Data Mining & Visualization Business Case
VerifiedAdded on 2019/10/30
|10
|899
|382
Report
AI Summary
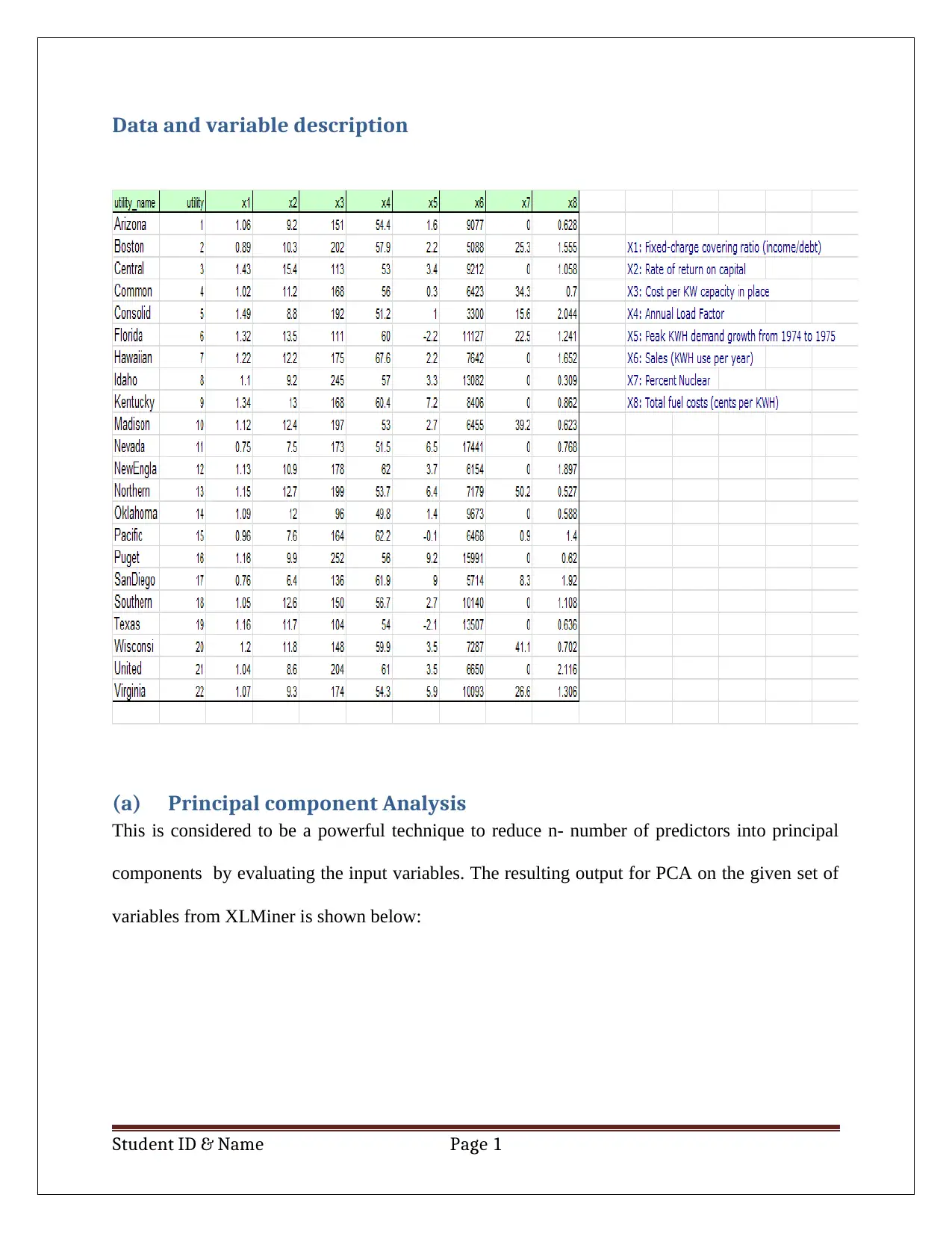
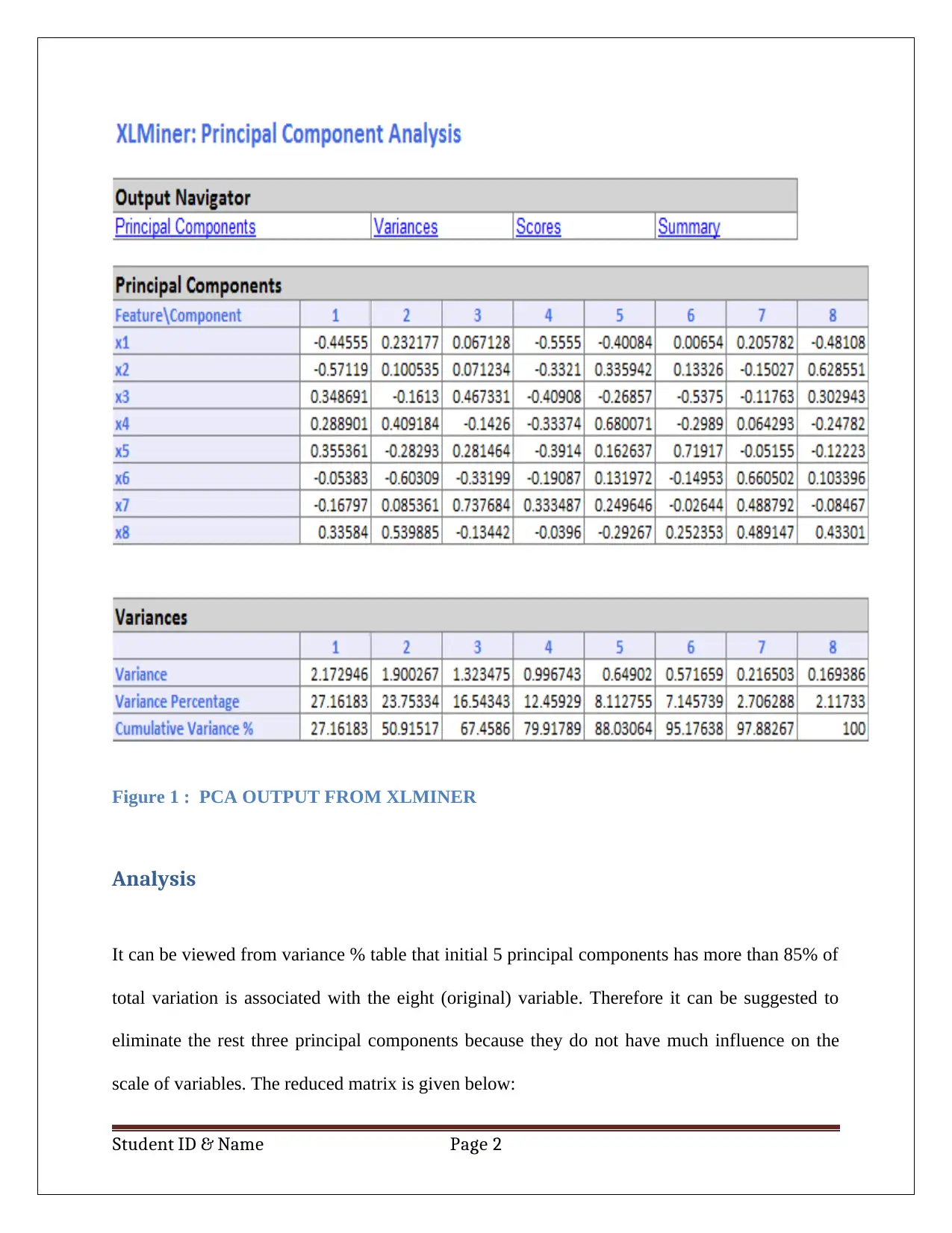
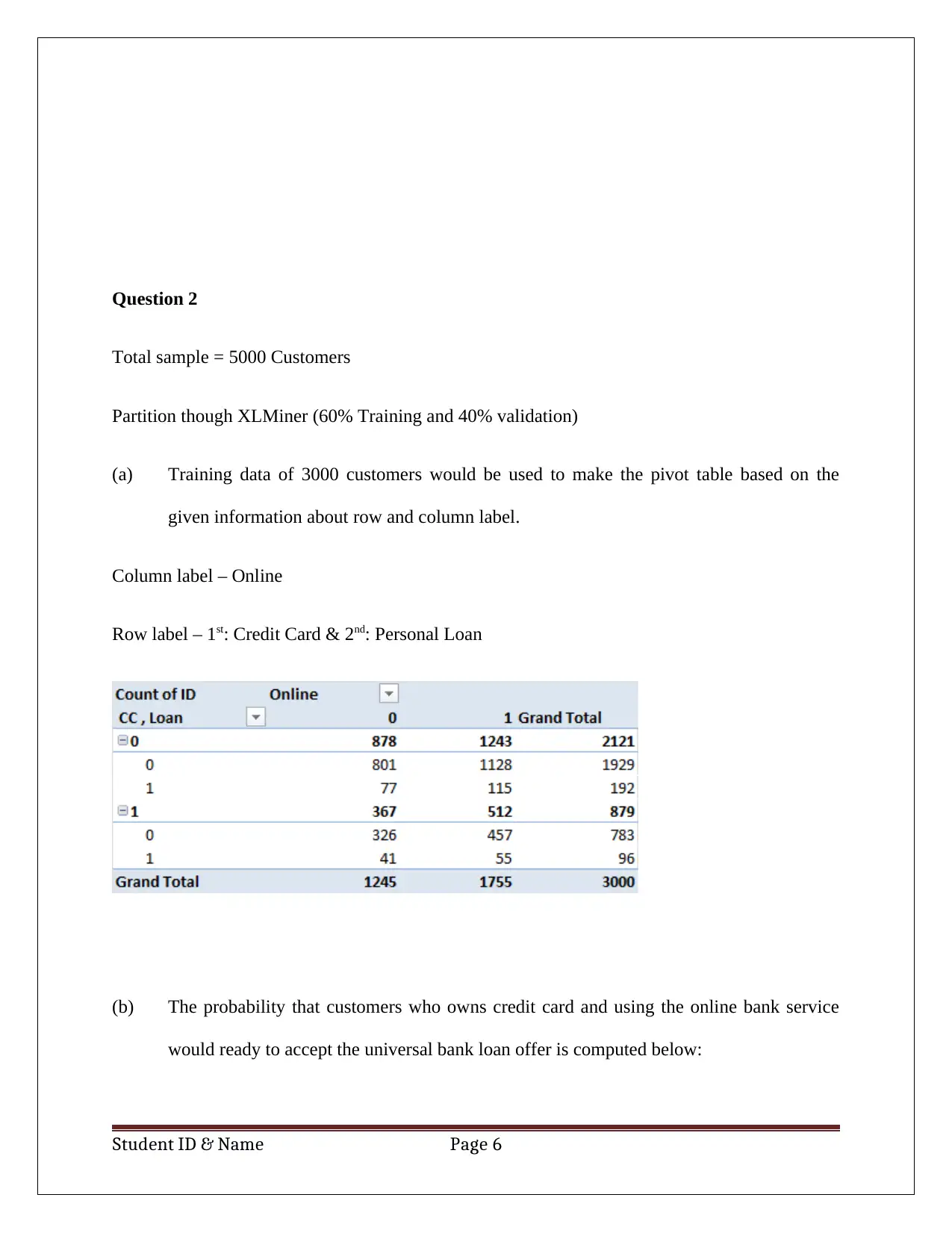
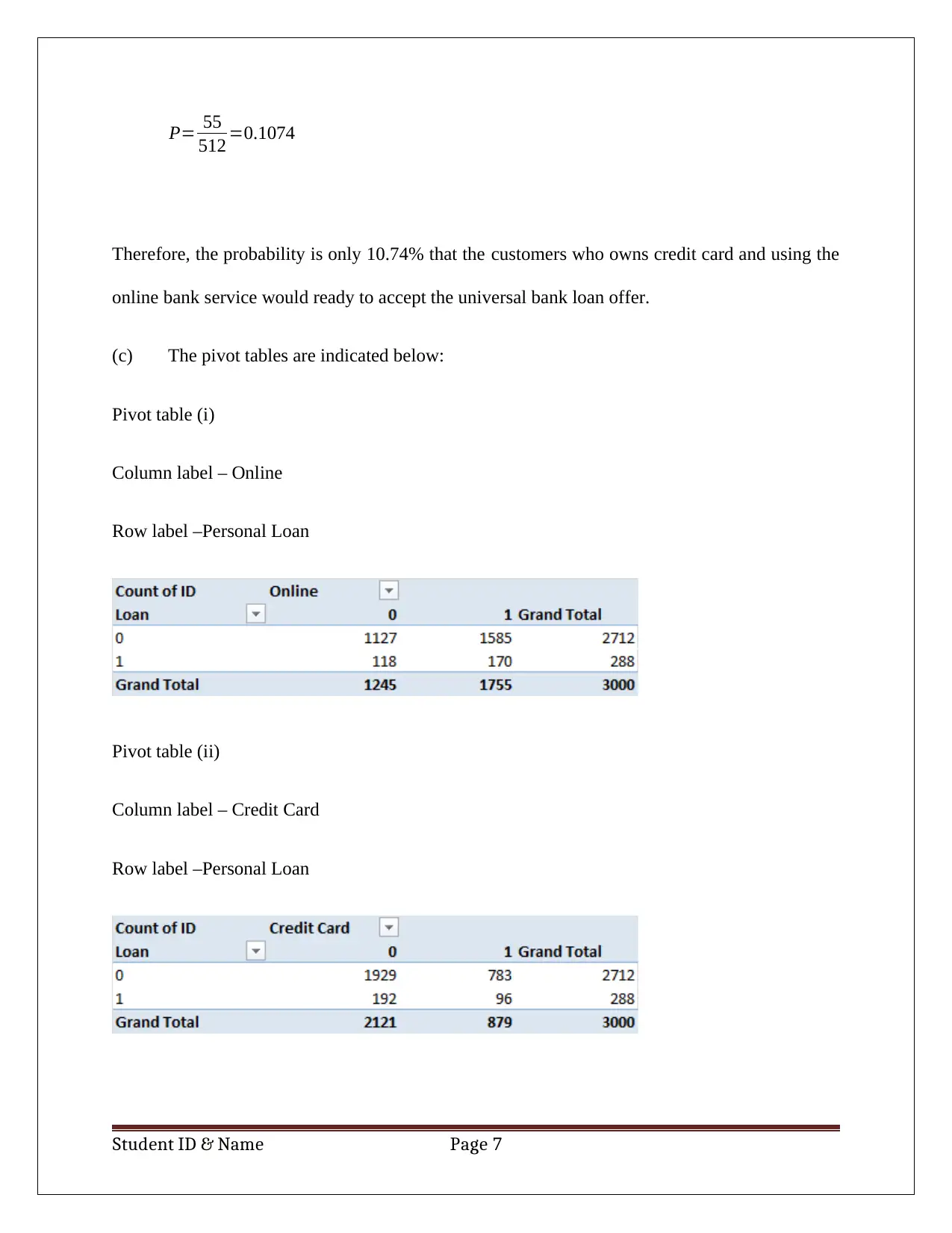
This report details a business case analysis using data mining and visualization techniques. The student utilizes Principal Component Analysis (PCA) to reduce the dimensionality of a dataset, identifying key components for predicting customer loan acceptance. The analysis includes a discussion of data normalization within the PCA context, weighing the advantages and disadvantages of this approach. Furthermore, the report employs Naïve Bayes probability to calculate the likelihood of a customer accepting a loan offer based on factors like credit card ownership and online banking usage. The report concludes by suggesting the optimal customer profile for maximizing loan acceptance probability, highlighting the practical application of data analysis in business decision-making. The analysis is supported by pivot tables and calculations, demonstrating a clear understanding of the methods employed.






1 out of 10
Related Documents






Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Copyright © 2020–2026 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.