SIT717 2018T2: Enterprise Business Intelligence Data Mining Report
VerifiedAdded on 2023/06/08
|15
|3747
|223
Report
AI Summary
This technical report explores the implementation of supervised data mining within the context of enterprise business intelligence. The report begins with an abstract that introduces the application of supervised data mining for business intelligence, particularly using microblogging data. It then provides an introduction to the background, motivation, and aims of data analytics applications. A literature review provides context on business intelligence and supervised data mining techniques. The report details the dataset used, including quantitative variables and data collection methods. It outlines the methods employed, including information crawling, tokenization, and various data mining techniques such as graph clustering and Markov clustering. The report also discusses data visualization techniques, association rule techniques, and neural network techniques. The evaluation and demonstration section highlights the use of these tools to analyze data and extract meaningful insights. The report concludes by emphasizing the importance of accuracy in supervised information extraction and the use of a Java application for data analysis.

Enterprise Business Intelligence
by (Name)
The Name of the Class (Course)
Professor (Tutor)
The Name of the School (University)
The City and State where it is located
The Date
Topic:
Implementation of Supervised Data Mining in Business Intelligence for the growth and
analysis of managerial role in companies.
by (Name)
The Name of the Class (Course)
Professor (Tutor)
The Name of the School (University)
The City and State where it is located
The Date
Topic:
Implementation of Supervised Data Mining in Business Intelligence for the growth and
analysis of managerial role in companies.
Paraphrase This Document
Need a fresh take? Get an instant paraphrase of this document with our AI Paraphraser

Abstract
The rate of increase in microblogging popularity such as twitter has facilitated users to exchange
messages and information needed for data analysis for different purposes ranging from business
intelligence to the issue of security is one face that is very important to the public. The social
network is being used by a large number of people for events, update and sentiments exploration.
The fact that tweets are given certain structure during tweeting, the messages presented does not
follow grammatical structure and passing techniques due to an increment and speech to an
individual words. This paper presents a proposal of a statistical based approach as well as
identifying significant factors related to modeling of the infrmation. The method presents a
method of generation graph which considers node and the degree of similarity that could exist
between as a weighed edge between the tweets and the way the tweets work. In short and in
summary, the paper is about the business indigence and report made based on supervised data
mining and learning ideas. The supervised data mining is quite different from unsupervised data
mining database. In this case, the data mining data set is not provided to this machine and due to
this, we have to retrieve the data from the social media website.
The rate of increase in microblogging popularity such as twitter has facilitated users to exchange
messages and information needed for data analysis for different purposes ranging from business
intelligence to the issue of security is one face that is very important to the public. The social
network is being used by a large number of people for events, update and sentiments exploration.
The fact that tweets are given certain structure during tweeting, the messages presented does not
follow grammatical structure and passing techniques due to an increment and speech to an
individual words. This paper presents a proposal of a statistical based approach as well as
identifying significant factors related to modeling of the infrmation. The method presents a
method of generation graph which considers node and the degree of similarity that could exist
between as a weighed edge between the tweets and the way the tweets work. In short and in
summary, the paper is about the business indigence and report made based on supervised data
mining and learning ideas. The supervised data mining is quite different from unsupervised data
mining database. In this case, the data mining data set is not provided to this machine and due to
this, we have to retrieve the data from the social media website.

AN INTRODUCTION OF A DATA ANALYTIC APPLICATION BACKGROUND,
MOTIVATION AND AIM
Many people have been attracted with the increase in web technology and the use of social
network to present their ideas and the working of their web projects and services. The online
social networks have become more reach with information purpose that is inclusive for event
such as data sharing. Due to this, business intelligence tools are becoming more powerful online
tool to make companies more comfortable. The Implementation of Supervised Data Mining is
one factors that has attracted business owner’s as well a huge client base. Due to this the
technique has become the most popular micro blogging social sites where users are free share
their view, and their aspirations. By using supervised data mining, business are able to get the
latest trending new from their customer about the attest product.
In this particular paper, statistical approach that is used to supervised data is through the use of
the use graph clustering. All the information is tokenized using n-grams techniques by the use of
certain allocation method. The project uses Latent Distinct allocation method to identify the
significant key terms that are latter used in business generation. The second method that is also
important in this paper is the Markov Cluttering.
Literature Review:
The literature review is basically presented to discuss about business intelligent and supervised
way of data mining technology and its understanding. From several articles on research,
business intelligence is very key in decision making in most of the organizations use. In this
literature part, the research tend to present a detailed discussion on the intelligence and how the
MOTIVATION AND AIM
Many people have been attracted with the increase in web technology and the use of social
network to present their ideas and the working of their web projects and services. The online
social networks have become more reach with information purpose that is inclusive for event
such as data sharing. Due to this, business intelligence tools are becoming more powerful online
tool to make companies more comfortable. The Implementation of Supervised Data Mining is
one factors that has attracted business owner’s as well a huge client base. Due to this the
technique has become the most popular micro blogging social sites where users are free share
their view, and their aspirations. By using supervised data mining, business are able to get the
latest trending new from their customer about the attest product.
In this particular paper, statistical approach that is used to supervised data is through the use of
the use graph clustering. All the information is tokenized using n-grams techniques by the use of
certain allocation method. The project uses Latent Distinct allocation method to identify the
significant key terms that are latter used in business generation. The second method that is also
important in this paper is the Markov Cluttering.
Literature Review:
The literature review is basically presented to discuss about business intelligent and supervised
way of data mining technology and its understanding. From several articles on research,
business intelligence is very key in decision making in most of the organizations use. In this
literature part, the research tend to present a detailed discussion on the intelligence and how the
⊘ This is a preview!⊘
Do you want full access?
Subscribe today to unlock all pages.
Trusted by 1+ million students worldwide

entire idea of business intelligence work to make the work of the managers easier. The data
mining in the recent past has being used very much widely and this has caused the amount of
data in the field to widen and to mark sense of what is done. The data handled by the business
intelligence handles a large number of data and this provides a strategy for the business and new
ideas and opportunities are achieved. Both structured and unstructured data can easily be
handled and this enable us to provide business solutions. Data mining is basically necessary to
help the business to provide a prediction of the entire procedure. Business intelligence has also
fixed several values that can be able to achieve a goal in putting clear form and format of the
business perspective. The theoretical approach in this particular research is to understand a
detailed survey in the supervised data mining.
A SUMMARY OF THE DATASET
The first work that every researcher has to consider before coming up with the data analysis is to
make a solid decision on the data he is yet to deal with. In this case, we have number of
typologies that has proven to us that supervised data mining is a useful tool in business indigence
analysis. One of the method to be used and which is distinctive is the quantitative variables. In
this method, we asked how much data is involved. The variable to be used in this case is known
as the type of data to be inserted in this entire information and collection. Quantitate method in
cost cases can be continuous and discrete.
The method must use quantitative variables and the theory must take certain value that is within
a given range. For instance, we can determine the number of businesses that have used data
mining for the first six months information and how often this information is used based on the
preferences. Data collection must also take place based on the certain value of data that is meant
mining in the recent past has being used very much widely and this has caused the amount of
data in the field to widen and to mark sense of what is done. The data handled by the business
intelligence handles a large number of data and this provides a strategy for the business and new
ideas and opportunities are achieved. Both structured and unstructured data can easily be
handled and this enable us to provide business solutions. Data mining is basically necessary to
help the business to provide a prediction of the entire procedure. Business intelligence has also
fixed several values that can be able to achieve a goal in putting clear form and format of the
business perspective. The theoretical approach in this particular research is to understand a
detailed survey in the supervised data mining.
A SUMMARY OF THE DATASET
The first work that every researcher has to consider before coming up with the data analysis is to
make a solid decision on the data he is yet to deal with. In this case, we have number of
typologies that has proven to us that supervised data mining is a useful tool in business indigence
analysis. One of the method to be used and which is distinctive is the quantitative variables. In
this method, we asked how much data is involved. The variable to be used in this case is known
as the type of data to be inserted in this entire information and collection. Quantitate method in
cost cases can be continuous and discrete.
The method must use quantitative variables and the theory must take certain value that is within
a given range. For instance, we can determine the number of businesses that have used data
mining for the first six months information and how often this information is used based on the
preferences. Data collection must also take place based on the certain value of data that is meant
Paraphrase This Document
Need a fresh take? Get an instant paraphrase of this document with our AI Paraphraser

to be gathered. the type of data gathered in this case is row data and must be transferred in a
more readable and understand way. The data was collected using a questionnaire and every
information coded in a well presented and developed software. After coding the data, graphs and
histograms were drown that depicts the data collected.
METHODS
This section presents functional details for all the unsupervised data mining and approach that is
used to get the information about the business. To make the work easy for the users, the methods
is presented in a workflow all the methods that are highlighted. One of the method to be used is
the information crawling, information tokenization to analyze the business contents and remove
unwanted contents. There are several methods of data collection that will be of important to this
research. One such method includes: sampling, one of the method to be used is sampling method.
Sampling enable the researchers to gather information from a vast area and to make sure that the
information gathered is well understood by the researcher. Secondly the information is also
viewed as the first hand information because it comes directly from the people who uses social
media on a daily basis.
The choice of data mining techniques was guided by the focus on the most current and the most
used models in the market. In this section, the review come up with some of the features and
different techniques and determination on how they affect and influence the supervised data. The
method does not presents a complete mathematical details of the entire algorithm or even their
implementation. Below are data mining techniques that are used to explain this classification.
THE MAIN DATA MINING TECHNIQUES
more readable and understand way. The data was collected using a questionnaire and every
information coded in a well presented and developed software. After coding the data, graphs and
histograms were drown that depicts the data collected.
METHODS
This section presents functional details for all the unsupervised data mining and approach that is
used to get the information about the business. To make the work easy for the users, the methods
is presented in a workflow all the methods that are highlighted. One of the method to be used is
the information crawling, information tokenization to analyze the business contents and remove
unwanted contents. There are several methods of data collection that will be of important to this
research. One such method includes: sampling, one of the method to be used is sampling method.
Sampling enable the researchers to gather information from a vast area and to make sure that the
information gathered is well understood by the researcher. Secondly the information is also
viewed as the first hand information because it comes directly from the people who uses social
media on a daily basis.
The choice of data mining techniques was guided by the focus on the most current and the most
used models in the market. In this section, the review come up with some of the features and
different techniques and determination on how they affect and influence the supervised data. The
method does not presents a complete mathematical details of the entire algorithm or even their
implementation. Below are data mining techniques that are used to explain this classification.
THE MAIN DATA MINING TECHNIQUES

Research has shown that supervised data mining is the best method to perform data mining
activities. This is because every user has specific target when performing this type of data
mining. The results may be different at different times and the target may be numeric. In real
sense supervised data mining may be used when the user is having an ideal subset of data points.
When this data is used for building a model such as typical data points even when it is targeting
different targets. The supervised data classification is started as the main method. The
classification can be of different types especial when applied to different business. Other method
such as regression can also be used to a target value as per the numerical as opposed to
performing data categories. All the values must be assessed through the use of the organization
in order for the entire data to get all the desired outcomes. The process is also known the
predictive data mining because it has capability to proceed the user data and numerical.
Visualization Techniques
Visualization techniques is used because it is a very useful method for discovering partners in the
data sets and may be actually used at the begging of the data mining process. In this technique,
there is a whole field of research that is dedicated to the search of the projection that the user is
interested in. This projection is also known as the projection pursuit. For instance the cluster are
usually numerically represented by different numerical reprobation. There are a large set of rules
when dealing with the structure information classification and hierarchical fashion in the
graphical. The visualization will help to discover the meaningful patterns of the good business
intelligence and how the information will be supervised. Visualization also classify the entire
work into a meaningful interpretable data. This is in line with the goals of visualization which is
to permit a wide variety of data mining methods to be used successfully.
Association Rule Techniques.
activities. This is because every user has specific target when performing this type of data
mining. The results may be different at different times and the target may be numeric. In real
sense supervised data mining may be used when the user is having an ideal subset of data points.
When this data is used for building a model such as typical data points even when it is targeting
different targets. The supervised data classification is started as the main method. The
classification can be of different types especial when applied to different business. Other method
such as regression can also be used to a target value as per the numerical as opposed to
performing data categories. All the values must be assessed through the use of the organization
in order for the entire data to get all the desired outcomes. The process is also known the
predictive data mining because it has capability to proceed the user data and numerical.
Visualization Techniques
Visualization techniques is used because it is a very useful method for discovering partners in the
data sets and may be actually used at the begging of the data mining process. In this technique,
there is a whole field of research that is dedicated to the search of the projection that the user is
interested in. This projection is also known as the projection pursuit. For instance the cluster are
usually numerically represented by different numerical reprobation. There are a large set of rules
when dealing with the structure information classification and hierarchical fashion in the
graphical. The visualization will help to discover the meaningful patterns of the good business
intelligence and how the information will be supervised. Visualization also classify the entire
work into a meaningful interpretable data. This is in line with the goals of visualization which is
to permit a wide variety of data mining methods to be used successfully.
Association Rule Techniques.
⊘ This is a preview!⊘
Do you want full access?
Subscribe today to unlock all pages.
Trusted by 1+ million students worldwide

The association rule will tell us about the association that exist between two or more data. For
instance when there are two similar methods that is coming from the managers, the association
rule will help the analysis determine the association. The main task determined by association
rule is to find out the presence of various items that is within ascertain databases. For us to use
this rule successfully, two pieces of information must be put into consideration. The first is to
make sure that there is support were the rule lies (Chattamvelli, 2011 pg345). There must be
confident level of confident level and how often the rule is correct. The rule is considered to be
two-step process. The first step it t find the frequent information from the website and the second
if to define each and every items presented. The items in question will occur as frequent as the
association of the two tweets to be analyzed.
Neural Network Technique
The artificial and neural network are called this name because of historical development that
stated with the knowledge that machine can be due to this and do things lie human beings. This
was possible only if the scientist can find a way to mimic its structure and its functioning the way
human being are functioning. To use this techniques to analyst the data, the researcher uses two
main techniques and this two techniques corresponds to human brain and link. It also
corresponds to the neurons and the human brain at all points. A neuron network in this case
would be considered as a connection of all information about the supervised data mining. When
this information is analyzed by the experts, the connection becomes unidirectional. Research has
shown that the arrangement of neuron network have a corresponding architecture and different
neuron network architecture definitely use different leaning procedures to find the strengths of
interconnections. In this regard, there are several number of neural networks and each and every
instance when there are two similar methods that is coming from the managers, the association
rule will help the analysis determine the association. The main task determined by association
rule is to find out the presence of various items that is within ascertain databases. For us to use
this rule successfully, two pieces of information must be put into consideration. The first is to
make sure that there is support were the rule lies (Chattamvelli, 2011 pg345). There must be
confident level of confident level and how often the rule is correct. The rule is considered to be
two-step process. The first step it t find the frequent information from the website and the second
if to define each and every items presented. The items in question will occur as frequent as the
association of the two tweets to be analyzed.
Neural Network Technique
The artificial and neural network are called this name because of historical development that
stated with the knowledge that machine can be due to this and do things lie human beings. This
was possible only if the scientist can find a way to mimic its structure and its functioning the way
human being are functioning. To use this techniques to analyst the data, the researcher uses two
main techniques and this two techniques corresponds to human brain and link. It also
corresponds to the neurons and the human brain at all points. A neuron network in this case
would be considered as a connection of all information about the supervised data mining. When
this information is analyzed by the experts, the connection becomes unidirectional. Research has
shown that the arrangement of neuron network have a corresponding architecture and different
neuron network architecture definitely use different leaning procedures to find the strengths of
interconnections. In this regard, there are several number of neural networks and each and every
Paraphrase This Document
Need a fresh take? Get an instant paraphrase of this document with our AI Paraphraser

model poses its own strengths as well as weakness when it come to the analysis of the data. All
in all the analysis procedure was found effective because the data gathered was accurate and
maximum concentration was done to ensure that there is not error in the analysis.
EVALUATION AND DEMONSTRATION
This part demonstrate that use of the three tools to analysis data and come up with meaningful
information about the data in question. It is important to note that information given in this case
should be relevant and in line with the results. Supervised information extraction is a process that
needs so much accuracy because there are so many opinion posted by the users. The users we
such the data to analyze should be users who are reliable and the information posted by this users
should not be vague. For the purpose of evaluation each and every information given to by the
users was labeled and related business were assembled. A java application is also developed to
ensure that the values are well calculated and all the metrics recorded way.
The paper provides a description of selected techniques from the data mining point of view.
Evaluation team has noticed that all the data mining techniques had to accomplish the wrk of
supervised data in addition the was integrated by the researchers. However, each and every data
collected from the website had their own characteristics which is seen to be unique from the rest
of the information. It is claimed that there are new research solutions needed for each and every
unique problem. The data mining told used has proven itself to be the best told and has better
suited the same problem solving techniques. Evaluation team recommends that we should use
data mining tool for each and every evaluation and to make sure that every data helps in making
the correct decision.
Performing such an analysis is has proven to be technical due to unstructured nature of the report
and the nature of information that are received from different businesses. Many people presents
in all the analysis procedure was found effective because the data gathered was accurate and
maximum concentration was done to ensure that there is not error in the analysis.
EVALUATION AND DEMONSTRATION
This part demonstrate that use of the three tools to analysis data and come up with meaningful
information about the data in question. It is important to note that information given in this case
should be relevant and in line with the results. Supervised information extraction is a process that
needs so much accuracy because there are so many opinion posted by the users. The users we
such the data to analyze should be users who are reliable and the information posted by this users
should not be vague. For the purpose of evaluation each and every information given to by the
users was labeled and related business were assembled. A java application is also developed to
ensure that the values are well calculated and all the metrics recorded way.
The paper provides a description of selected techniques from the data mining point of view.
Evaluation team has noticed that all the data mining techniques had to accomplish the wrk of
supervised data in addition the was integrated by the researchers. However, each and every data
collected from the website had their own characteristics which is seen to be unique from the rest
of the information. It is claimed that there are new research solutions needed for each and every
unique problem. The data mining told used has proven itself to be the best told and has better
suited the same problem solving techniques. Evaluation team recommends that we should use
data mining tool for each and every evaluation and to make sure that every data helps in making
the correct decision.
Performing such an analysis is has proven to be technical due to unstructured nature of the report
and the nature of information that are received from different businesses. Many people presents

their own opinion based on the data is to be used in the analysis. Users in most cases strive to
express communication but are blocked by the users. One of the key issues that is presented in
analyzing data is there classification which is based on the subject in discussion. Information is
normally conceptualized using a different set of significant within the data. Every events
analysis is handled using the key terms and details to make the user and the reader understand
what is meant by each and every definition.
According to most companies, the above techniques helps managers to make decision according
to the information that is provided and classified. There is no techniques that can be presented
and can be made effective apart from simple supervised solution. One reason why the three
techniques were chosen is because there can be no one techniques which can be effective and can
give the results as expected. The evaluation suggest the three techniques be used in corporation
with each other.
Apart from the events and social notification, the supervised data mining is also used for other
purposes such as the product marketing, political campaign and market research. Users are also
able to express their own opinion about a product without any victimization. Performing certain
analysis to business also sport and the emerging issue s in the society is one key factor the assess
a public opinion that concerns the events of a considerable interest to various parties such as the
government, and the security agencies. Vast and wide relevant information projected by millions
of users.
The following observation was deduced from the application it is important that the researchers
have their knowledge and the goals of the people who are posting information on the social
media. That helped in creating data set and selecting data set as well as focusing on the variable
subsets or even data which is yet to be performed. Preparation also needs data cleaning and
express communication but are blocked by the users. One of the key issues that is presented in
analyzing data is there classification which is based on the subject in discussion. Information is
normally conceptualized using a different set of significant within the data. Every events
analysis is handled using the key terms and details to make the user and the reader understand
what is meant by each and every definition.
According to most companies, the above techniques helps managers to make decision according
to the information that is provided and classified. There is no techniques that can be presented
and can be made effective apart from simple supervised solution. One reason why the three
techniques were chosen is because there can be no one techniques which can be effective and can
give the results as expected. The evaluation suggest the three techniques be used in corporation
with each other.
Apart from the events and social notification, the supervised data mining is also used for other
purposes such as the product marketing, political campaign and market research. Users are also
able to express their own opinion about a product without any victimization. Performing certain
analysis to business also sport and the emerging issue s in the society is one key factor the assess
a public opinion that concerns the events of a considerable interest to various parties such as the
government, and the security agencies. Vast and wide relevant information projected by millions
of users.
The following observation was deduced from the application it is important that the researchers
have their knowledge and the goals of the people who are posting information on the social
media. That helped in creating data set and selecting data set as well as focusing on the variable
subsets or even data which is yet to be performed. Preparation also needs data cleaning and
⊘ This is a preview!⊘
Do you want full access?
Subscribe today to unlock all pages.
Trusted by 1+ million students worldwide

processing for instance removing noise, or deciding on the best strategies of reducing noise in the
data set.
Data reduction was also done to reduce or to remove some of the attributes a process the will
help suit the set to the goal. Next is choosing the data mining task. This is determined whether
the goal of KDD is well achieved. After data reduction and isolation, the best algorithm is
chooses for the best method to be used for searching patterns in the data. This process also
involves deciding the appropriate model and pattern. Finally is data mining for the information
and for the representational messages is done. This messages are presented in different formats,
and all the rules that are involves are specified accruing to the work that is mean to be achieved
in the particular data. Extracting useful information from the data and information has become
very much easier than collecting information. In this regard, many people have adopted
sophisticated techniques and as developed those in a multidiscipline field of data mining which is
done in a datasets. When adopting this techniques, one of the key issue is to understand that one
of the most difficult activity is to chosen to suit a given problem. For this, modeling application,
a more generalized way was adopted to ensure that information extraction was done in the
correct manner. A generalized data mining approach is found to improve the information
extraction and information accuracy as well as cost effectiveness of the information to be taken
care of the information.
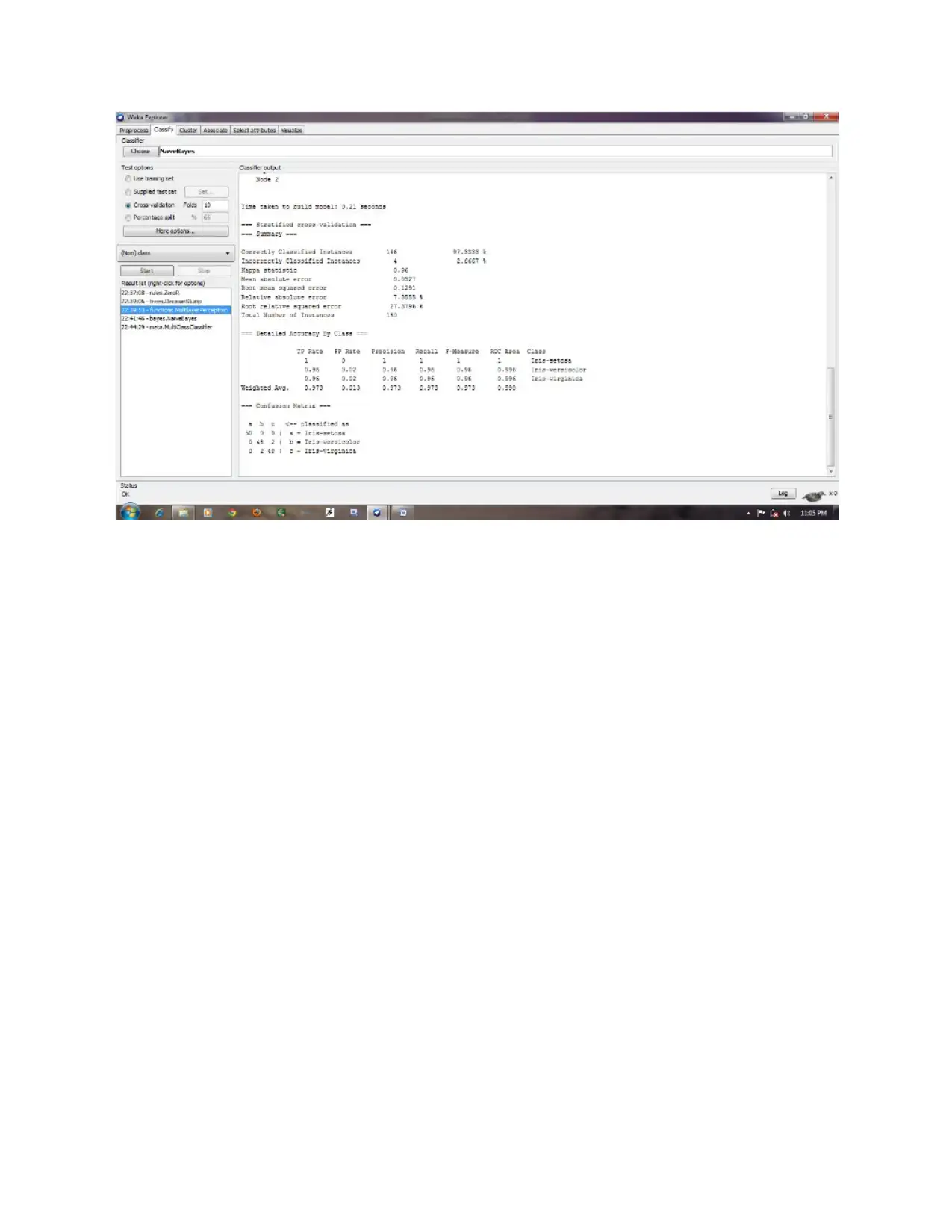
Part C
Weka screenshots.
data set.
Data reduction was also done to reduce or to remove some of the attributes a process the will
help suit the set to the goal. Next is choosing the data mining task. This is determined whether
the goal of KDD is well achieved. After data reduction and isolation, the best algorithm is
chooses for the best method to be used for searching patterns in the data. This process also
involves deciding the appropriate model and pattern. Finally is data mining for the information
and for the representational messages is done. This messages are presented in different formats,
and all the rules that are involves are specified accruing to the work that is mean to be achieved
in the particular data. Extracting useful information from the data and information has become
very much easier than collecting information. In this regard, many people have adopted
sophisticated techniques and as developed those in a multidiscipline field of data mining which is
done in a datasets. When adopting this techniques, one of the key issue is to understand that one
of the most difficult activity is to chosen to suit a given problem. For this, modeling application,
a more generalized way was adopted to ensure that information extraction was done in the
correct manner. A generalized data mining approach is found to improve the information
extraction and information accuracy as well as cost effectiveness of the information to be taken
care of the information.
Part C
Weka screenshots.
Paraphrase This Document
Need a fresh take? Get an instant paraphrase of this document with our AI Paraphraser
⊘ This is a preview!⊘
Do you want full access?
Subscribe today to unlock all pages.
Trusted by 1+ million students worldwide
1 out of 15
Related Documents





Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Unlock your academic potential
Copyright © 2020–2026 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.