Data Mining Assignment: Weka, Iris, and Attribute Exploration
VerifiedAdded on 2022/09/15
|7
|420
|15
Homework Assignment
AI Summary
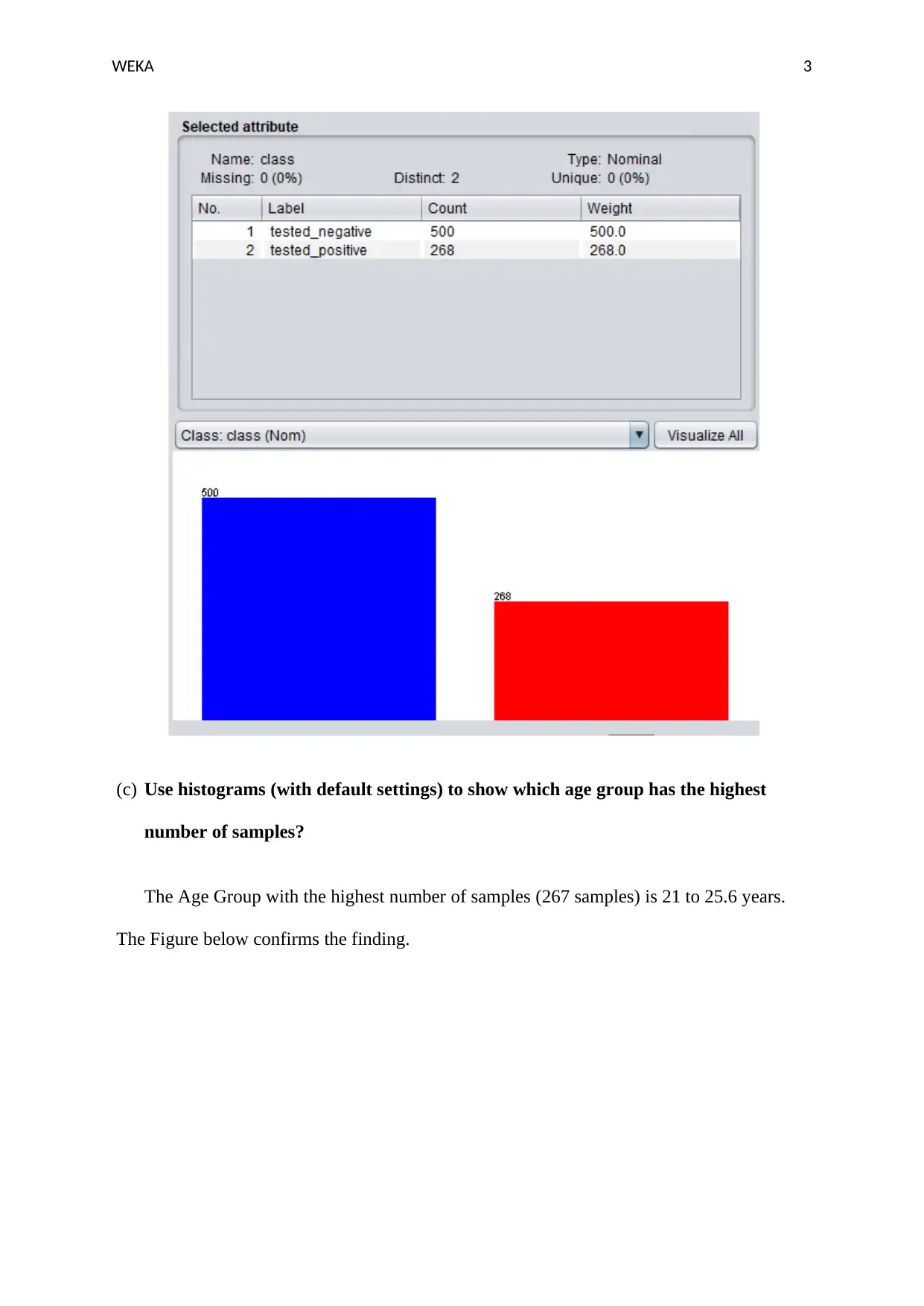
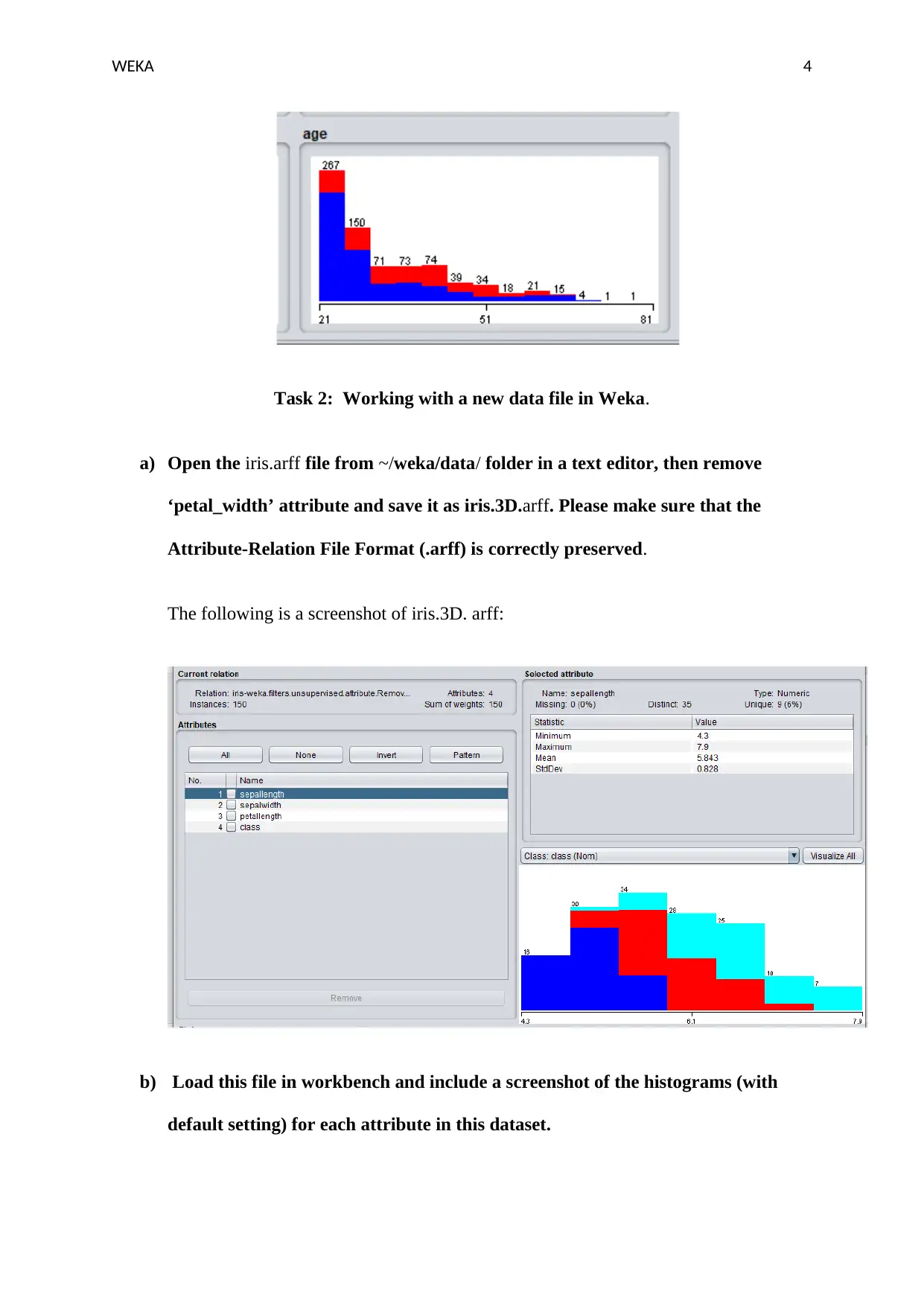
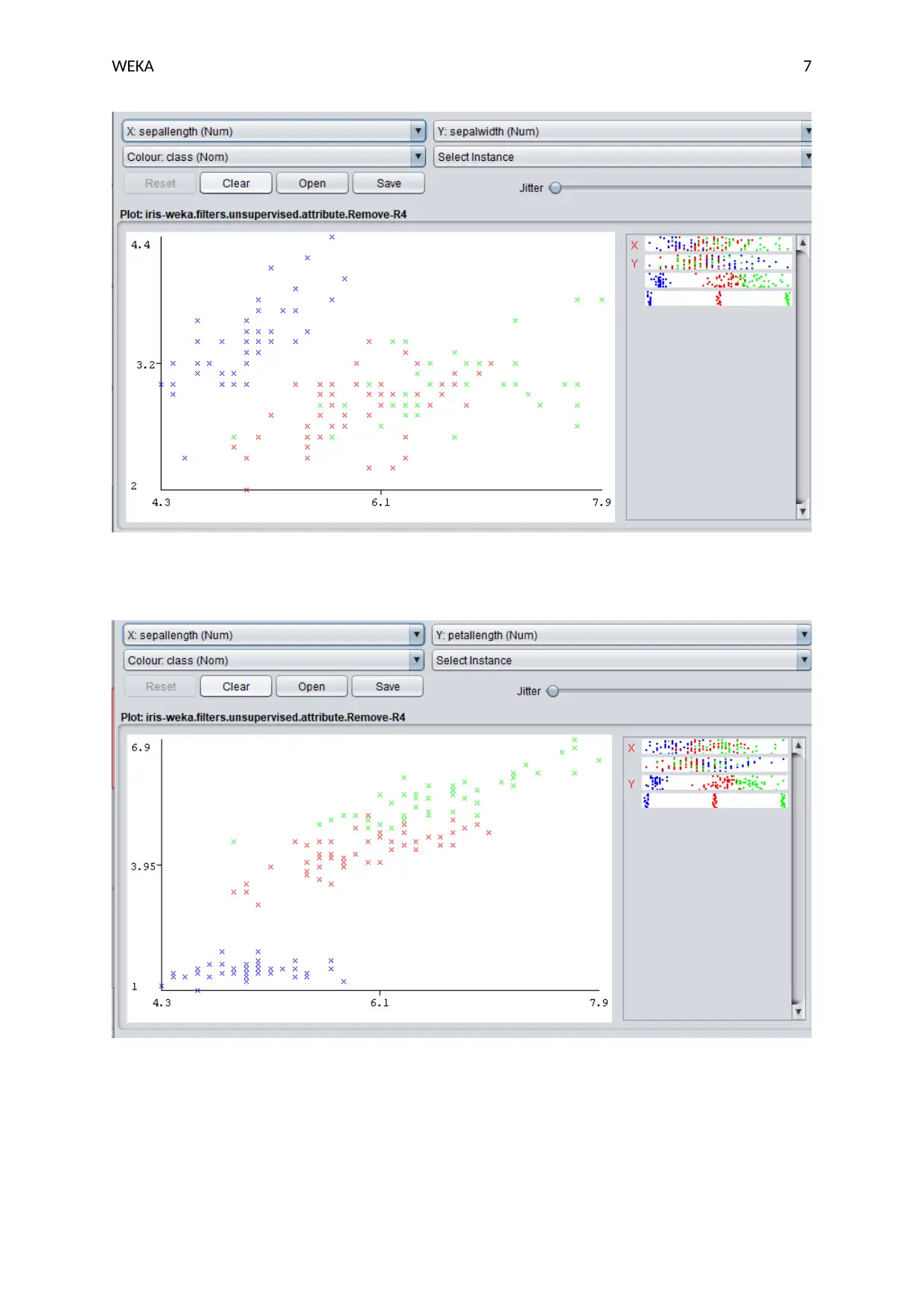
This document presents a solution to a Weka data mining assignment. The solution begins with an analysis of a dataset, including identifying the number of instances, attributes, and classes. It then explores the use of histograms to visualize data distribution and determine the age group with the highest number of samples. The assignment continues by guiding the user through the creation of a modified dataset from the iris.arff file, removing an attribute, and visualizing the data using histograms. Finally, the solution includes a visual analysis of scatter plots to compare and assess class separability between different attributes within the dataset. Screenshots are provided to illustrate each step and the findings of the analysis.




1 out of 7


Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Copyright © 2020–2026 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.