30113 Programming for Data Science Assignment: Airline Analysis
VerifiedAdded on 2023/04/07
|8
|1000
|439
Homework Assignment
AI Summary
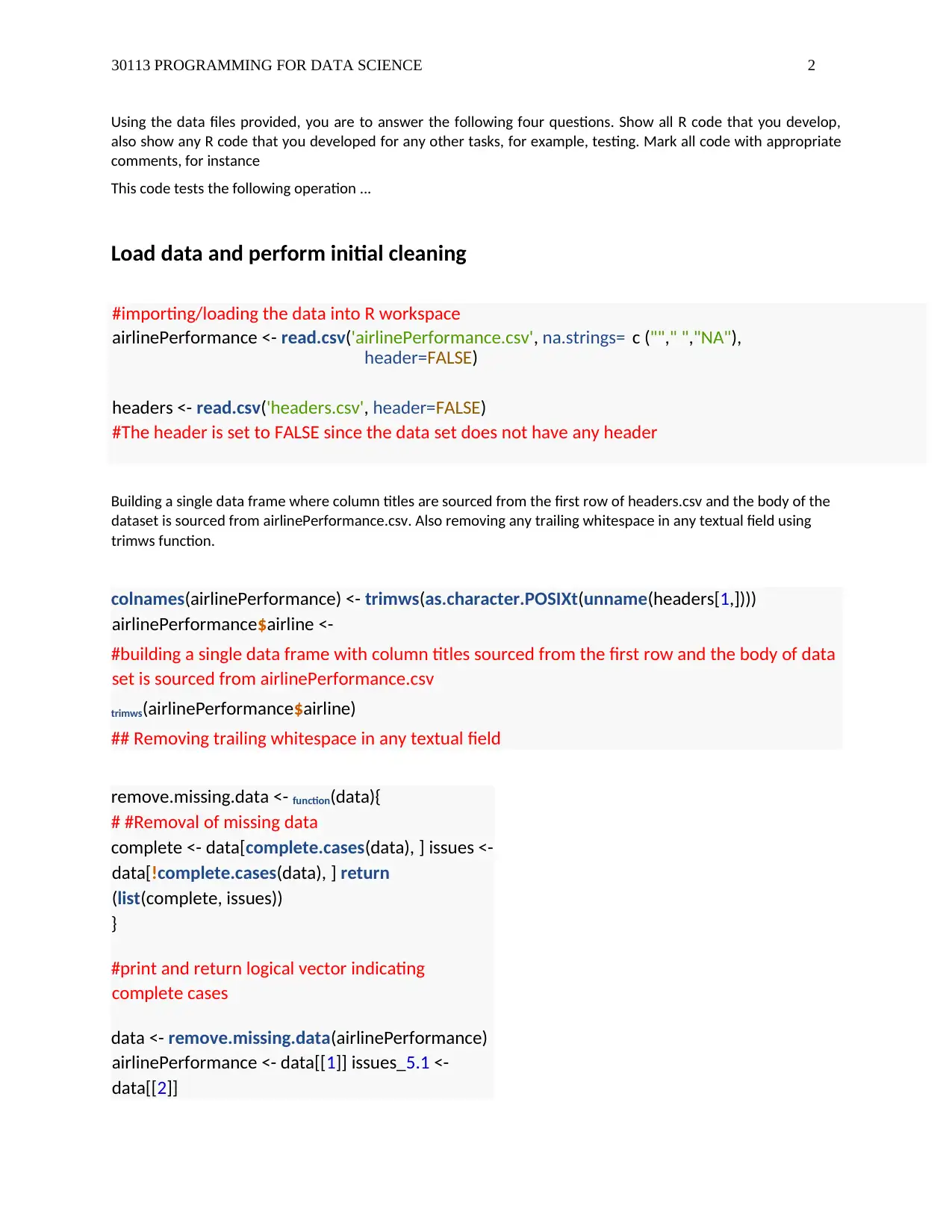
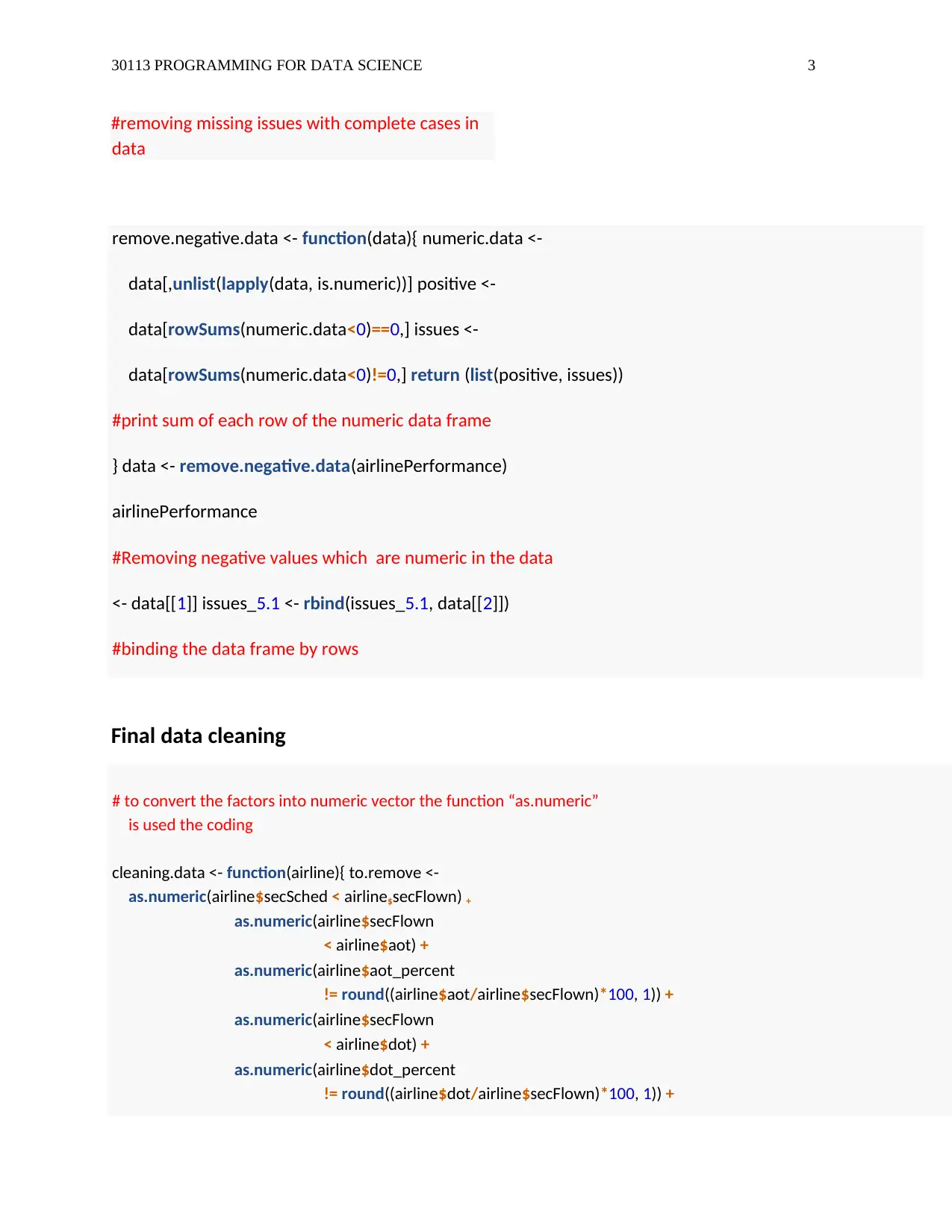
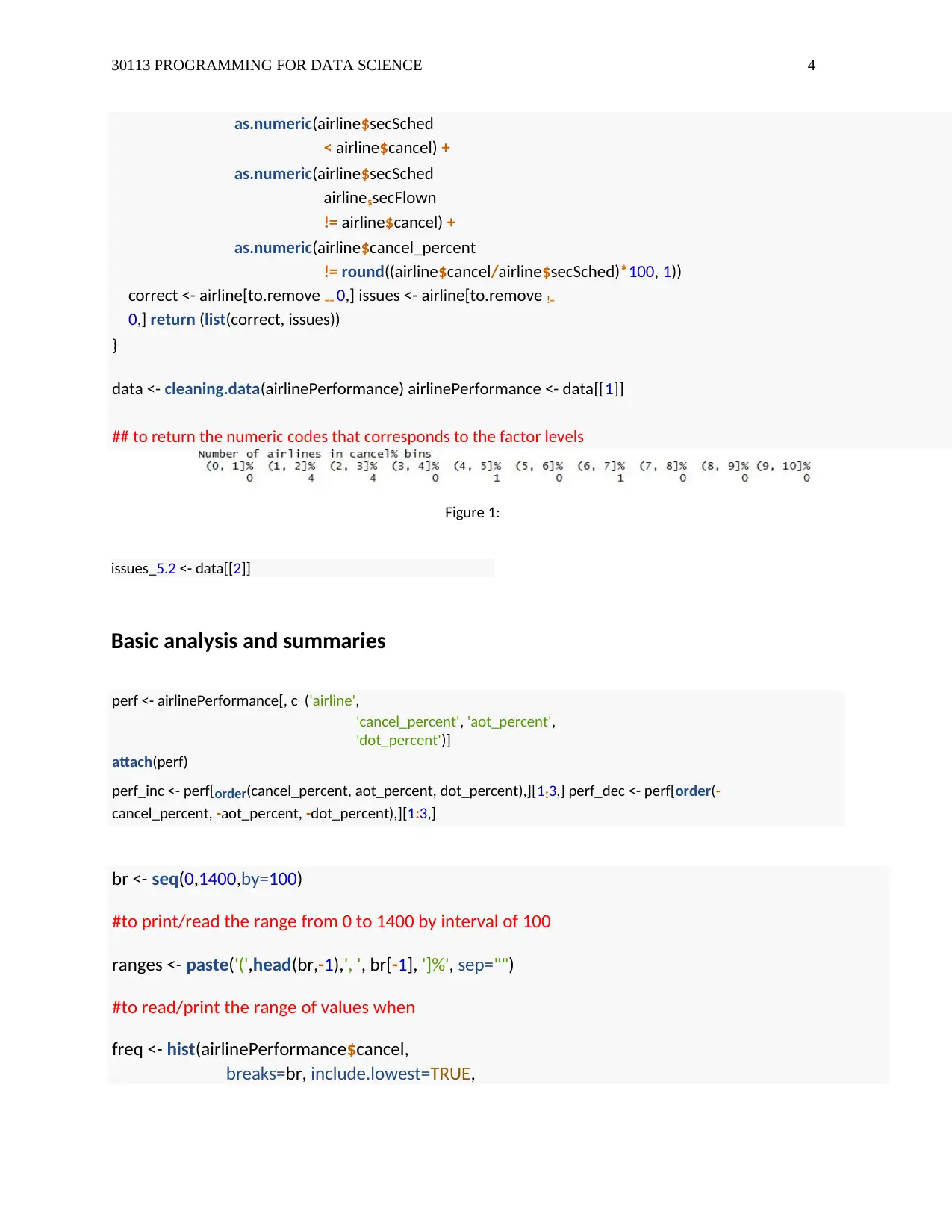
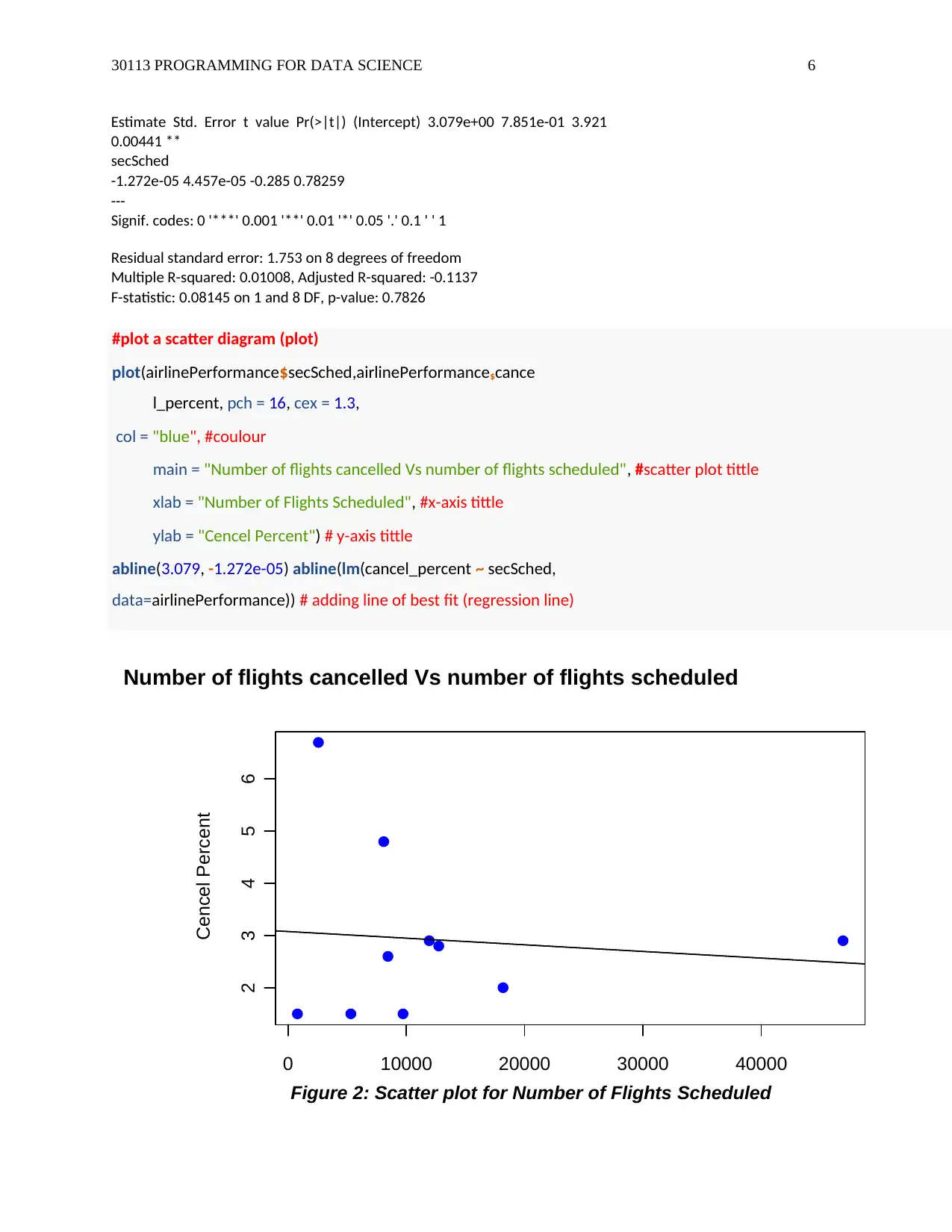
This assignment solution addresses a data science problem involving airline performance analysis using R programming. The solution begins with loading and cleaning the provided airline performance data, handling missing values and negative numeric data. It then performs basic analysis, including calculating key performance indicators like cancellation, arrival on time, and departure on time percentages, as well as generating summaries and histograms. A linear regression model is built to analyze the relationship between scheduled flights and cancellation percentages, and a scatter plot visualizes this relationship. The assignment concludes with text processing to create unique airline names, demonstrating the ability to manipulate and analyze textual data within the dataset. The code is well-commented and structured, providing a comprehensive understanding of the data science workflow.



1 out of 8
Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Copyright © 2020–2026 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.