Deakin University MIS772 Predictive Analytics Assignment A2 Report
VerifiedAdded on 2022/12/18
|14
|3341
|1
Report
AI Summary
This report details a student's analysis of the Zomato restaurant dataset for MIS772 Predictive Analytics, focusing on Bangalore Food Assist (BFA). The assignment involves data exploration, clustering, and the development of an estimation model using RapidMiner. The student investigates restaurant reviews, identifies anomalies, and builds models using Random Forest and neural nets classifiers to predict restaurant ratings. The report includes data preprocessing, model evaluation using MAE, RMSE, and correlation, and provides insights into table booking and online ordering strategies. The objective is to create a data mining strategy to determine if restaurants should provide online ordering and table booking services. The student explores attributes like restaurant names, types, locations, menus, and customer reviews, to build a model for BFA to predict restaurant ratings. The report also highlights the use of various RapidMiner operators such as Read CSV, Normalize, Filter Examples, and the creation of correlation matrices and decision trees to gain insights from the data. The goal is to build a model with high precision, measured by MAE, RMSE, and correlation, to assist restaurant owners in understanding their expected ratings on the Zomato website.
MIS772 Predictive Analytics (2019 T2) Individual Assignment A2 / All Workshops
Assignment A2: Text + Clustering + Estimation
Student
Name
(as per record) Student No Student number
My other group members A2
Group No
As per CloudDeakin group
number
Team
Names
(as per record) Student Nos Student number
(as per record) Student number
(as per record) Student number
Exceptional Meets expectations Issues noted Improve Unacceptable
Exec
Report
Use this area to self-assess your submission
Explore
Attributes
Be realistic as we will find problems in your work that you may not be aware of
Discover
Relationships
Create
Models
Evaluate &
Improve
Provide
Solution
Research &
Extend
Brief
Comments
Read these notes as we are really trying to help you out!
Remember: If it is not in this report, it does not exist and does not get marked!
Assume that markers could miss some important aspects of your submission unless presented clearly, or when
you deviate from the structure of this template (for which you will be penalised). So be clear, number tables,
charts and screen shots used as evidence, annotate all visuals, cross-reference your analysis with evidence.
Use the A2 Word template to prepare this report. Submit it in PDF format to avoid its accidental reformatting.
Submit all RM processes (.RMP files only – not the whole project directory or data) in a separate ZIP archive.
Only work submitted via CloudDeakin assignment box will be marked (not via email or any other way).
Ensure that the report is readable and the font is no smaller than Arial 10 points. Include only the most relevant
and significant results for your analysis and recommendations.
You will be able to submit your work as many times until deadline. We will mark the last complete submission,
i.e. the report in PDF and the ZIP-ped RapidMiner processes.
Go over this checklist: Is this your document? Does it report your work and your work only? Is this the correct
unit, assignment, year and trimester? Is your name entered above? Is the group number included and is it
correct? Are names of your group members entered as well? Are all pages included? Are all report sections
within the required page limit?
Then after the submission – check these: Was it lodged on time? Has the PDF report been submitted? Has the
Zip archive of RMP files been submitted? Can you retrieve and reopen both back from your submission folder?
We will be checking your work for plagiarism! If any parts of your work (report, screen shots or RM
processes) bear any resemblance to another students’ work, or by you for another unit, or anything
written by others without acknowledgement (e.g. on the web), it will be treated as plagiarism.
Total
1 of 14
Assignment A2: Text + Clustering + Estimation
Student
Name
(as per record) Student No Student number
My other group members A2
Group No
As per CloudDeakin group
number
Team
Names
(as per record) Student Nos Student number
(as per record) Student number
(as per record) Student number
Exceptional Meets expectations Issues noted Improve Unacceptable
Exec
Report
Use this area to self-assess your submission
Explore
Attributes
Be realistic as we will find problems in your work that you may not be aware of
Discover
Relationships
Create
Models
Evaluate &
Improve
Provide
Solution
Research &
Extend
Brief
Comments
Read these notes as we are really trying to help you out!
Remember: If it is not in this report, it does not exist and does not get marked!
Assume that markers could miss some important aspects of your submission unless presented clearly, or when
you deviate from the structure of this template (for which you will be penalised). So be clear, number tables,
charts and screen shots used as evidence, annotate all visuals, cross-reference your analysis with evidence.
Use the A2 Word template to prepare this report. Submit it in PDF format to avoid its accidental reformatting.
Submit all RM processes (.RMP files only – not the whole project directory or data) in a separate ZIP archive.
Only work submitted via CloudDeakin assignment box will be marked (not via email or any other way).
Ensure that the report is readable and the font is no smaller than Arial 10 points. Include only the most relevant
and significant results for your analysis and recommendations.
You will be able to submit your work as many times until deadline. We will mark the last complete submission,
i.e. the report in PDF and the ZIP-ped RapidMiner processes.
Go over this checklist: Is this your document? Does it report your work and your work only? Is this the correct
unit, assignment, year and trimester? Is your name entered above? Is the group number included and is it
correct? Are names of your group members entered as well? Are all pages included? Are all report sections
within the required page limit?
Then after the submission – check these: Was it lodged on time? Has the PDF report been submitted? Has the
Zip archive of RMP files been submitted? Can you retrieve and reopen both back from your submission folder?
We will be checking your work for plagiarism! If any parts of your work (report, screen shots or RM
processes) bear any resemblance to another students’ work, or by you for another unit, or anything
written by others without acknowledgement (e.g. on the web), it will be treated as plagiarism.
Total
1 of 14
Paraphrase This Document
Need a fresh take? Get an instant paraphrase of this document with our AI Paraphraser

MIS772 Predictive Analytics (2019 T2) Individual Assignment A2 / All Workshops
Executive summary (one page)
The fundamental point of this task to build up the Zomato nourishment food information
mining investigation systems they can utilized for the quick digger programming execution. The
examining on the Zomato food dataset they can contains the diverse activity information fields they can
handled. This present venture's point is spins around building up an information mining technique, which
guarantees to help during the time spent deciding if the cafés are required to give a few administrations
in particular the online super requesting just as booking the table to its clients for the Bangalore
nourishment help (BFA). BFA alludes to an Indian organization which is associated with the Zomato
café search and the disclosure site. By and large, BFA causes the organizations to give the example
audits of about 48000 Zomato food order booking system they can contained the data fields, which
involves the accompanying characteristics of the data attributes list,
Restaurant name
Restaurant sort
Contact Number
Location
Address
Neighbourhood
Rate of visit
Menu
Cuisine and kind of dinners
Average supper cost for the couple.
Number of votes cast
Liked dishes
Reviews
The point of BFA is to accumulate couple of initial bits of knowledge of the ordering
food and delivery service in Bangalore, for investigating and to tidy up the convey their audits so as to
inspect and make eatery table's classifier for their table booking, for requesting on the web and to
diminish the orders that aren't right. The apparatus named Rapid Miner is used for the advancement of
BFA's information mining technique, and during the time spent information mining this device is
profoundly basic. The eatery surveys are investigated and tidied up with the assistance of Set job,
Normalize, Selecting Attributes on a Rapid Mining information mining method analysis
implementation. .
2 of 14
Executive summary (one page)
The fundamental point of this task to build up the Zomato nourishment food information
mining investigation systems they can utilized for the quick digger programming execution. The
examining on the Zomato food dataset they can contains the diverse activity information fields they can
handled. This present venture's point is spins around building up an information mining technique, which
guarantees to help during the time spent deciding if the cafés are required to give a few administrations
in particular the online super requesting just as booking the table to its clients for the Bangalore
nourishment help (BFA). BFA alludes to an Indian organization which is associated with the Zomato
café search and the disclosure site. By and large, BFA causes the organizations to give the example
audits of about 48000 Zomato food order booking system they can contained the data fields, which
involves the accompanying characteristics of the data attributes list,
Restaurant name
Restaurant sort
Contact Number
Location
Address
Neighbourhood
Rate of visit
Menu
Cuisine and kind of dinners
Average supper cost for the couple.
Number of votes cast
Liked dishes
Reviews
The point of BFA is to accumulate couple of initial bits of knowledge of the ordering
food and delivery service in Bangalore, for investigating and to tidy up the convey their audits so as to
inspect and make eatery table's classifier for their table booking, for requesting on the web and to
diminish the orders that aren't right. The apparatus named Rapid Miner is used for the advancement of
BFA's information mining technique, and during the time spent information mining this device is
profoundly basic. The eatery surveys are investigated and tidied up with the assistance of Set job,
Normalize, Selecting Attributes on a Rapid Mining information mining method analysis
implementation. .
2 of 14

MIS772 Predictive Analytics (2019 T2) Individual Assignment A2 / All Workshops
For creating and investigating a classifier for the BFA eatery for Booking a table administration and
online dinner requesting administration, the two groupings in particular the Random timberland and neural nets
arrangements are utilized to diminish an inappropriate order. In this way, this report will quickly talk about and
examine the previously mentioned zones. The breaking down on the outcome to be confirmed on the diagram
and graph position.
3 of 14
For creating and investigating a classifier for the BFA eatery for Booking a table administration and
online dinner requesting administration, the two groupings in particular the Random timberland and neural nets
arrangements are utilized to diminish an inappropriate order. In this way, this report will quickly talk about and
examine the previously mentioned zones. The breaking down on the outcome to be confirmed on the diagram
and graph position.
3 of 14
⊘ This is a preview!⊘
Do you want full access?
Subscribe today to unlock all pages.
Trusted by 1+ million students worldwide

MIS772 Predictive Analytics (2019 T2) Individual Assignment A2 / All Workshops
Data exploration and relationships - Clustering in Rapid Miner (one page)
Here, a model is made on the Rapid Miner with the assistance of the given information of
the café. The model creation uses the Random Forest and the generalized linear regression classifiers. The
underneath chart portrays the creation model for these two classifiers.
For making a model, at first it is required to incorporate the read CSV administrator for perusing
the information of the eatery. Next, it is required to supplant the missing qualities with the assistance of
the standardize administrator, as it may affect the consequences of our model. At that point, with the
assistance of the Random Forest and generalized linear regression classifiers administrator characterize
the mark credits to be anticipated. Further, the required characteristics are chosen for including it to
foresee the properties. The accompanying figure portrays the choice tree.
During the formation of the model, the exactness parameters are chosen on the classifier,
promotion it is used for estimating the indicator's precision and their presentation. Different parameters
and profundity and set as default. For demonstrating a viable model for Zomato eatery information BFA,
the Random Forest is used. The underneath figure delineates the yield of the generalized linear regression
classifiers calculation
The following list represents the attributes for exploring the given data:
1) Restaurant name
2) Restaurant type
3) Location
4) Address
5) Menu
6) Cuisine and type of meals
7) Reviews etc.
The following figure represents the data exploration and preparation.
4 of 14
Data exploration and relationships - Clustering in Rapid Miner (one page)
Here, a model is made on the Rapid Miner with the assistance of the given information of
the café. The model creation uses the Random Forest and the generalized linear regression classifiers. The
underneath chart portrays the creation model for these two classifiers.
For making a model, at first it is required to incorporate the read CSV administrator for perusing
the information of the eatery. Next, it is required to supplant the missing qualities with the assistance of
the standardize administrator, as it may affect the consequences of our model. At that point, with the
assistance of the Random Forest and generalized linear regression classifiers administrator characterize
the mark credits to be anticipated. Further, the required characteristics are chosen for including it to
foresee the properties. The accompanying figure portrays the choice tree.
During the formation of the model, the exactness parameters are chosen on the classifier,
promotion it is used for estimating the indicator's precision and their presentation. Different parameters
and profundity and set as default. For demonstrating a viable model for Zomato eatery information BFA,
the Random Forest is used. The underneath figure delineates the yield of the generalized linear regression
classifiers calculation
The following list represents the attributes for exploring the given data:
1) Restaurant name
2) Restaurant type
3) Location
4) Address
5) Menu
6) Cuisine and type of meals
7) Reviews etc.
The following figure represents the data exploration and preparation.
4 of 14
Paraphrase This Document
Need a fresh take? Get an instant paraphrase of this document with our AI Paraphraser
MIS772 Predictive Analytics (2019 T2) Individual Assignment A2 / All Workshops
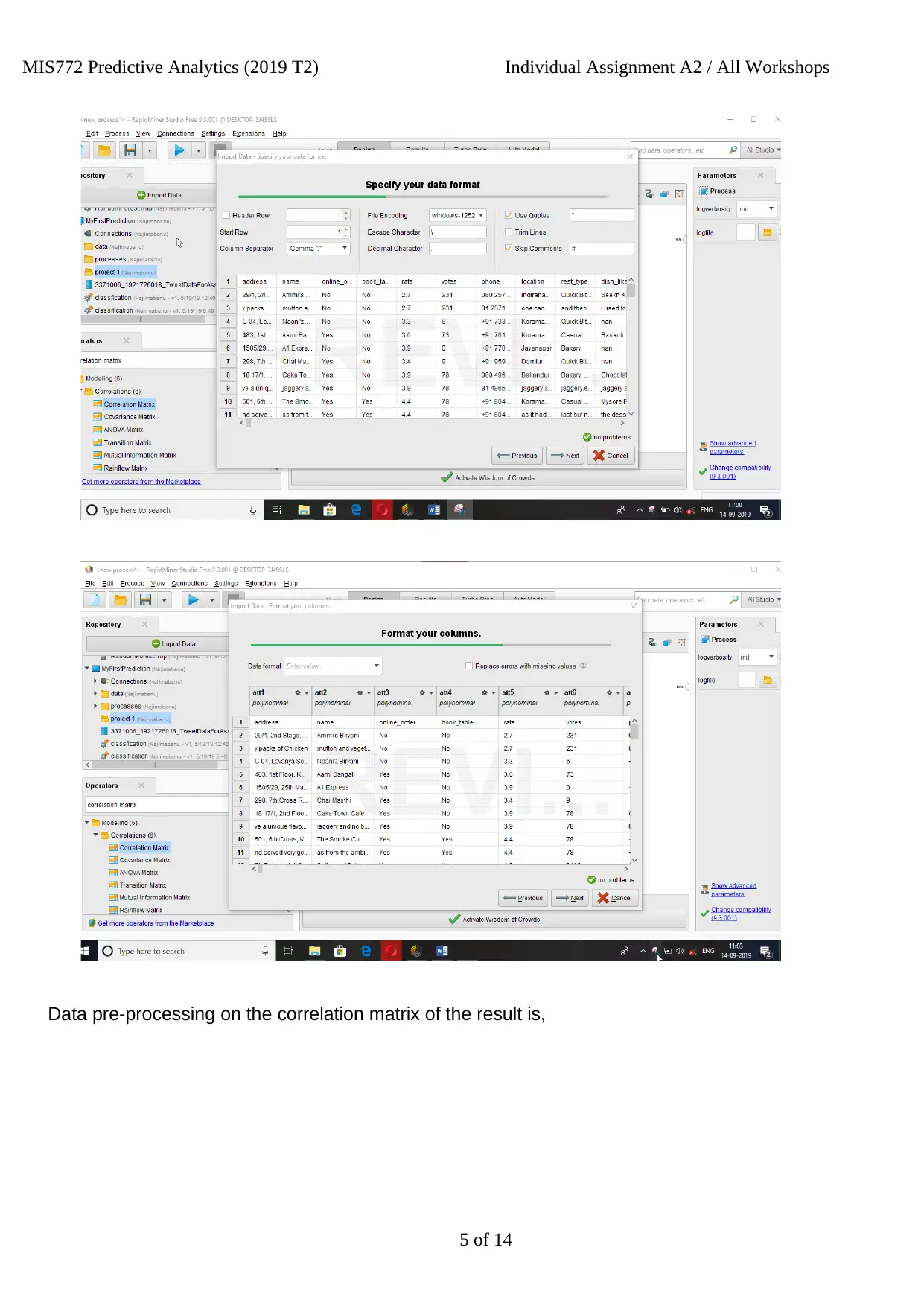
Data pre-processing on the correlation matrix of the result is,
5 of 14
Data pre-processing on the correlation matrix of the result is,
5 of 14
MIS772 Predictive Analytics (2019 T2) Individual Assignment A2 / All Workshops
6 of 14
6 of 14
⊘ This is a preview!⊘
Do you want full access?
Subscribe today to unlock all pages.
Trusted by 1+ million students worldwide

MIS772 Predictive Analytics (2019 T2) Individual Assignment A2 / All Workshops
Data exploration and clean up - Anomalies in RapidMiner (one page)
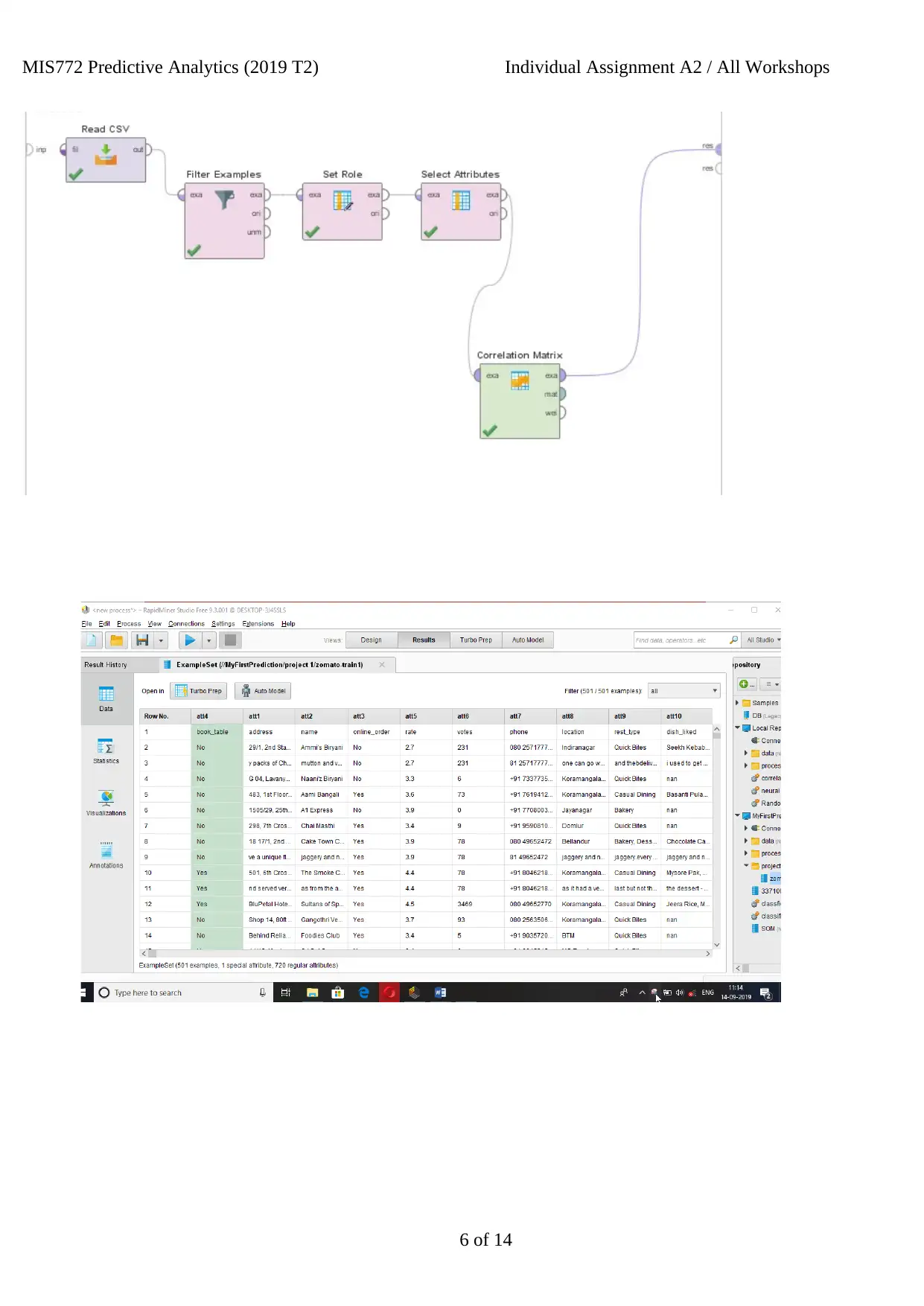
Here, the connections and the information change will be found that is given in the eatery
information, with the assistance of Rapid Miner. A relationship grid must be made for distinguishing the
association of the information and its change. The administrators like Filter Examples, Read CSV, Set jobs,
connection framework and select credits are utilized to make the relationship network. The underneath figure
portrays the classification connections on the data mining method.
For making a model, at first it is required to incorporate the read CSV administrator for perusing the
information of the eatery. Next, it is required to analysing data the missing qualities with the assistance of the
standardize administrator, as it may affect the aftereffects of our model. At that point, with the assistance of the
Random Forest and generalized linear regression administrator characterize the mark ascribes to be anticipated.
Further, the required characteristics are chosen for including it to anticipate the properties. The accompanying
figure portrays the decision tree.
7 of 14
Data exploration and clean up - Anomalies in RapidMiner (one page)
Here, the connections and the information change will be found that is given in the eatery
information, with the assistance of Rapid Miner. A relationship grid must be made for distinguishing the
association of the information and its change. The administrators like Filter Examples, Read CSV, Set jobs,
connection framework and select credits are utilized to make the relationship network. The underneath figure
portrays the classification connections on the data mining method.
For making a model, at first it is required to incorporate the read CSV administrator for perusing the
information of the eatery. Next, it is required to analysing data the missing qualities with the assistance of the
standardize administrator, as it may affect the aftereffects of our model. At that point, with the assistance of the
Random Forest and generalized linear regression administrator characterize the mark ascribes to be anticipated.
Further, the required characteristics are chosen for including it to anticipate the properties. The accompanying
figure portrays the decision tree.
7 of 14
Paraphrase This Document
Need a fresh take? Get an instant paraphrase of this document with our AI Paraphraser
MIS772 Predictive Analytics (2019 T2) Individual Assignment A2 / All Workshops
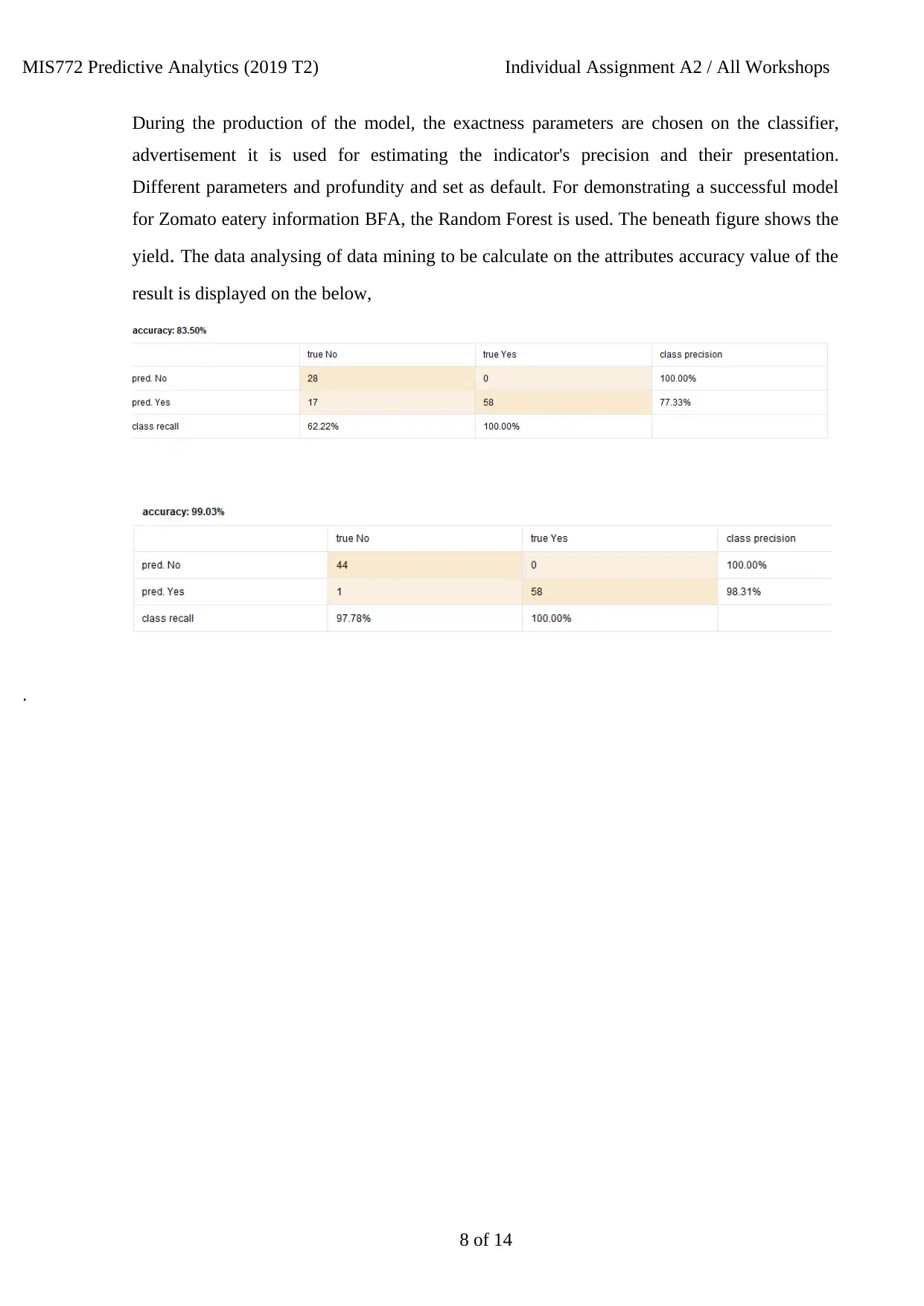
During the production of the model, the exactness parameters are chosen on the classifier,
advertisement it is used for estimating the indicator's precision and their presentation.
Different parameters and profundity and set as default. For demonstrating a successful model
for Zomato eatery information BFA, the Random Forest is used. The beneath figure shows the
yield. The data analysing of data mining to be calculate on the attributes accuracy value of the
result is displayed on the below,
.
8 of 14
During the production of the model, the exactness parameters are chosen on the classifier,
advertisement it is used for estimating the indicator's precision and their presentation.
Different parameters and profundity and set as default. For demonstrating a successful model
for Zomato eatery information BFA, the Random Forest is used. The beneath figure shows the
yield. The data analysing of data mining to be calculate on the attributes accuracy value of the
result is displayed on the below,
.
8 of 14

MIS772 Predictive Analytics (2019 T2) Individual Assignment A2 / All Workshops
Create a Model(s) in RapidMiner (two pages / page 1)
Here, a model is created on the Rapid Miner with the help of the given data of the restaurant. The model
creation utilizes the Random Forest and the neural nets classifiers. The below diagram depicts the creation
model for these two classifiers.
The name credits are required to make the connection lattice that is determined for the situation
concentrate, for example, the book table. At that point, the suggestions are assessed. The accompanying figure
outlines the relationship lattice, during the creation of the model, the accuracy parameters are selected on the
classifier, ad it is utilized for measuring the predictor’s accuracy and their performance. The other parameters
and depth and set as default. For proving an effective model for Zomato restaurant data BFA, the Random
Forest is utilized. The below figure illustrates the output.
9 of 14
Create a Model(s) in RapidMiner (two pages / page 1)
Here, a model is created on the Rapid Miner with the help of the given data of the restaurant. The model
creation utilizes the Random Forest and the neural nets classifiers. The below diagram depicts the creation
model for these two classifiers.
The name credits are required to make the connection lattice that is determined for the situation
concentrate, for example, the book table. At that point, the suggestions are assessed. The accompanying figure
outlines the relationship lattice, during the creation of the model, the accuracy parameters are selected on the
classifier, ad it is utilized for measuring the predictor’s accuracy and their performance. The other parameters
and depth and set as default. For proving an effective model for Zomato restaurant data BFA, the Random
Forest is utilized. The below figure illustrates the output.
9 of 14
⊘ This is a preview!⊘
Do you want full access?
Subscribe today to unlock all pages.
Trusted by 1+ million students worldwide

MIS772 Predictive Analytics (2019 T2) Individual Assignment A2 / All Workshops
Create a Model(s) in Rapid Miner (two pages / page 2)
The model that is made uses two or three classifiers called the Random Forest classifier and
the generalized linear regression classifier, where the Random Forest utilizes four criteria; where the
precision criteria is chosen for giving the model's exact expectation, which is later used for deciding the
two administrations, thus it gives successful results for the clients of the BFA organization. This is then
connected on the Example sets with the numerical qualities, anyway just on the ostensible properties. It
conveys the yields like the Random Forest and the model set.
Both, standard deviation and fantastic execution estimation of the made model is conceivable
with the cross-approval execution, which detects the information. The previously mentioned exhibition
of the café information and its estimation is affected by over fitting. The Kaggle site is utilized for
breaking down the information arrangement. The accompanying figure delineates the made model's
arrangement
10 of 14
Create a Model(s) in Rapid Miner (two pages / page 2)
The model that is made uses two or three classifiers called the Random Forest classifier and
the generalized linear regression classifier, where the Random Forest utilizes four criteria; where the
precision criteria is chosen for giving the model's exact expectation, which is later used for deciding the
two administrations, thus it gives successful results for the clients of the BFA organization. This is then
connected on the Example sets with the numerical qualities, anyway just on the ostensible properties. It
conveys the yields like the Random Forest and the model set.
Both, standard deviation and fantastic execution estimation of the made model is conceivable
with the cross-approval execution, which detects the information. The previously mentioned exhibition
of the café information and its estimation is affected by over fitting. The Kaggle site is utilized for
breaking down the information arrangement. The accompanying figure delineates the made model's
arrangement
10 of 14
Paraphrase This Document
Need a fresh take? Get an instant paraphrase of this document with our AI Paraphraser

MIS772 Predictive Analytics (2019 T2) Individual Assignment A2 / All Workshops
Evaluate and Improve the Model(s) in Rapid Miner (two pages / page 1)
This administrator ought to be utilized for execution assessment of relapse undertakings as it were. Numerous
other exhibition assessment administrators are additionally accessible in Rapid Miner for example the
Performance administrator, Performance (polynomial Classification) administrator, and Performance
(Classification) administrator and so on. The Performance (generalized linear Regression) administrator is
utilized with relapse undertakings as it were. Then again, the Performance administrator consequently decides
the learning assignment type and computes the most widely recognized criteria for that type. You can utilize the
Performance (User-Based) administrator in the event that you need to compose your very own presentation
measure.
Relapse is a strategy utilized for numerical forecast and it is a factual measure that endeavor to
decide the quality of the connection between one ward variable ( for example the mark trait) and a progression
of other changing factors known as autonomous factors (customary qualities). Much the same as Classification
is utilized for clear cut marks, Regression is utilized for anticipating a consistent worth. For instance, we may
wish to foresee the pay of college graduates with 5 years of work understanding, or the potential offers of
another item given its cost. Relapse is regularly used to decide how much explicit factors, for example, the cost
of an item, book, order, food, specific enterprises or areas impact the value development of an advantage. For
assessing the factual exhibition of a relapse model the informational collection ought to be named for example it
ought to have a characteristic with name job and a property with forecast job. The mark property stores the
genuine watched values though the expectation trait stores the estimations of name anticipated by the relapse
model under exchange.
11 of 14
Evaluate and Improve the Model(s) in Rapid Miner (two pages / page 1)
This administrator ought to be utilized for execution assessment of relapse undertakings as it were. Numerous
other exhibition assessment administrators are additionally accessible in Rapid Miner for example the
Performance administrator, Performance (polynomial Classification) administrator, and Performance
(Classification) administrator and so on. The Performance (generalized linear Regression) administrator is
utilized with relapse undertakings as it were. Then again, the Performance administrator consequently decides
the learning assignment type and computes the most widely recognized criteria for that type. You can utilize the
Performance (User-Based) administrator in the event that you need to compose your very own presentation
measure.
Relapse is a strategy utilized for numerical forecast and it is a factual measure that endeavor to
decide the quality of the connection between one ward variable ( for example the mark trait) and a progression
of other changing factors known as autonomous factors (customary qualities). Much the same as Classification
is utilized for clear cut marks, Regression is utilized for anticipating a consistent worth. For instance, we may
wish to foresee the pay of college graduates with 5 years of work understanding, or the potential offers of
another item given its cost. Relapse is regularly used to decide how much explicit factors, for example, the cost
of an item, book, order, food, specific enterprises or areas impact the value development of an advantage. For
assessing the factual exhibition of a relapse model the informational collection ought to be named for example it
ought to have a characteristic with name job and a property with forecast job. The mark property stores the
genuine watched values though the expectation trait stores the estimations of name anticipated by the relapse
model under exchange.
11 of 14

MIS772 Predictive Analytics (2019 T2) Individual Assignment A2 / All Workshops
Evaluate and Improve the Model(s) in RapidMiner (two pages / page 2)
The 'Polynomial' informational index is stacked utilizing the Retrieve administrator. The Filter
Example Range administrator is connected on it. The main model parameter of the Filter Example Range
parameter is set to 1 and the last model parameter is set to 100. In this way the initial 100 instances of the
'Polynomial' informational collection are chosen. The Linear Regression administrator is connected on it with
default estimations everything being equal. The relapse model produced by the generalized Linear Regression
administrator is connected on the last 100 instances of the 'Polynomial' informational collection utilizing the Apply
Model administrator. Marked information from the Apply Model administrator is given to the Performance
(Regression) administrator. The total mistake and forecast normal parameters are set to genuine. In this way the
Performance Vector produced by the Performance (Regression) administrator has data with respect to the total
mistake and forecast normal in the named informational index. The supreme blunder is determined by including
the distinction of all the anticipated qualities from real estimations of the mark characteristic, and separating this
whole by the complete number of forecasts. The expectation normal is determined by including all the genuine
mark esteems and partitioning this entirety by the all-out number of models. You can confirm this from the
outcomes in the Results Workspace.
12 of 14
Evaluate and Improve the Model(s) in RapidMiner (two pages / page 2)
The 'Polynomial' informational index is stacked utilizing the Retrieve administrator. The Filter
Example Range administrator is connected on it. The main model parameter of the Filter Example Range
parameter is set to 1 and the last model parameter is set to 100. In this way the initial 100 instances of the
'Polynomial' informational collection are chosen. The Linear Regression administrator is connected on it with
default estimations everything being equal. The relapse model produced by the generalized Linear Regression
administrator is connected on the last 100 instances of the 'Polynomial' informational collection utilizing the Apply
Model administrator. Marked information from the Apply Model administrator is given to the Performance
(Regression) administrator. The total mistake and forecast normal parameters are set to genuine. In this way the
Performance Vector produced by the Performance (Regression) administrator has data with respect to the total
mistake and forecast normal in the named informational index. The supreme blunder is determined by including
the distinction of all the anticipated qualities from real estimations of the mark characteristic, and separating this
whole by the complete number of forecasts. The expectation normal is determined by including all the genuine
mark esteems and partitioning this entirety by the all-out number of models. You can confirm this from the
outcomes in the Results Workspace.
12 of 14
⊘ This is a preview!⊘
Do you want full access?
Subscribe today to unlock all pages.
Trusted by 1+ million students worldwide
1 out of 14
Related Documents





Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Unlock your academic potential
Copyright © 2020–2026 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.