Data Mining and Visualization for Business Intelligence Homework
VerifiedAdded on 2020/04/07
|11
|1080
|82
Homework Assignment
AI Summary
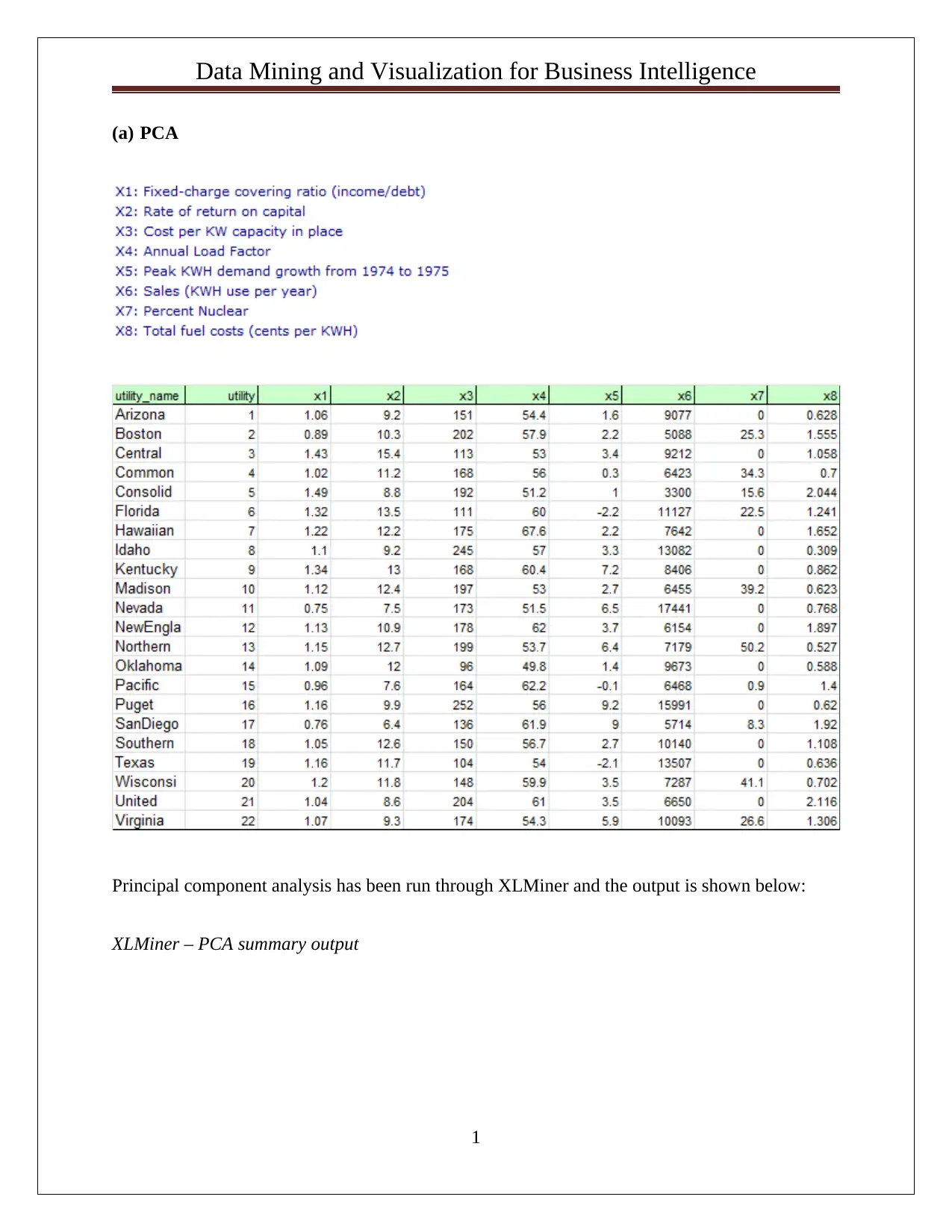
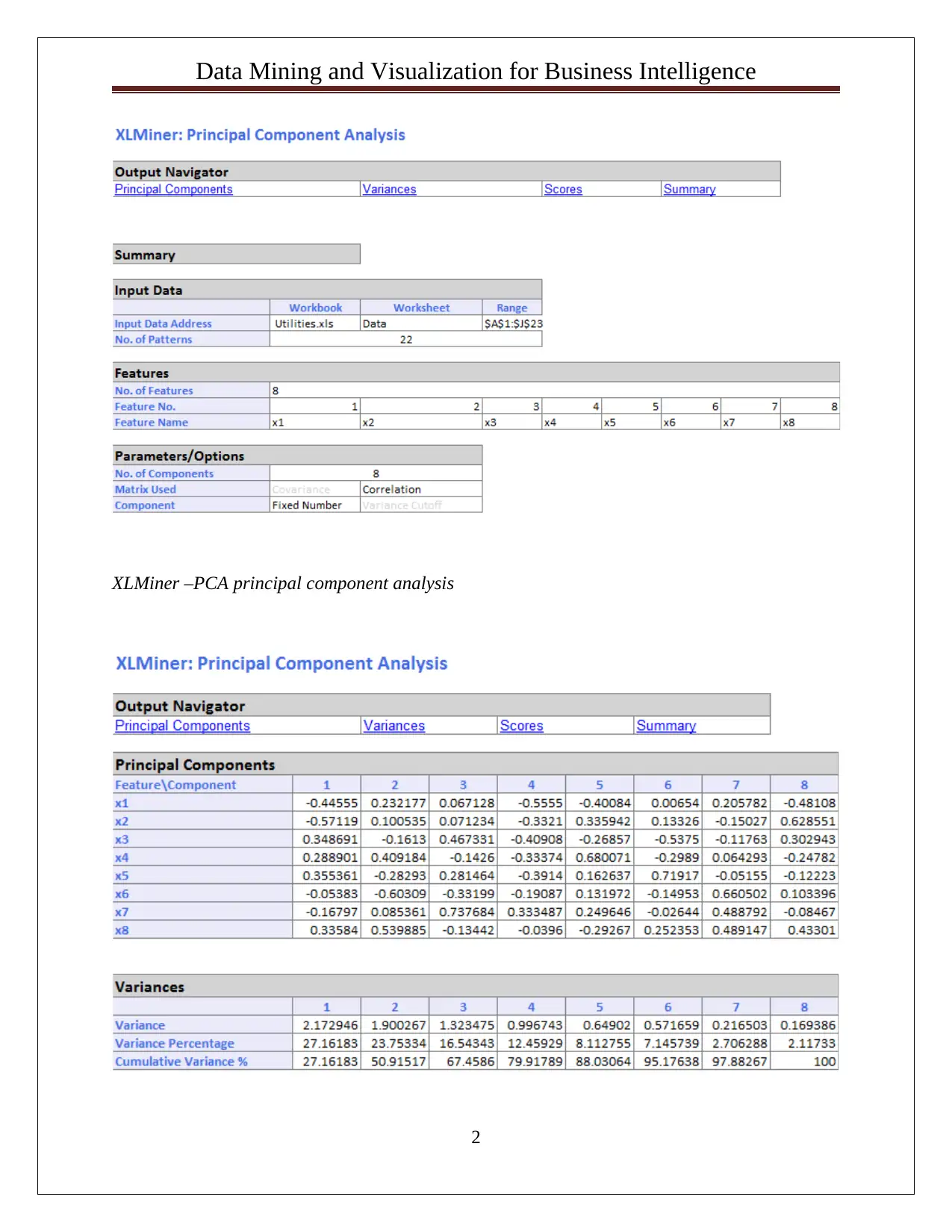
This assignment solution focuses on data mining and visualization techniques for business intelligence. It includes an analysis of Principal Component Analysis (PCA) output, interpreting variance and identifying significant features for dimension reduction. The solution also covers the Naive Bayes classifier, including pivot table design to analyze relationships between predictors (credit card holders, online banking users) and loan acceptance. Probability calculations are performed to determine the likelihood of loan acceptance based on customer profiles, and a Naive Bayes Probability is derived. The assignment concludes with a discussion of the best strategy to maximize loan approval chances, based on the calculated probabilities. The solution leverages tools like XLMiner for analysis and provides insights into data normalization and the advantages and disadvantages of PCA.









1 out of 11
Related Documents





![Data Mining and Visualization Business Case Analysis Solution - [Date]](/_next/image/?url=https%3A%2F%2Fdesklib.com%2Fmedia%2Fimages%2Fa4c62573bfd04fc8a6d2208b43ae0344.jpg&w=256&q=75)
Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Copyright © 2020–2026 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.