Data Mining and Visualization for Business Intelligence Assignment 2
VerifiedAdded on 2020/04/07
|10
|1048
|94
Homework Assignment
AI Summary
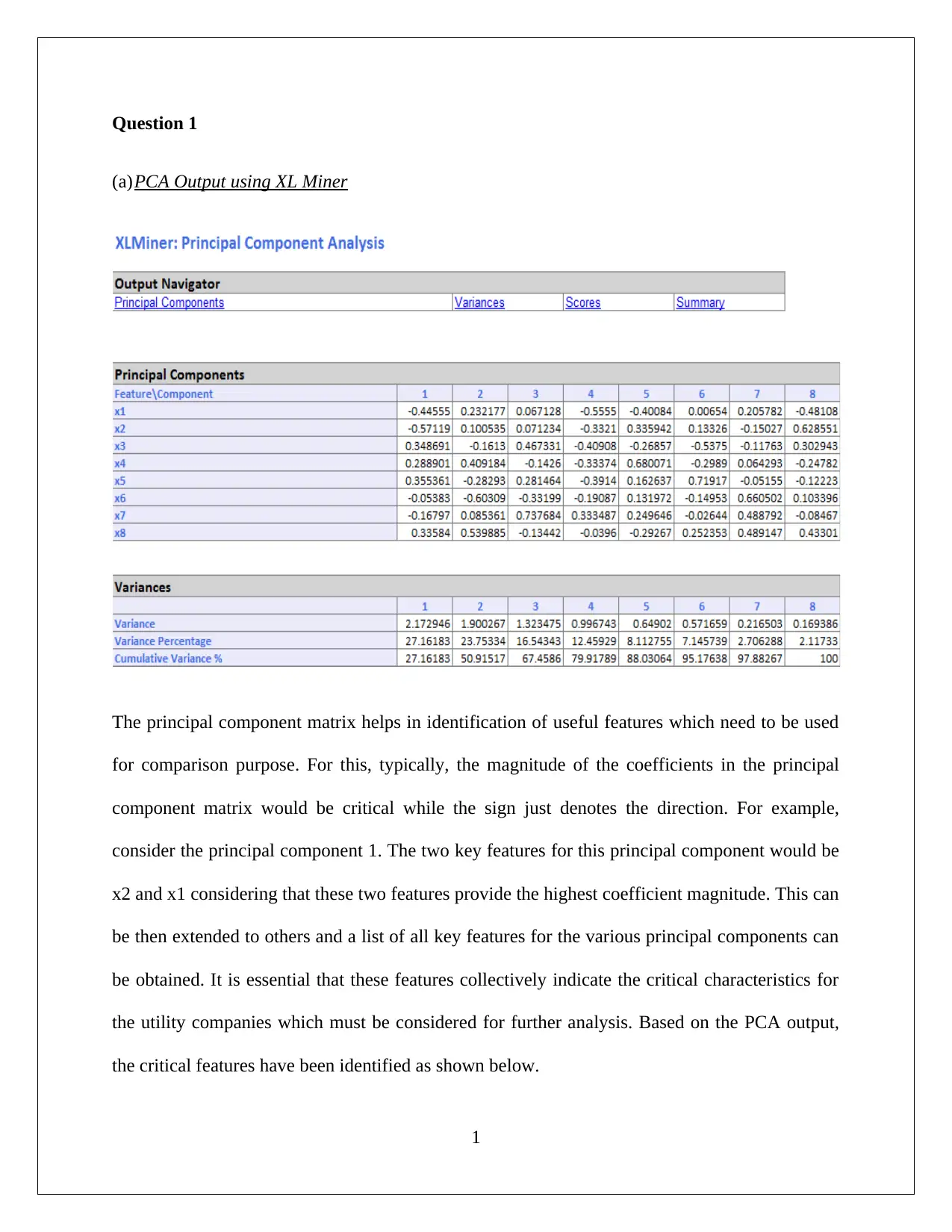
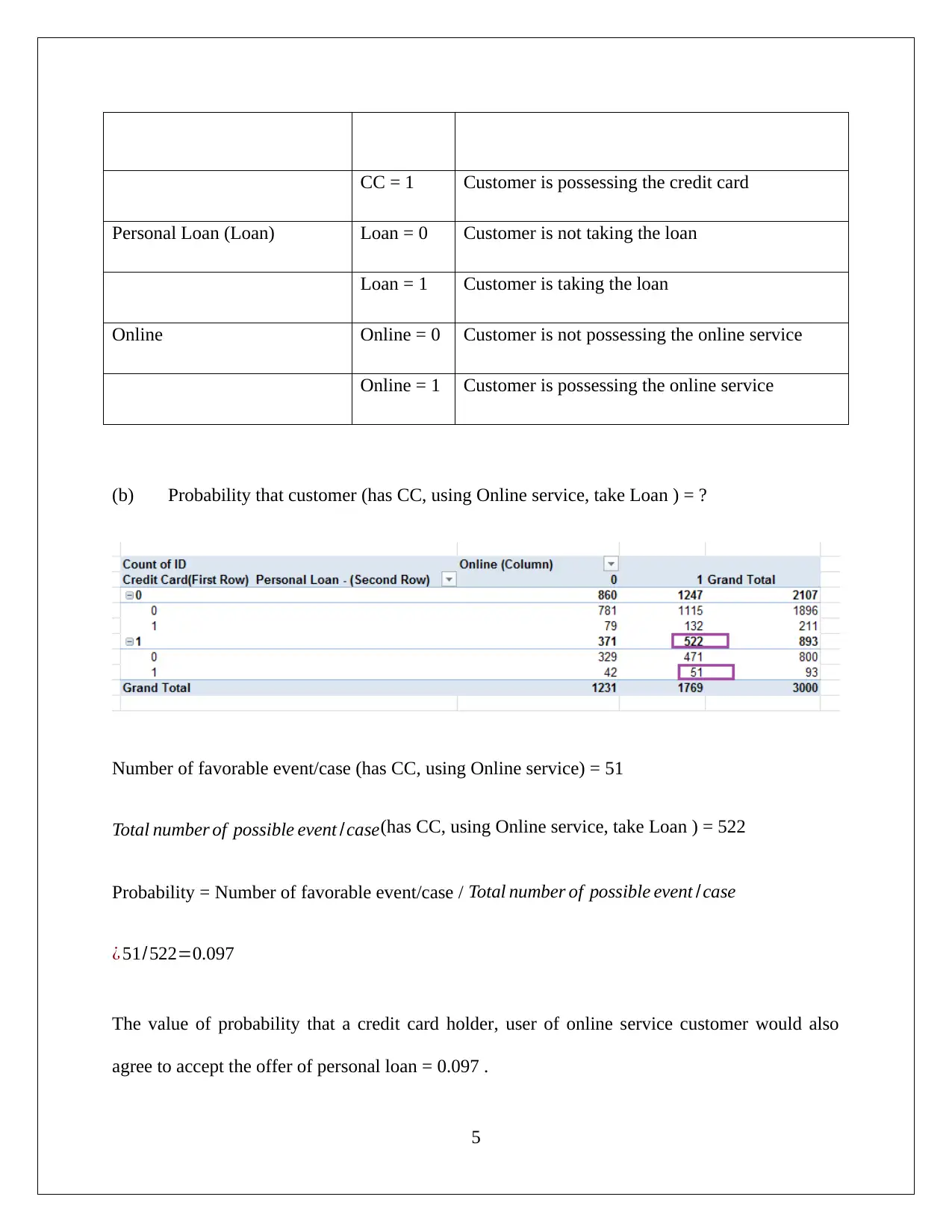
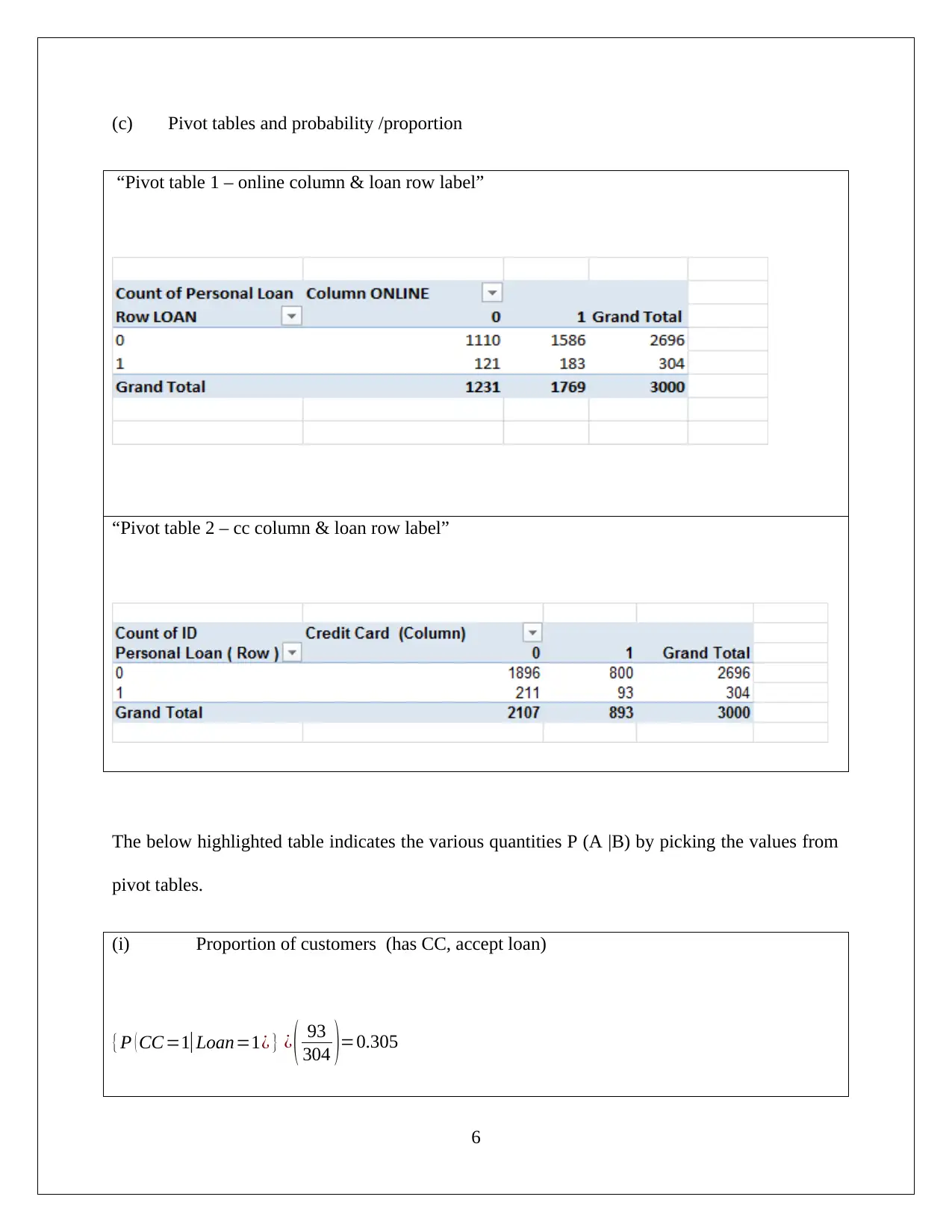
This assignment solution focuses on data mining and visualization techniques for business intelligence. It addresses Principal Component Analysis (PCA) using XL Miner to identify key features and discusses the necessity of data normalization. The solution also explores the advantages and disadvantages of PCA. Furthermore, the assignment delves into analyzing a dataset of 5000 customers from Universal Bank to determine loan acceptors, utilizing pivot tables and calculating probabilities. The solution includes the application of Naive Bayes probability to predict loan acceptance based on customer attributes such as credit card ownership and online service usage. The final part of the assignment recommends the best strategy to increase the chances of the bank making a loan offer.







1 out of 10
Related Documents






Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Copyright © 2020–2026 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.