Data Warehouse Project: Edmonton Unclaimed Bank Accounts Analysis
VerifiedAdded on 2019/09/25
|14
|2678
|270
Project
AI Summary
This project focuses on designing and implementing a data warehouse using an unclaimed bank accounts dataset from Edmonton, Canada. The project begins with an introduction to data warehousing and business intelligence, followed by a detailed description of the dataset, including its columns and data types. The core of the project involves designing the data warehouse, selecting MS Access 2007 as the implementation tool, and populating the data. The project also includes an entity-relationship diagram (ERD) to illustrate the database structure, a literature review on data mining in banking, and a discussion of the objectives. The implemented data warehouse is then used to query and process the data to answer research questions and generate reports. The project concludes with an analysis of the results, conclusions, and potential future work, demonstrating a comprehensive understanding of data warehousing principles and practical implementation.

Business Intelligence and Data Warehouse
Assignment
Assignment
Paraphrase This Document
Need a fresh take? Get an instant paraphrase of this document with our AI Paraphraser

CONTENTS
1. Introduction
2.1 Dataset Description
2.2 Domain Information
2.3 Objectives
2.4 Project Scope
2. Design
3.1 Technology Used
3.2 Implementation
3.3 Operation and Processing
3. Results and Conclusion
4.1 Results
4.2 Conclusions
4.3 Future Work
4.4 Analysis of Results
4.5 Accomplishments
1. Introduction
2.1 Dataset Description
2.2 Domain Information
2.3 Objectives
2.4 Project Scope
2. Design
3.1 Technology Used
3.2 Implementation
3.3 Operation and Processing
3. Results and Conclusion
4.1 Results
4.2 Conclusions
4.3 Future Work
4.4 Analysis of Results
4.5 Accomplishments

1. Introduction
1.1 Dataset Description
The project uses unclaimed bank accounts dataset for generating data warehouse and
Business Intelligence reports. This dataset contains the list of all the bank accounts those
are unclaimed and abandoned at branches in the Edmonton area of Canada. The addresses
contains in the dataset are all from the Edmonton area. Some important dates are enlisted
below related to the dataset:
Date Created : July 21, 2010
Updated : June 27, 2014
Data Last Updated: August 21, 2011
The edmontonjournal is the sole owner of this data. This data is freely available at the website
and can be downloaded as required.
Dataset contains 12.8K rows and 7 columns. The column description is as shown below:
Column Name Type
Last / Business Name Plain Text
First Name Plain Text
Balance Number
Address Plain Text
City Plain Text
Last Transaction Date & Time
bank_name Plain Text
Following is the preview of dataset. Its first 10 rows are shown below.
1.1 Dataset Description
The project uses unclaimed bank accounts dataset for generating data warehouse and
Business Intelligence reports. This dataset contains the list of all the bank accounts those
are unclaimed and abandoned at branches in the Edmonton area of Canada. The addresses
contains in the dataset are all from the Edmonton area. Some important dates are enlisted
below related to the dataset:
Date Created : July 21, 2010
Updated : June 27, 2014
Data Last Updated: August 21, 2011
The edmontonjournal is the sole owner of this data. This data is freely available at the website
and can be downloaded as required.
Dataset contains 12.8K rows and 7 columns. The column description is as shown below:
Column Name Type
Last / Business Name Plain Text
First Name Plain Text
Balance Number
Address Plain Text
City Plain Text
Last Transaction Date & Time
bank_name Plain Text
Following is the preview of dataset. Its first 10 rows are shown below.
⊘ This is a preview!⊘
Do you want full access?
Subscribe today to unlock all pages.
Trusted by 1+ million students worldwide
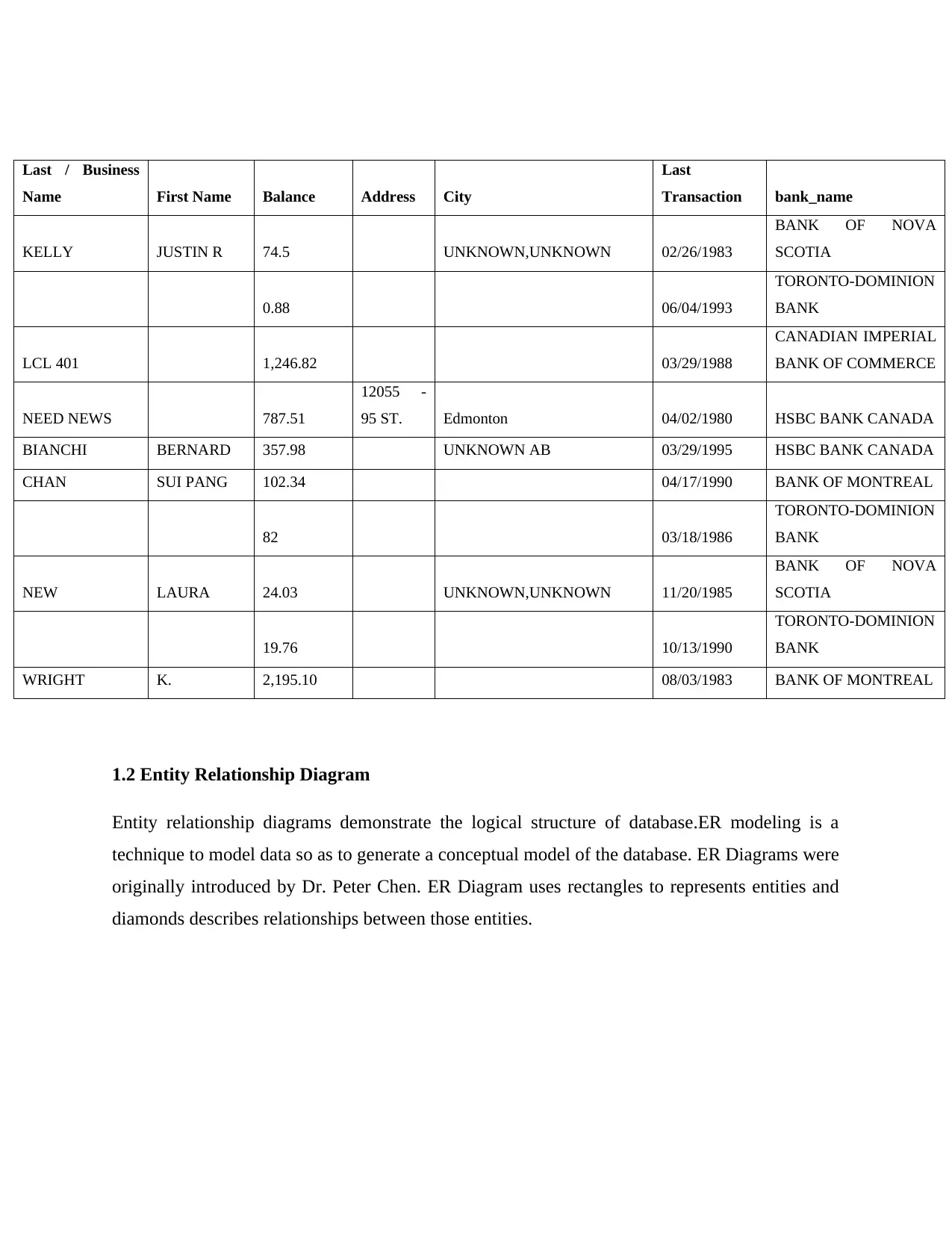
Last / Business
Name First Name Balance Address City
Last
Transaction bank_name
KELLY JUSTIN R 74.5 UNKNOWN,UNKNOWN 02/26/1983
BANK OF NOVA
SCOTIA
0.88 06/04/1993
TORONTO-DOMINION
BANK
LCL 401 1,246.82 03/29/1988
CANADIAN IMPERIAL
BANK OF COMMERCE
NEED NEWS 787.51
12055 -
95 ST. Edmonton 04/02/1980 HSBC BANK CANADA
BIANCHI BERNARD 357.98 UNKNOWN AB 03/29/1995 HSBC BANK CANADA
CHAN SUI PANG 102.34 04/17/1990 BANK OF MONTREAL
82 03/18/1986
TORONTO-DOMINION
BANK
NEW LAURA 24.03 UNKNOWN,UNKNOWN 11/20/1985
BANK OF NOVA
SCOTIA
19.76 10/13/1990
TORONTO-DOMINION
BANK
WRIGHT K. 2,195.10 08/03/1983 BANK OF MONTREAL
1.2 Entity Relationship Diagram
Entity relationship diagrams demonstrate the logical structure of database.ER modeling is a
technique to model data so as to generate a conceptual model of the database. ER Diagrams were
originally introduced by Dr. Peter Chen. ER Diagram uses rectangles to represents entities and
diamonds describes relationships between those entities.
Name First Name Balance Address City
Last
Transaction bank_name
KELLY JUSTIN R 74.5 UNKNOWN,UNKNOWN 02/26/1983
BANK OF NOVA
SCOTIA
0.88 06/04/1993
TORONTO-DOMINION
BANK
LCL 401 1,246.82 03/29/1988
CANADIAN IMPERIAL
BANK OF COMMERCE
NEED NEWS 787.51
12055 -
95 ST. Edmonton 04/02/1980 HSBC BANK CANADA
BIANCHI BERNARD 357.98 UNKNOWN AB 03/29/1995 HSBC BANK CANADA
CHAN SUI PANG 102.34 04/17/1990 BANK OF MONTREAL
82 03/18/1986
TORONTO-DOMINION
BANK
NEW LAURA 24.03 UNKNOWN,UNKNOWN 11/20/1985
BANK OF NOVA
SCOTIA
19.76 10/13/1990
TORONTO-DOMINION
BANK
WRIGHT K. 2,195.10 08/03/1983 BANK OF MONTREAL
1.2 Entity Relationship Diagram
Entity relationship diagrams demonstrate the logical structure of database.ER modeling is a
technique to model data so as to generate a conceptual model of the database. ER Diagrams were
originally introduced by Dr. Peter Chen. ER Diagram uses rectangles to represents entities and
diamonds describes relationships between those entities.
Paraphrase This Document
Need a fresh take? Get an instant paraphrase of this document with our AI Paraphraser

1.3 Domain Information
Data Warehouse:
Integration of data from different sources and storing them at one place is called as a data
warehouse. It is a relational database designed especially for query and analysis other than
transaction processing. It supports decision making in many fields where manual data cannot be
examined. It performs structuring the data in new format and provides a clear view of the entire
dataset in whole different way. It analyses data from different sources and enables a business or
an organization to perform queries to get clear vision towards the huge data and transactions. The
main features of a data warehouse includes extraction, transportation, transformation and loading
(ETL), an Online Analytical (OLAP) Engine and other applications to manage and operate the
data so as to deliver it to its user.
Characteristics of Data Warehouse:
Subject Oriented
Data Warehouse:
Integration of data from different sources and storing them at one place is called as a data
warehouse. It is a relational database designed especially for query and analysis other than
transaction processing. It supports decision making in many fields where manual data cannot be
examined. It performs structuring the data in new format and provides a clear view of the entire
dataset in whole different way. It analyses data from different sources and enables a business or
an organization to perform queries to get clear vision towards the huge data and transactions. The
main features of a data warehouse includes extraction, transportation, transformation and loading
(ETL), an Online Analytical (OLAP) Engine and other applications to manage and operate the
data so as to deliver it to its user.
Characteristics of Data Warehouse:
Subject Oriented

Data warehouse makes it possible for data analyzers to help in analyzing the data on the
particular subject. For an instance, consider the company need to analyze the sales data. The data
analyzers can build the warehouse that is focused on sales part only. Using this warehouse the
analyzers can get answers to the questions like,
Which customer bought most of the commodities last year?
Data warehouse lets analyzers to focus on a particular subject hence, it is subject oriented.
Integrated
Integration is very closely linked to subject orientation. Data warehouse is expected to integrate
all the data from heterogeneous and different sources into one constant format. The common
problems arise while integration is naming conflicts and all the inconsistencies between metrics
units. Once the data warehouse becomes capable of achieving this, they are integrated.
Nonvolatile
The main feature of data warehouse is non-volatility. This means all the data that is once inserted
in the warehouse should not be changed. This is because the analysis must done on the constant
data and not on the ever changing one.
Time Variant
To find new trends in business, data analysts uses large amount of data which contradicts itself
from online transaction processing (OLTP) systems. In OLTP systems, the historical data is
expected to compress in archive. The characteristic of data warehouse to concentrate on change
over time is termed as time variant.
Data Warehouse Types:
Data mining, analytical processing and information processing are three major types of
warehouse.
Data Mining
particular subject. For an instance, consider the company need to analyze the sales data. The data
analyzers can build the warehouse that is focused on sales part only. Using this warehouse the
analyzers can get answers to the questions like,
Which customer bought most of the commodities last year?
Data warehouse lets analyzers to focus on a particular subject hence, it is subject oriented.
Integrated
Integration is very closely linked to subject orientation. Data warehouse is expected to integrate
all the data from heterogeneous and different sources into one constant format. The common
problems arise while integration is naming conflicts and all the inconsistencies between metrics
units. Once the data warehouse becomes capable of achieving this, they are integrated.
Nonvolatile
The main feature of data warehouse is non-volatility. This means all the data that is once inserted
in the warehouse should not be changed. This is because the analysis must done on the constant
data and not on the ever changing one.
Time Variant
To find new trends in business, data analysts uses large amount of data which contradicts itself
from online transaction processing (OLTP) systems. In OLTP systems, the historical data is
expected to compress in archive. The characteristic of data warehouse to concentrate on change
over time is termed as time variant.
Data Warehouse Types:
Data mining, analytical processing and information processing are three major types of
warehouse.
Data Mining
⊘ This is a preview!⊘
Do you want full access?
Subscribe today to unlock all pages.
Trusted by 1+ million students worldwide

The technique of finding hidden associations by discovering knowledge from a large data source
is referred to as data mining. The main techniques for data mining include classification,
regression and prediction. The visualization tools are used for presenting the data mining results
Information Processing
The data warehouse which allows analysts to process the data that is stored in it. Basically query
is the way of processing the data. Moreover it supports basic statistical analysis and reports are
generated using tables and graphs, charts, etc..
Analytical Processing
Analytical processing is supported by the data warehouse so that data can be processed on the
basis of basic OLAP operations. This operation includes drill up, drill down, pivoting, slice and
dice.
Data Warehouse Architecture:
Data warehouse follows three-tier architecture. The tiers are elaborated as follows:
Bottom Tier
The database server is the heart of the bottom tier. It is the relational database system. To input
data into the bottom tier, some back end tools and utilities are used. The important functions like
Extract, load, clean and refresh are performed by these tools and utilities.
Middle Tier
OLAP server is placed in the middle tier which is implemented in one of the following manner:
1. ROLAP: Relational OLAP is an extended RDBMS (Relational Database Management
System). It converts operation on multidimensional data to standard relational operations.
2. MOLAP: Multidimensional OLAP implements multidimensional data and operations.
Top-Tier
is referred to as data mining. The main techniques for data mining include classification,
regression and prediction. The visualization tools are used for presenting the data mining results
Information Processing
The data warehouse which allows analysts to process the data that is stored in it. Basically query
is the way of processing the data. Moreover it supports basic statistical analysis and reports are
generated using tables and graphs, charts, etc..
Analytical Processing
Analytical processing is supported by the data warehouse so that data can be processed on the
basis of basic OLAP operations. This operation includes drill up, drill down, pivoting, slice and
dice.
Data Warehouse Architecture:
Data warehouse follows three-tier architecture. The tiers are elaborated as follows:
Bottom Tier
The database server is the heart of the bottom tier. It is the relational database system. To input
data into the bottom tier, some back end tools and utilities are used. The important functions like
Extract, load, clean and refresh are performed by these tools and utilities.
Middle Tier
OLAP server is placed in the middle tier which is implemented in one of the following manner:
1. ROLAP: Relational OLAP is an extended RDBMS (Relational Database Management
System). It converts operation on multidimensional data to standard relational operations.
2. MOLAP: Multidimensional OLAP implements multidimensional data and operations.
Top-Tier
Paraphrase This Document
Need a fresh take? Get an instant paraphrase of this document with our AI Paraphraser

It is the front end layer which contains querying tools that can be handles by the analysts. It also
contains analysis, reporting and mining tools.
1.4 Business Intelligence
The term 'Business Intelligence' has evolved from the decision support systems and gained
strength with the technology and applications like data warehouses, Executive Information
Systems and Online Analytical Processing (OLAP). Business Intelligence System is basically a
system used for finding patterns from existing data from operations.
1.5 Literature Review
Data Mining for Banks:
As banking competition becomes more and more global and intense, banks have to fight more
creatively and proactively to gain or even maintain market shares. Banks which still rely on
contains analysis, reporting and mining tools.
1.4 Business Intelligence
The term 'Business Intelligence' has evolved from the decision support systems and gained
strength with the technology and applications like data warehouses, Executive Information
Systems and Online Analytical Processing (OLAP). Business Intelligence System is basically a
system used for finding patterns from existing data from operations.
1.5 Literature Review
Data Mining for Banks:
As banking competition becomes more and more global and intense, banks have to fight more
creatively and proactively to gain or even maintain market shares. Banks which still rely on

reactive customer service techniques and conventional mass marketing are doomed to failure or
atrophy. The banks of the future will use one asset, knowledge and not financial resources, as
their leverage for survival and excellence. Surprisingly, most of this knowledge are currently in
the banking system and generated by daily transactions and operations. This valuable
information need not be gathered by intrusive customer surveys or expensive market research
programs. The only problem is that this storehouse of data has to be mined for useful
information. Normally unmined and unappreciated, these terabytes of transaction data are
collected, generated, printed, stored, only to be filed and discarded after they have served their
short-lived purposes as audit trails and paper trails. Most data generated by the bank's
information systems, manual or automated like ATM's and credit card processing, were designed
to support or track transactions, satisfy internal and external audit requirements, and meet
government or central bank regulations. Few are gathered intentionally and originally to generate
useful management reports. Current information systems are not designed as decision support
systems (DSS) that would help management make effective decisions to manage resources,
compete successfully, and enhance customer satisfaction and service. Consequently, adhoc or
even the most basic management reports have to be extracted excruciatingly from scattered and
autonomous data centers or islands of automation that use incompatible formats. The results are
management reports that are perennially late, inaccurate, and incomplete. Executive decisions
based on these misleading reports can lead to millions of dollars in short and long term losses
and lost opportunities and markets.
The tremendous increase in the power of information technology will enable banks to tap
existing information systems, also known as legacy systems, and mine useful management
information and insights from the data stored in them. This process can be done without the need
to change the current systems and the data they generate. But before data mining can proceed, a
data warehouse will have to be created first. Data warehousing is the process of extracting,
cleaning, transforming, and standardizing incompatible data from the bank's current systems so
that these data can be mined and analyzed for useful patterns, relationships, and associations.
The data warehouse need not be updated as regularly or daily as the transaction based systems.
Data warehouses can be updated and mined as infrequently as the need for management reports
and decisions dictate, i.e., monthly, quarterly, or on a ad hoc basis. Data warehousing and mining
atrophy. The banks of the future will use one asset, knowledge and not financial resources, as
their leverage for survival and excellence. Surprisingly, most of this knowledge are currently in
the banking system and generated by daily transactions and operations. This valuable
information need not be gathered by intrusive customer surveys or expensive market research
programs. The only problem is that this storehouse of data has to be mined for useful
information. Normally unmined and unappreciated, these terabytes of transaction data are
collected, generated, printed, stored, only to be filed and discarded after they have served their
short-lived purposes as audit trails and paper trails. Most data generated by the bank's
information systems, manual or automated like ATM's and credit card processing, were designed
to support or track transactions, satisfy internal and external audit requirements, and meet
government or central bank regulations. Few are gathered intentionally and originally to generate
useful management reports. Current information systems are not designed as decision support
systems (DSS) that would help management make effective decisions to manage resources,
compete successfully, and enhance customer satisfaction and service. Consequently, adhoc or
even the most basic management reports have to be extracted excruciatingly from scattered and
autonomous data centers or islands of automation that use incompatible formats. The results are
management reports that are perennially late, inaccurate, and incomplete. Executive decisions
based on these misleading reports can lead to millions of dollars in short and long term losses
and lost opportunities and markets.
The tremendous increase in the power of information technology will enable banks to tap
existing information systems, also known as legacy systems, and mine useful management
information and insights from the data stored in them. This process can be done without the need
to change the current systems and the data they generate. But before data mining can proceed, a
data warehouse will have to be created first. Data warehousing is the process of extracting,
cleaning, transforming, and standardizing incompatible data from the bank's current systems so
that these data can be mined and analyzed for useful patterns, relationships, and associations.
The data warehouse need not be updated as regularly or daily as the transaction based systems.
Data warehouses can be updated and mined as infrequently as the need for management reports
and decisions dictate, i.e., monthly, quarterly, or on a ad hoc basis. Data warehousing and mining
⊘ This is a preview!⊘
Do you want full access?
Subscribe today to unlock all pages.
Trusted by 1+ million students worldwide

can run parallel with banking transaction information systems, without intrusion and
interruptions.
What are the benefits and application of data mining in the banking industry? One of the earliest
application of data mining was in retail supermarket. Mining the volumes of point of sale (POS)
data generated daily by cash registers, the store management analyzed the housewife's shopping
basket, and discovered which items were often bought together. This knowledge led to changes
in store layout the brought the related items physically closer and better promotions that
packaged and sold the related items together. The knowledge discovered also led to better
stocking and inventory management. Retailers like WalMart have experienced sales increase as
much as 20% after extensively applying data mining. Some frequently bought item pairs
discovered by data mining may be obvious, like toothbrush and toothpaste, wine and cheese,
chips and soda. Some were unexpected and bizarre like disposable diapers and beer on Friday
nights.
In banking, the questions data mining can possibly answer are:
1. What transactions does a customer do before shifting to a competitor bank? (to prevent
attrition)
2. What is the profile of an ATM customer and what type of products is he likely to buy? (to
cross sell)
3. Which bank products are often availed of together by which groups of customers? (to cross
sell and do target marketing)
4. What patterns in credit transactions lead to fraud? (to detect and deter fraud)
5. What is the profile of a high-risk borrower? (to prevent defaults, bad loans, and improve
screening)
6. What services and benefits would current customers likely desire? (to increase loyalty and
customer retention)
Note that data mining does not start with a hypothesis that has to be proven or disproven. It is an
exploratory process aimed at "knowledge discovery" rather than the traditional "knowledge
verification". Knowledge verification DSS otherwise known as OLAP (on line analytical
interruptions.
What are the benefits and application of data mining in the banking industry? One of the earliest
application of data mining was in retail supermarket. Mining the volumes of point of sale (POS)
data generated daily by cash registers, the store management analyzed the housewife's shopping
basket, and discovered which items were often bought together. This knowledge led to changes
in store layout the brought the related items physically closer and better promotions that
packaged and sold the related items together. The knowledge discovered also led to better
stocking and inventory management. Retailers like WalMart have experienced sales increase as
much as 20% after extensively applying data mining. Some frequently bought item pairs
discovered by data mining may be obvious, like toothbrush and toothpaste, wine and cheese,
chips and soda. Some were unexpected and bizarre like disposable diapers and beer on Friday
nights.
In banking, the questions data mining can possibly answer are:
1. What transactions does a customer do before shifting to a competitor bank? (to prevent
attrition)
2. What is the profile of an ATM customer and what type of products is he likely to buy? (to
cross sell)
3. Which bank products are often availed of together by which groups of customers? (to cross
sell and do target marketing)
4. What patterns in credit transactions lead to fraud? (to detect and deter fraud)
5. What is the profile of a high-risk borrower? (to prevent defaults, bad loans, and improve
screening)
6. What services and benefits would current customers likely desire? (to increase loyalty and
customer retention)
Note that data mining does not start with a hypothesis that has to be proven or disproven. It is an
exploratory process aimed at "knowledge discovery" rather than the traditional "knowledge
verification". Knowledge verification DSS otherwise known as OLAP (on line analytical
Paraphrase This Document
Need a fresh take? Get an instant paraphrase of this document with our AI Paraphraser

processing) would ask straighforward questions like "how many card holders defaulted this
month compared to the same month last year?" or "how many of our ATM customers are also
borrowers?" While OLAP queries are useful, they are not as insightful, powerful, and as focused
as data mining queries, especially in preempting competition or preventing customer attrition.
The data miner does not have a priori knowledge or assumptions. The data mining software will
usually reveal unexpected patterns and opportunities and make its own hypothesis.
Data mining will be the cornerstone of the competitive if not the survival strategy for the next
millennium in banking. Banks which ignore it are giving away their future to competitors which
today are busy mining. (Rene, 2003)
1.6 Objectives
The objectives of the project are as listed below:
1. To select a suitable dataset for designing data warehouse.
2. To find and download the dataset.
3. To design a data warehouse for the selected dataset.
4. To select a tool for implementing the data warehouse.
5. To implement the data warehouse in MS Access 2007.
6. To populate the data from dataset to data warehouse.
7. To query and process the data such that all the research questions should be
answered.
8. To generate all the answers to the queries.
month compared to the same month last year?" or "how many of our ATM customers are also
borrowers?" While OLAP queries are useful, they are not as insightful, powerful, and as focused
as data mining queries, especially in preempting competition or preventing customer attrition.
The data miner does not have a priori knowledge or assumptions. The data mining software will
usually reveal unexpected patterns and opportunities and make its own hypothesis.
Data mining will be the cornerstone of the competitive if not the survival strategy for the next
millennium in banking. Banks which ignore it are giving away their future to competitors which
today are busy mining. (Rene, 2003)
1.6 Objectives
The objectives of the project are as listed below:
1. To select a suitable dataset for designing data warehouse.
2. To find and download the dataset.
3. To design a data warehouse for the selected dataset.
4. To select a tool for implementing the data warehouse.
5. To implement the data warehouse in MS Access 2007.
6. To populate the data from dataset to data warehouse.
7. To query and process the data such that all the research questions should be
answered.
8. To generate all the answers to the queries.

2 Design
2.5 Technology Used
The technology used for the design and implementation is MS Access 2007. It is one of
the best tools available for querying and analyzing the large data. The four research
questions related to this dataset are need to be answered they are:
1. What is the currency of the money?
2. Is any address used once or twice in this dataset?
3. The names used to open this account, are they repeated?
4. Is there any address to visit these owners?
2.6 Implementation
The following diagram shows the data warehouse design for the selected dataset. The
tables included in the warehouse are customer, Bank and Transaction. These tables are
connected through a simple table named as Dimension. The dataset containing 7 rows are
divided in 3 tables which are interconnected by the Dimension table.
2.7 Operation and Processing
First step is to create all the tables in MS Access.
1. Bank Table:
2.5 Technology Used
The technology used for the design and implementation is MS Access 2007. It is one of
the best tools available for querying and analyzing the large data. The four research
questions related to this dataset are need to be answered they are:
1. What is the currency of the money?
2. Is any address used once or twice in this dataset?
3. The names used to open this account, are they repeated?
4. Is there any address to visit these owners?
2.6 Implementation
The following diagram shows the data warehouse design for the selected dataset. The
tables included in the warehouse are customer, Bank and Transaction. These tables are
connected through a simple table named as Dimension. The dataset containing 7 rows are
divided in 3 tables which are interconnected by the Dimension table.
2.7 Operation and Processing
First step is to create all the tables in MS Access.
1. Bank Table:
⊘ This is a preview!⊘
Do you want full access?
Subscribe today to unlock all pages.
Trusted by 1+ million students worldwide
1 out of 14

Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Unlock your academic potential
Copyright © 2020–2026 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.