CP600038E - Customer Loyalty Analysis Using Data Mining Technologies
VerifiedAdded on 2020/04/15
|15
|3085
|68
Report
AI Summary
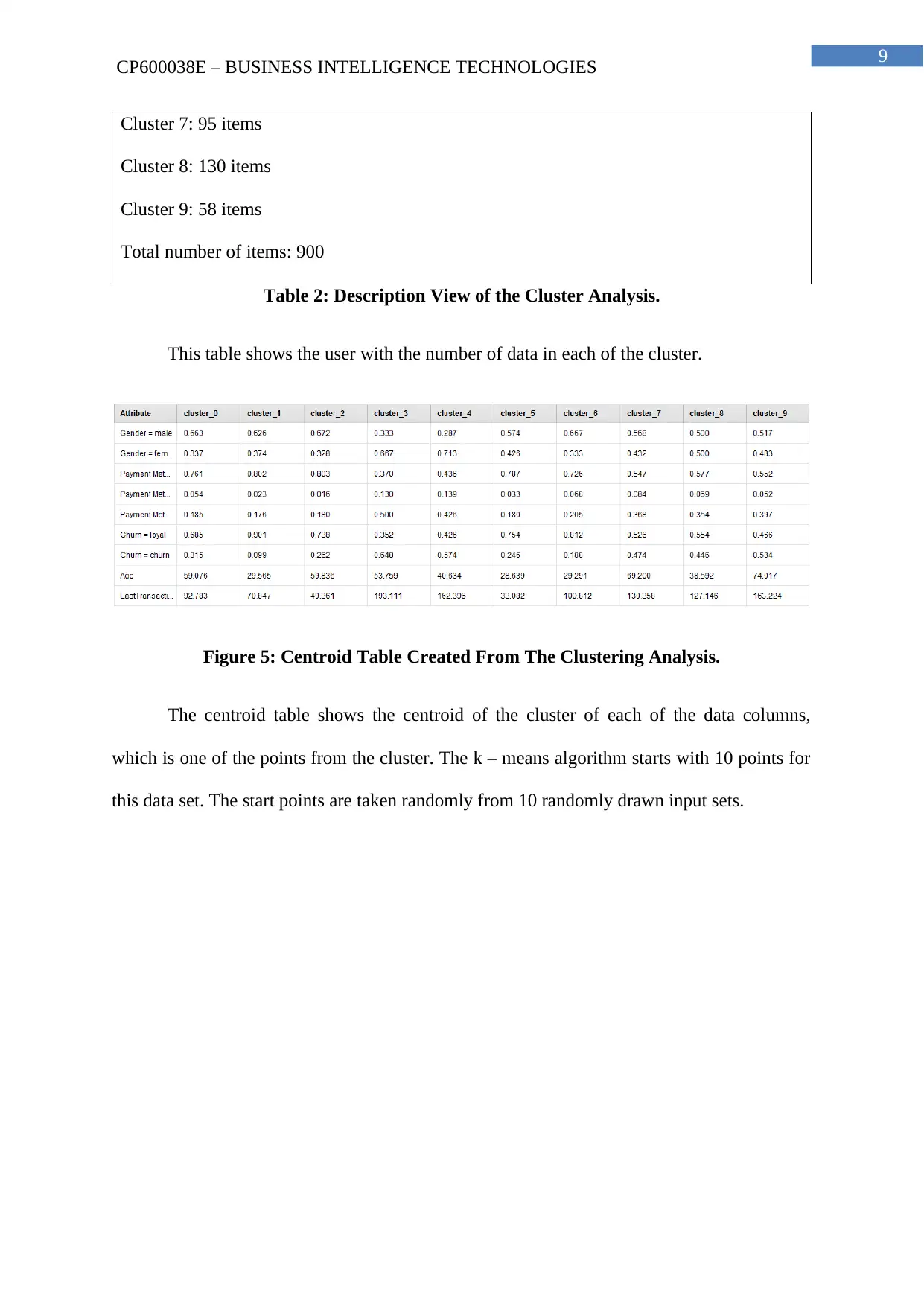
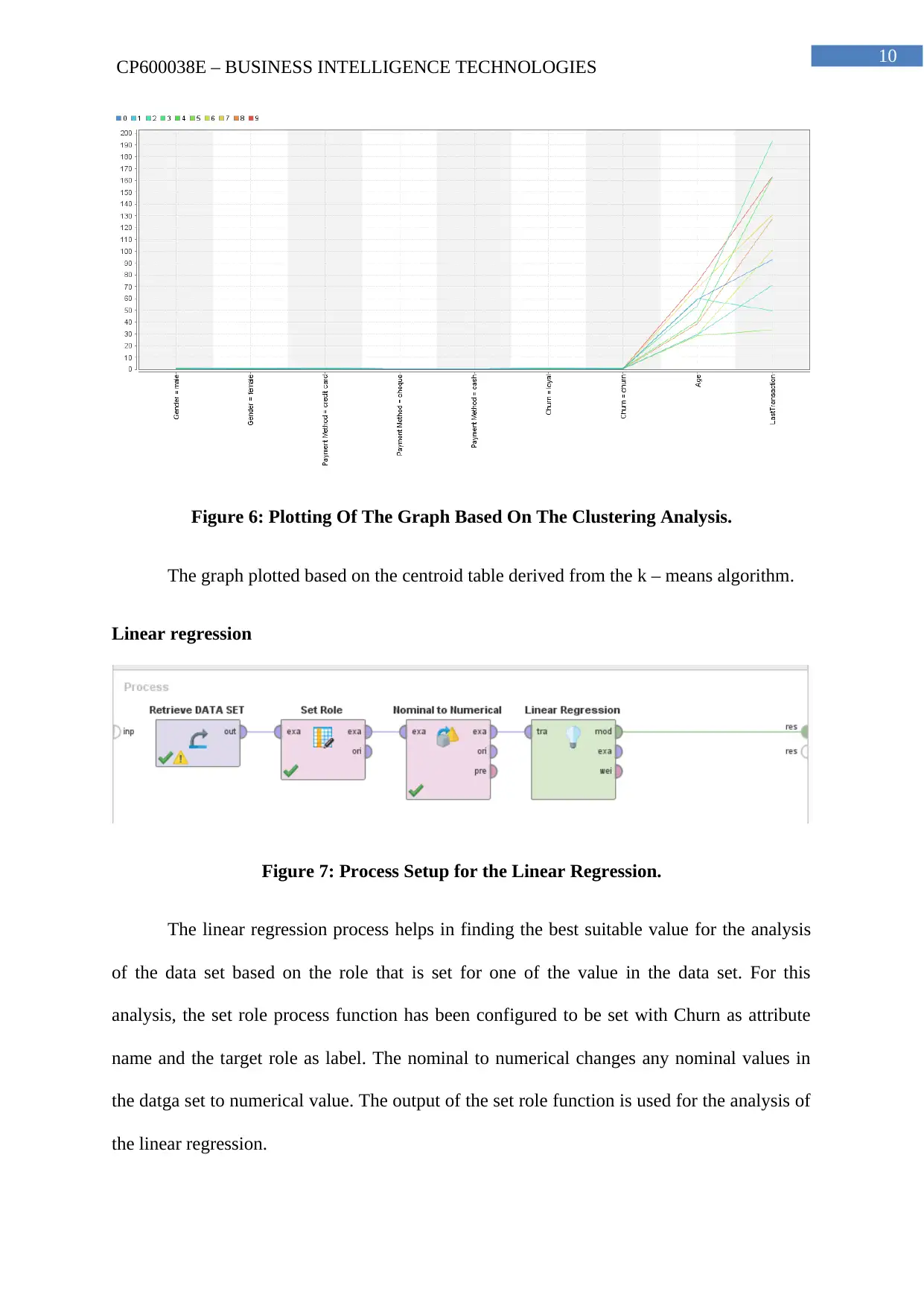
This report, prepared by a student, focuses on applying various data mining techniques to analyze customer loyalty within a banking context. The analysis utilizes a dataset containing customer details such as age, gender, payment method, transaction history, and loyalty status (churn). Three primary data mining techniques are employed: Decision Trees, Clustering (K-means), and Linear Regression. The Decision Tree analysis reveals key factors influencing customer loyalty, such as gender and payment method, creating a visual representation of customer segmentation. K-means clustering is used to group customers based on similarities, and the centroid table and graphical representations are used to visualize the clusters. Linear regression is applied to predict the probability of customer churn, providing an equation that considers various factors. The report provides process setups, data tables, and graphical representations generated from the RapidMiner tool, offering insights into the application and outcomes of each data mining technique. The student provides critical insights derived from each method, comparing and contrasting the results to understand customer behavior. This analysis allows for the identification of patterns and relationships within the data, enabling the bank to improve its customer retention strategies and overall business intelligence.










1 out of 15
Related Documents






Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Copyright © 2020–2026 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.