Data Mining and Visualization: Association Rules and Cluster Analysis
VerifiedAdded on 2020/03/16
|6
|972
|133
Homework Assignment
AI Summary
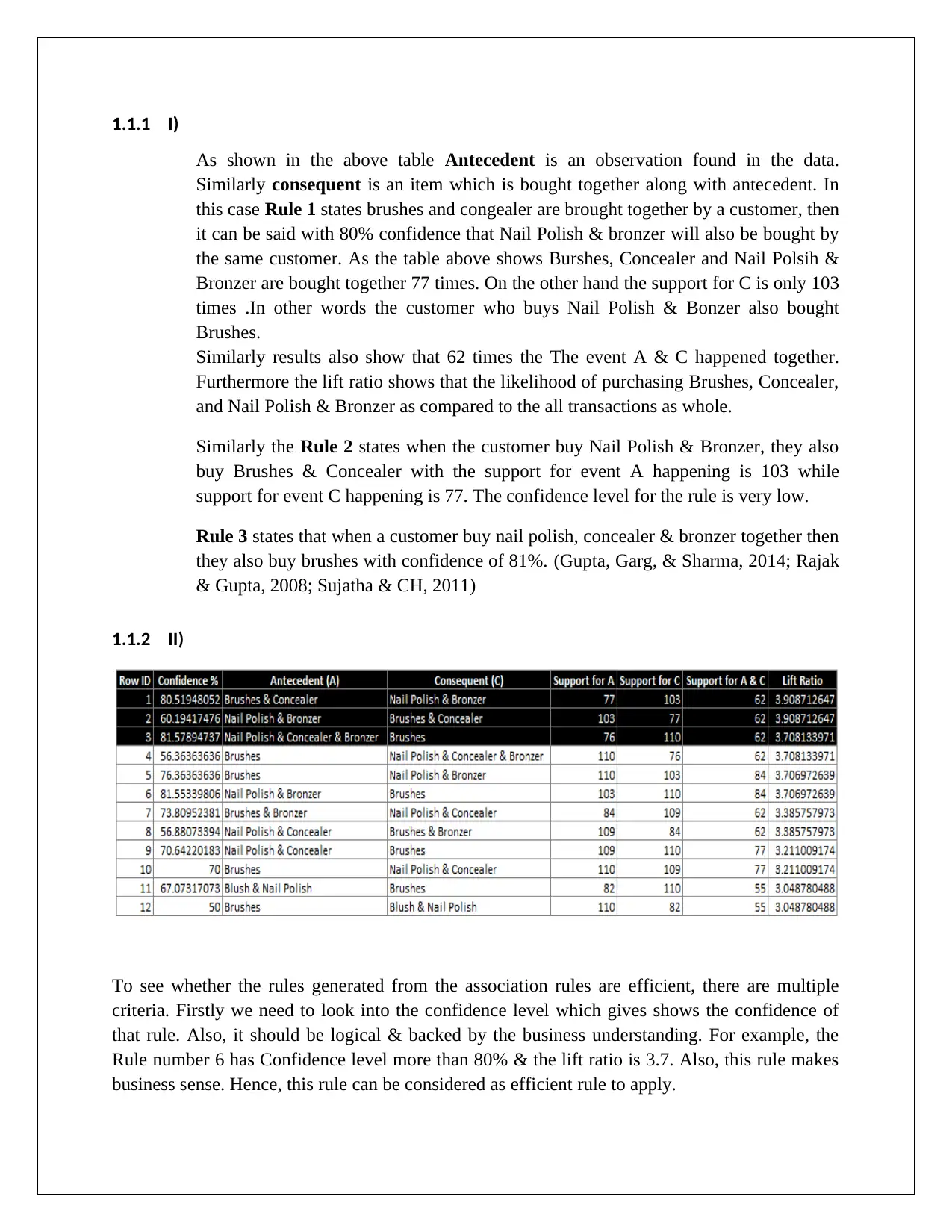
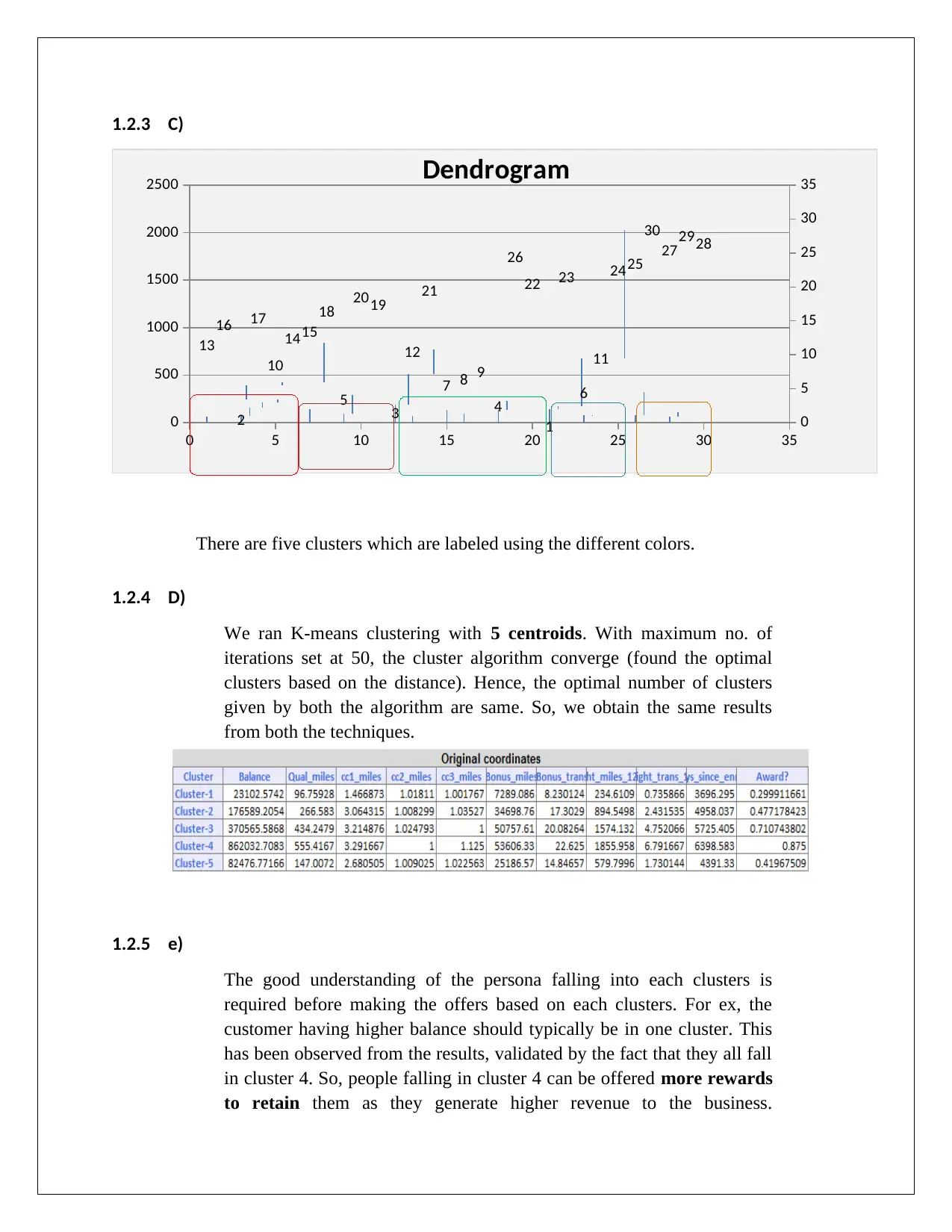
This assignment focuses on data mining and visualization techniques, specifically association rules and cluster analysis, for business intelligence. It covers the application of association rules to identify relationships between items, using metrics like confidence and lift ratio to evaluate rule efficiency. The assignment also explores cluster analysis, employing K-means clustering with XLMiner to segment data into distinct clusters. It highlights the importance of data normalization and understanding cluster characteristics to tailor business strategies, such as offering personalized rewards to retain high-value customers. References to relevant research articles are included to support the analysis. Desklib provides access to this assignment along with a wealth of other study resources.




1 out of 6
Related Documents






Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Copyright © 2020–2026 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.