Data Mining and Data Warehousing Assignment Solution - IT 446
VerifiedAdded on 2022/08/10
|9
|2260
|408
Homework Assignment
AI Summary
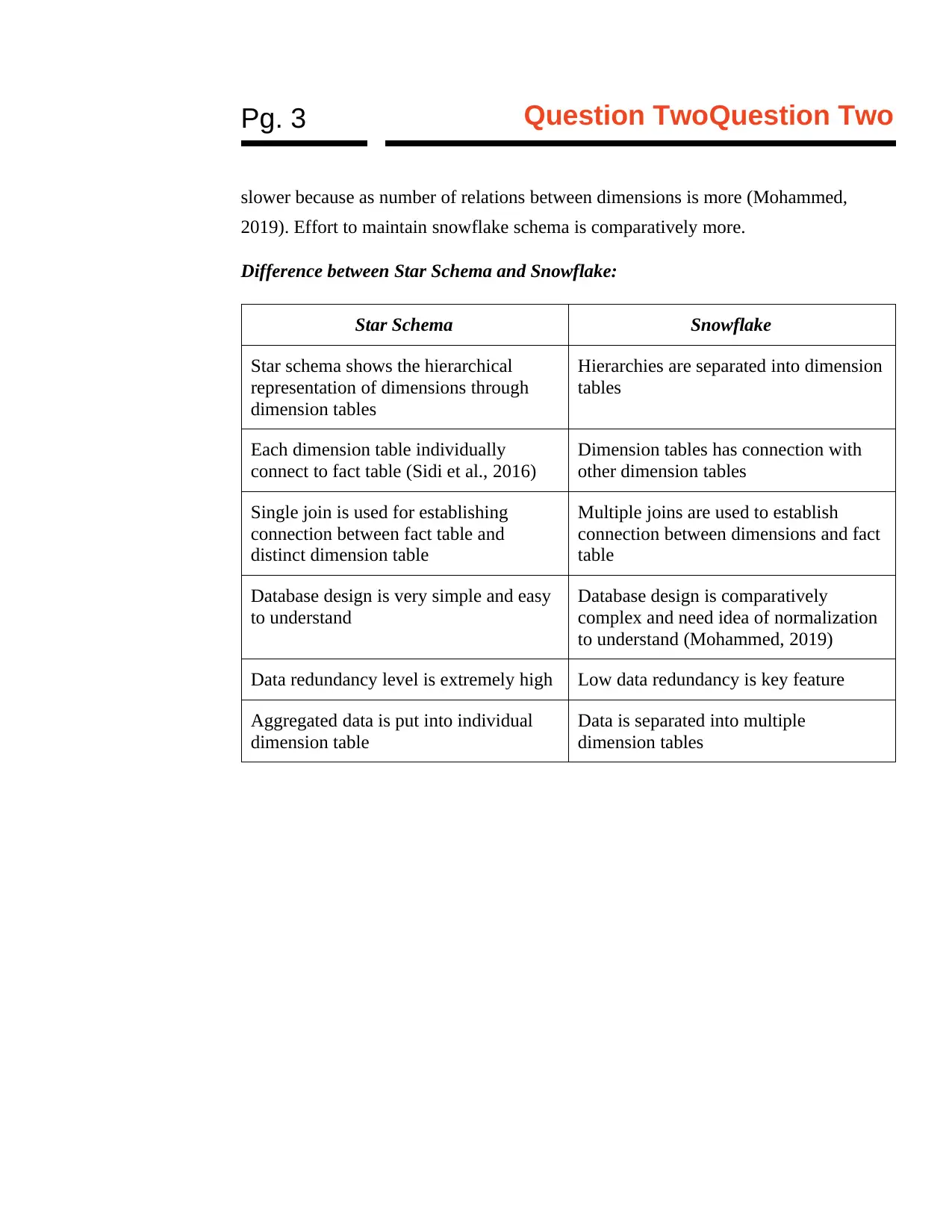
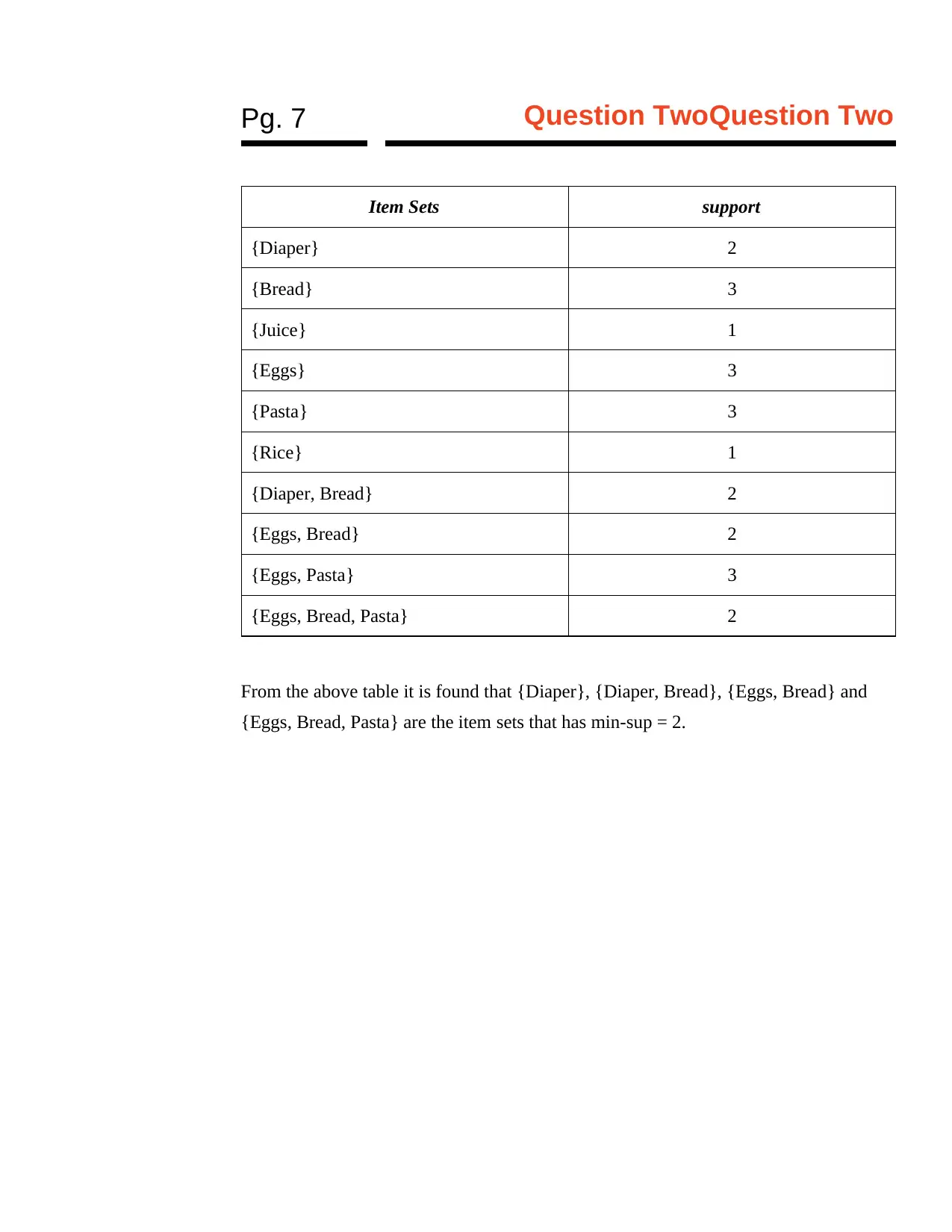
This assignment solution for IT 446, Data Mining and Data Warehousing, addresses several key concepts in the field. The solution begins by comparing and contrasting star and snowflake schemas, explaining their structures, advantages, and disadvantages, including discussions on normalization and query performance. It then delves into view materialization, explaining its purpose and comparing no-materialization, full materialization, and partial materialization approaches, emphasizing the trade-offs between storage usage and query response time. The solution also outlines the differences between the Multi-Way Array Aggregation method and the BUC method in the context of data cube computation, highlighting their distinct approaches to array partitioning and top-down construction. Finally, the solution applies the Apriori algorithm to a transaction database, identifying frequent itemsets with a minimum support of 2, providing a step-by-step analysis of the algorithm's application.







1 out of 9
Related Documents






Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Copyright © 2020–2026 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.