Data Mining Project: US Public Utilities and Customer Data
VerifiedAdded on 2019/10/30
|13
|1016
|163
Project
AI Summary
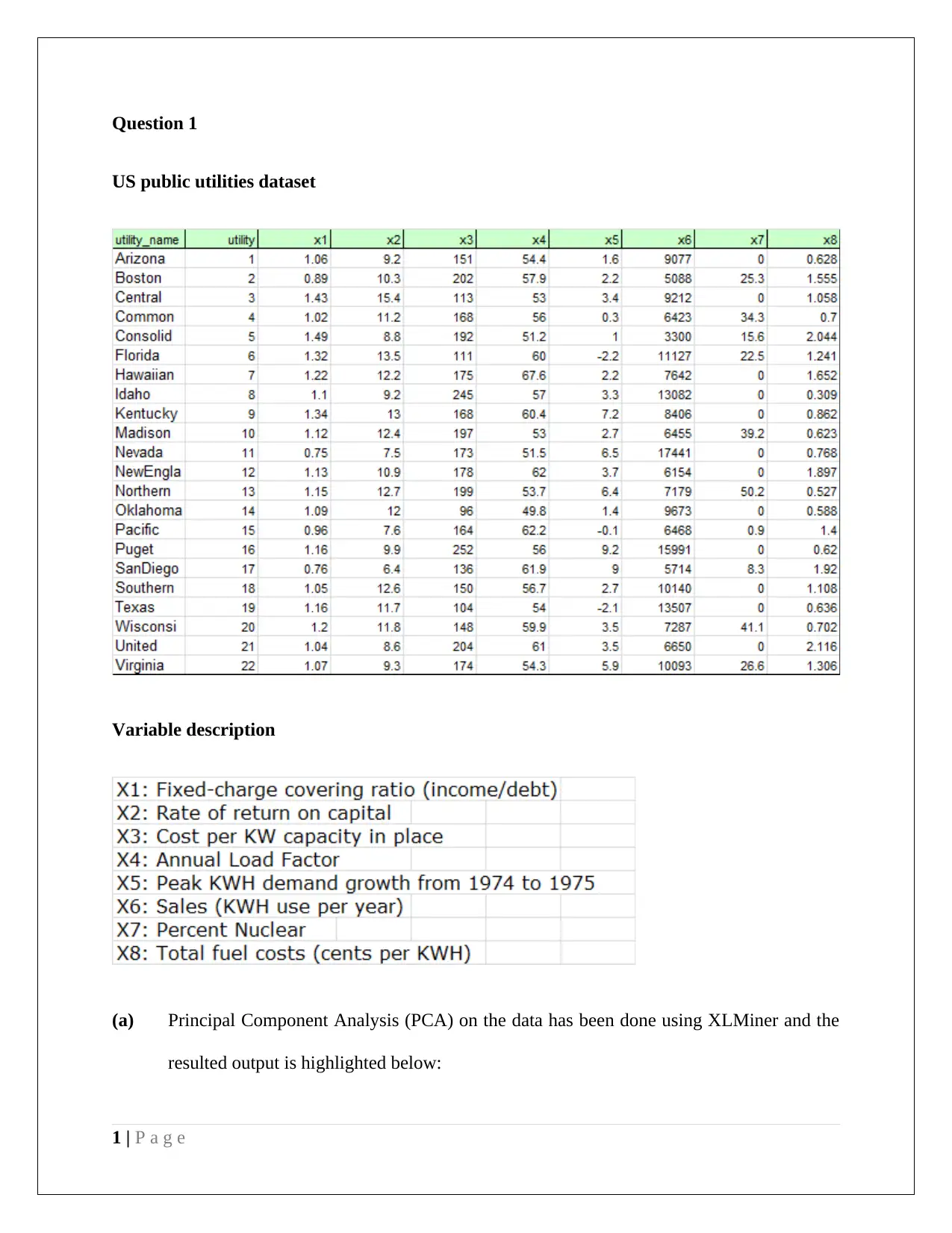
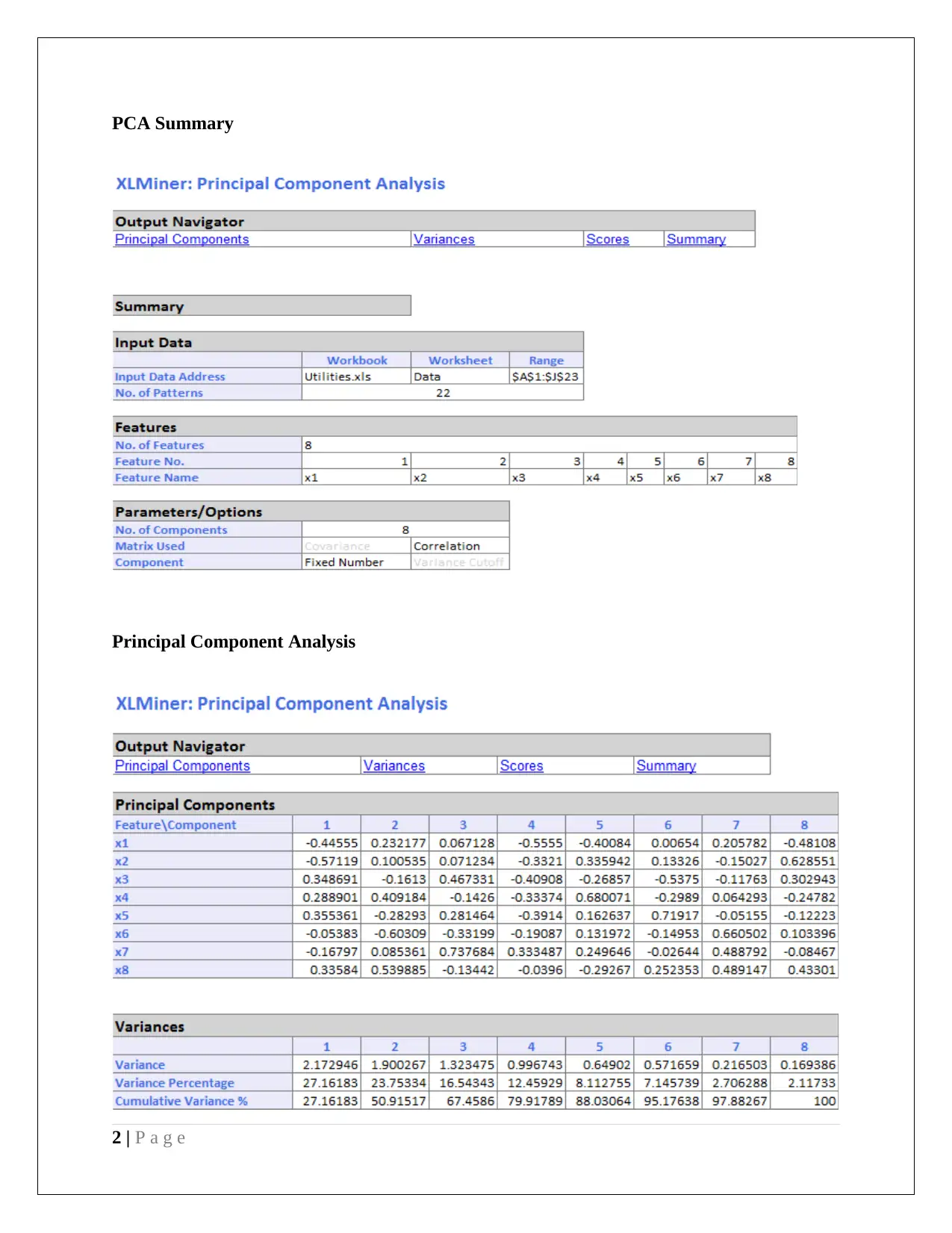
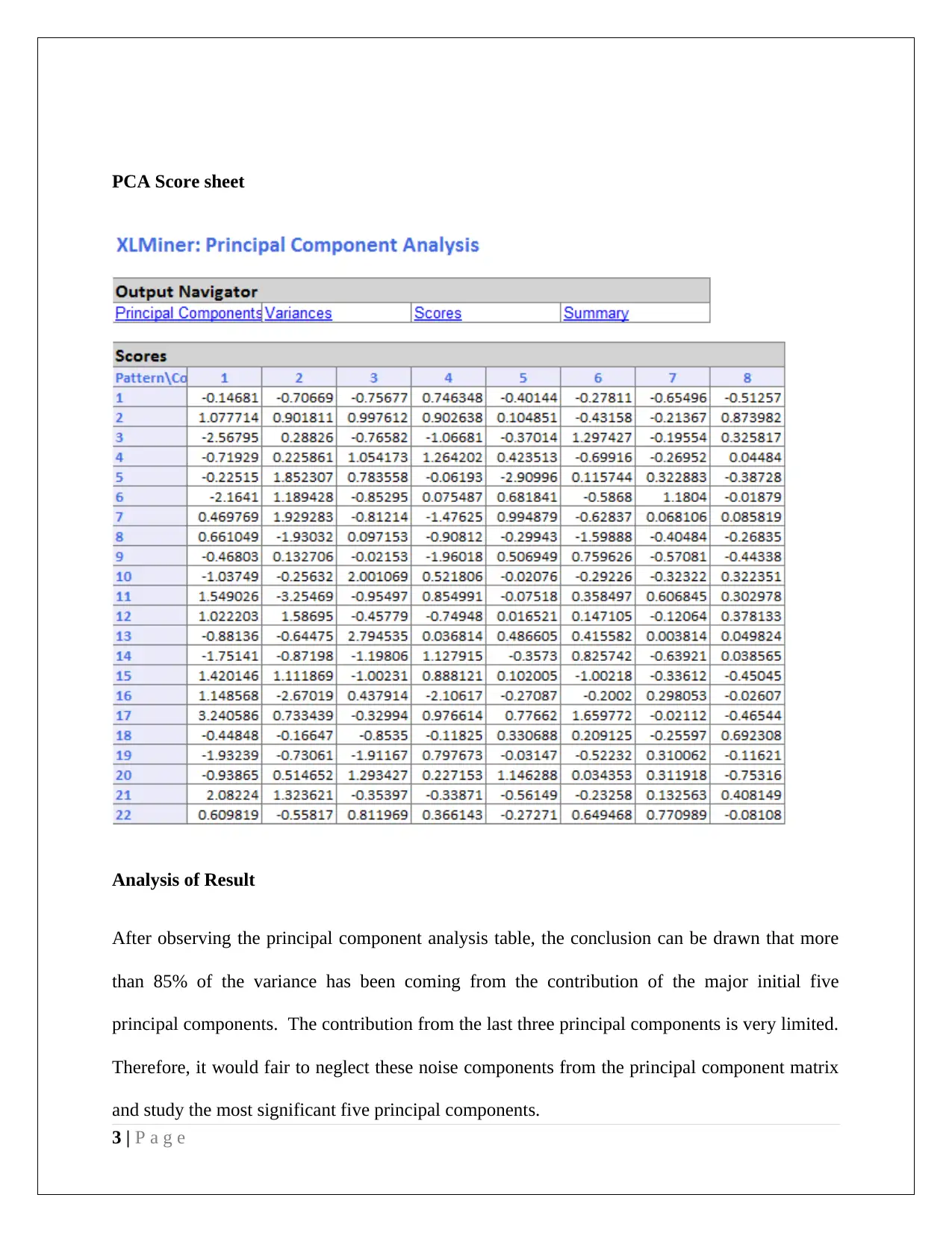
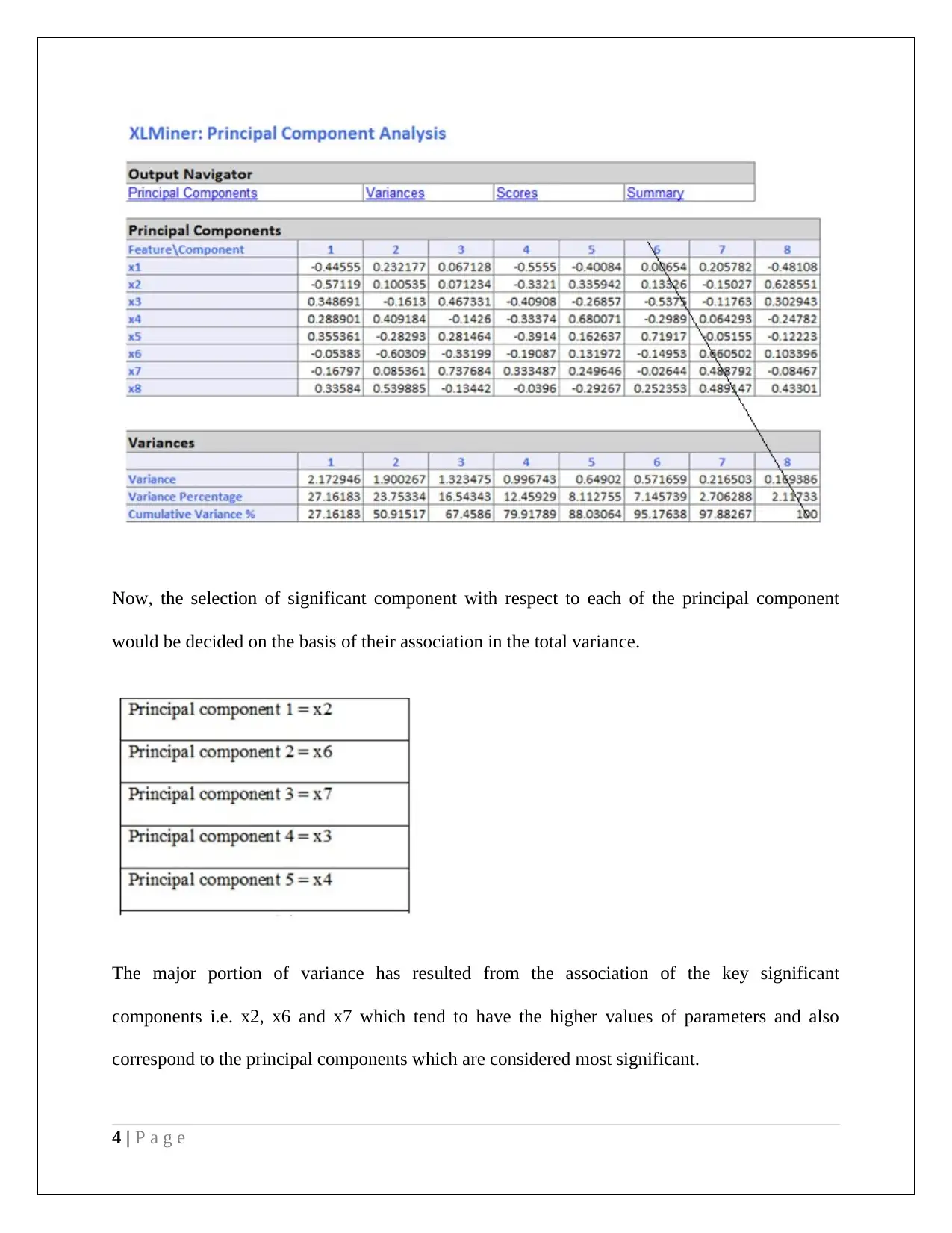
This data mining project analyzes US public utilities and customer data, employing Principal Component Analysis (PCA) and Naive Bayes methods. The PCA section examines variance contributions of principal components, identifying key variables like rate of return on capital, sales, and percent nuclear. It also discusses data normalization and the advantages/disadvantages of PCA. The second part analyzes customer data, using pivot tables to determine the probability of customers accepting personal loans based on credit card usage and online service adoption, applying Naive Bayes probability to derive insights. The analysis includes a partition of data, predictor selection, and probability calculations to maximize loan acceptance, offering a comprehensive business case analysis.








1 out of 13
Related Documents






Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Copyright © 2020–2026 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.