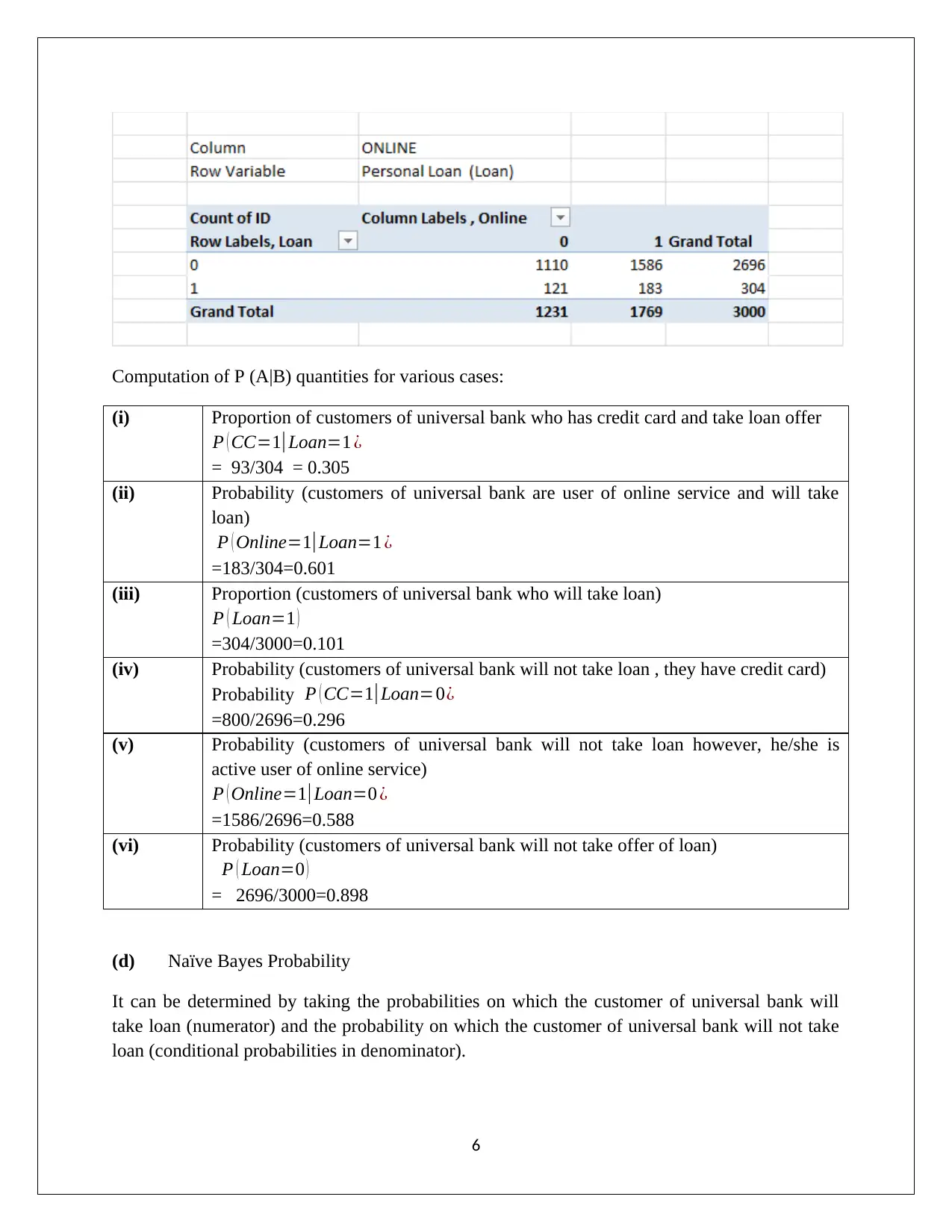
This data mining assignment, submitted by Nipuna Ekanayake, analyzes PCA (Principal Component Analysis) and Naive Bayes techniques using data from Universal Bank. The assignment begins with an examination of PCA, discussing variance matrices, component matrices, and the need for normalization. It outlines the advantages and disadvantages of PCA, including its utility in dimensionality reduction and its limitations in handling non-linear relationships and data distributions. The second part of the assignment focuses on a Universal Bank case study, predicting customer loan acceptance based on credit card usage and online service subscriptions. The analysis involves pivot tables, probability calculations, and Naive Bayes probability to determine the likelihood of customers taking loans under different conditions. The solution identifies key factors for loan offers and suggests strategies to enhance loan acceptance rates. The assignment references several academic sources to support its findings.




1 out of 8
Related Documents






Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Copyright © 2020–2026 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.