Data Mining and Visualization Assessment - Data Analysis Report
VerifiedAdded on 2020/03/28
|10
|1183
|87
Homework Assignment
AI Summary
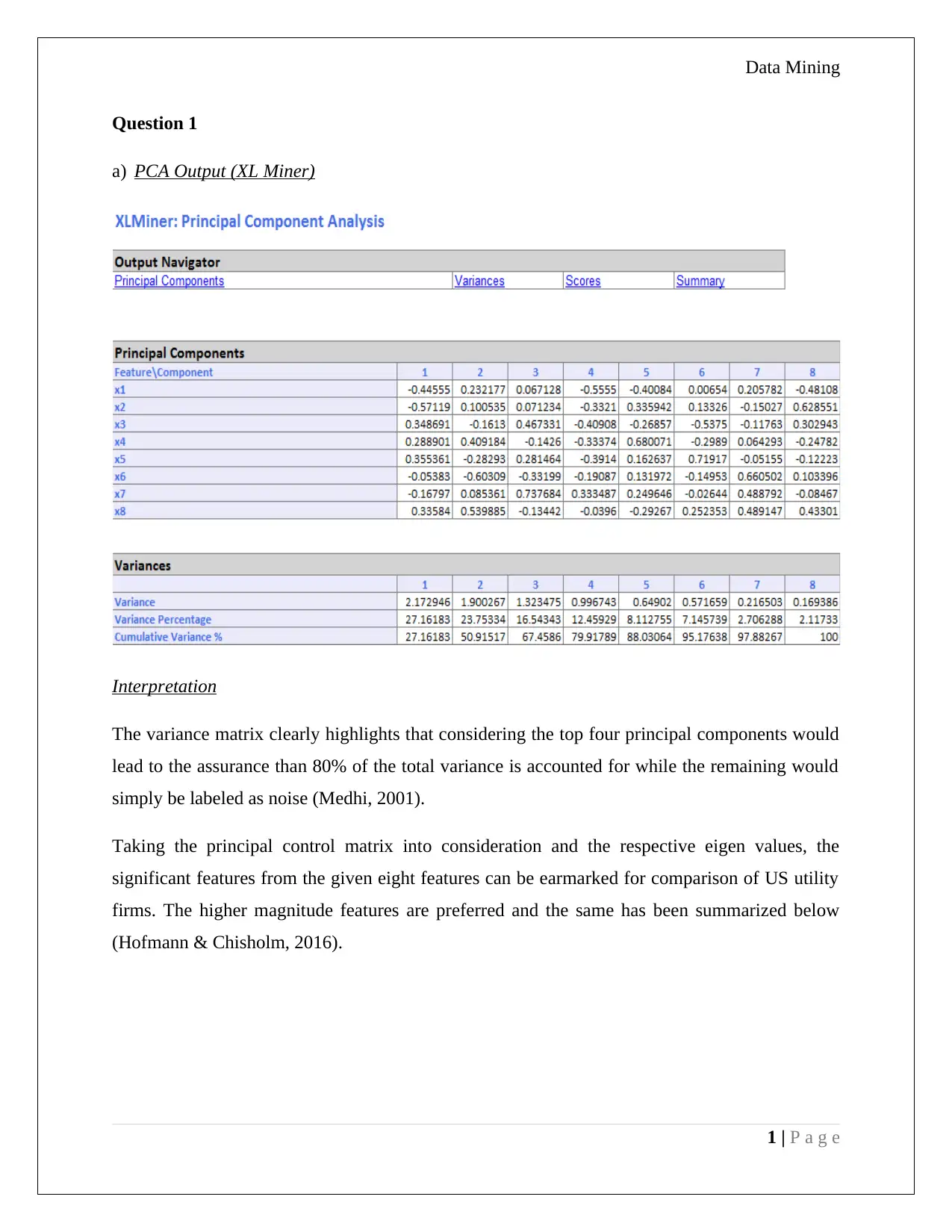
This data mining assignment involves the interpretation of PCA output using XL Miner to analyze the variance matrix and identify significant features for comparing US utility firms. The assignment then focuses on analyzing customer data from a universal bank, partitioned into training and validation sets. It uses pivot tables to examine the relationships between credit card usage, online banking service, and loan acceptance. The analysis calculates conditional probabilities to determine the likelihood of a customer accepting a loan offer based on their online service usage and credit card ownership. The assignment concludes with a strategy recommendation to maximize loan acceptance probability by targeting customers who are both credit card holders and active online service users. The solution references key concepts of data mining, statistical methods and data analysis techniques.









1 out of 10
Related Documents






Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Copyright © 2020–2026 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.