Data Science: Regression, Classification, and Model Evaluation
VerifiedAdded on 2021/06/16
|20
|3180
|36
Homework Assignment
AI Summary
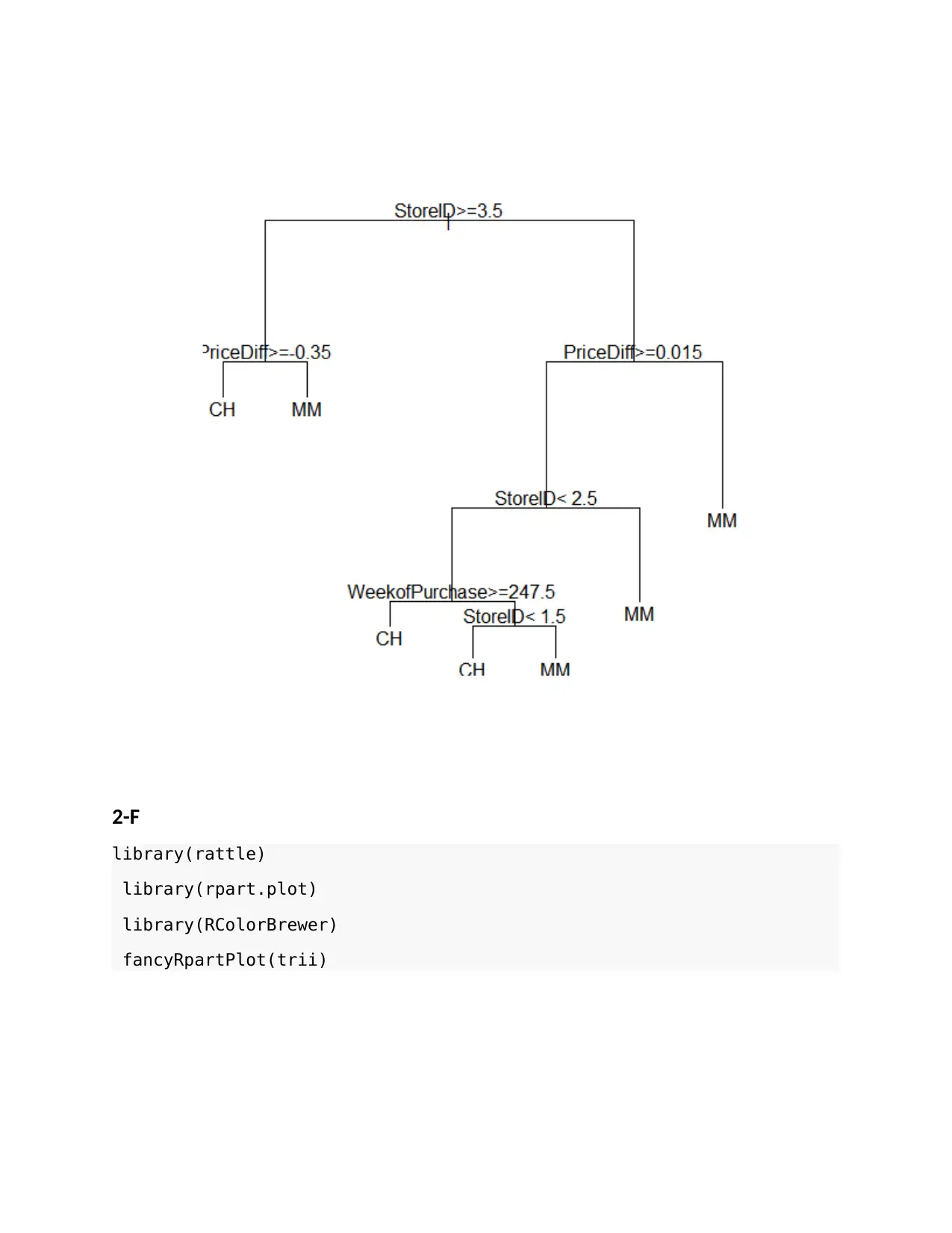
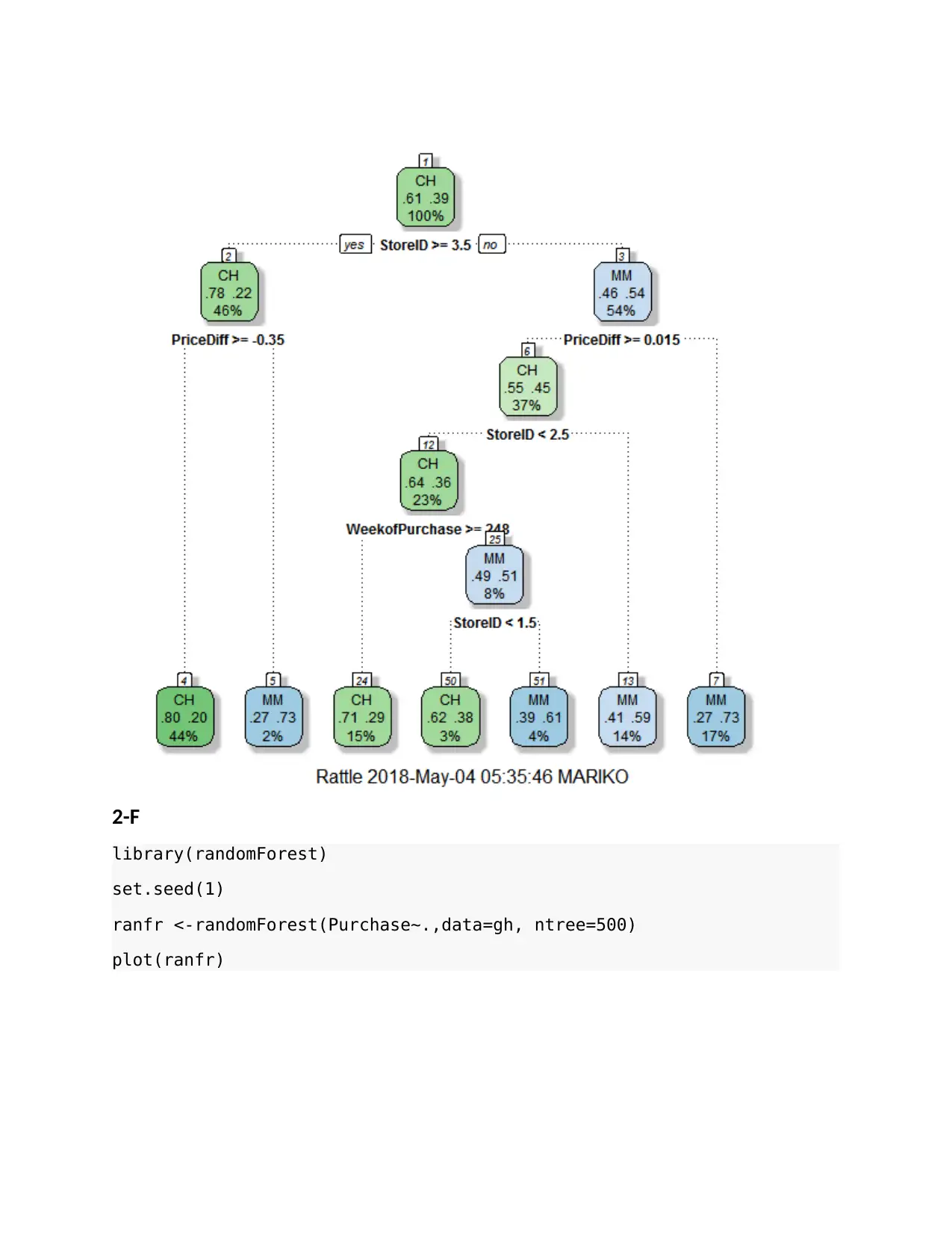
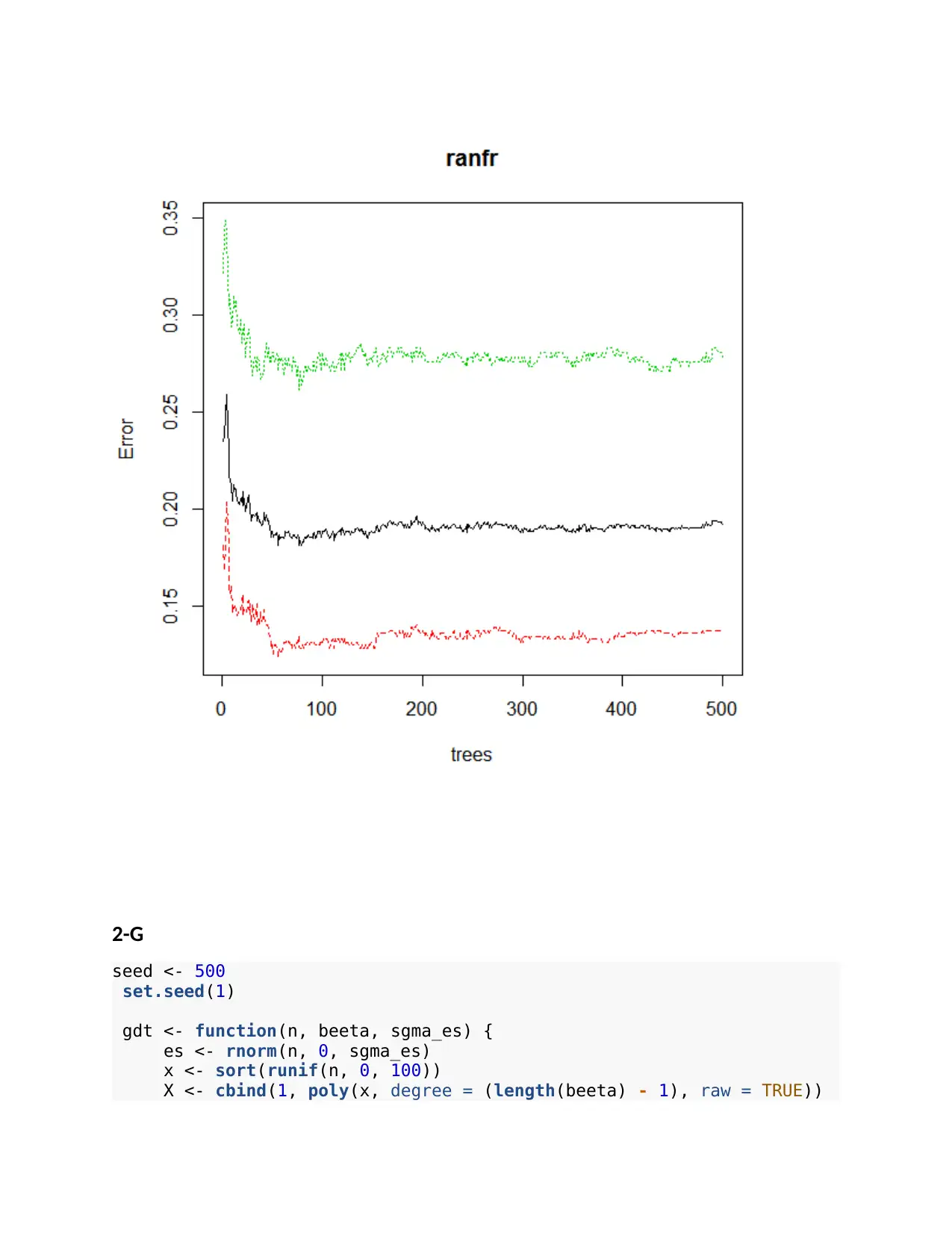
This assignment delves into various aspects of data science, encompassing regression analysis, classification models, and model evaluation techniques. The first part focuses on regression using splines, exploring model fitting, plotting, and cross-validation to assess model performance. The second part shifts to classification, utilizing decision trees, naive Bayes, and random forests to predict a binary outcome. The third part explores model selection and evaluation using cross-validation and lasso regression to refine the model's accuracy. The assignment includes code implementations, model summaries, and performance metrics to compare and contrast different approaches, providing a comprehensive understanding of data science methodologies. This assignment provides a practical exploration of various data science techniques including regression, classification, and model evaluation, offering a comprehensive understanding of data science methodologies.





1 out of 20
Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Copyright © 2020–2026 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.