MIS772 Predictive Analytics A1 Report: Classification Analysis
VerifiedAdded on 2022/11/15
|12
|2779
|167
Report
AI Summary
This report details a student's analysis of a predictive analytics assignment (MIS772) focused on classifying restaurant data using RapidMiner. The project aims to assist a company (Bangalore Food Assist, BFA) in determining whether to offer new services, such as online ordering and table pre-booking, based on customer reviews and restaurant attributes sourced from Zomato. The report covers data exploration, cleaning, and preparation, including handling missing values and transforming data using RapidMiner. It explores relationships between attributes using a correlation matrix. The core of the assignment involves creating and evaluating classification models, specifically KNN and Decision Tree, to predict service adoption. The model's performance is evaluated using accuracy and Kappa parameters. The deployment phase uses cross-validation to assess the model's statistical performance. The analysis provides insights into customer preferences and restaurant characteristics, supporting BFA in making informed decisions about service offerings. The report emphasizes the importance of accurate predictions for effective service delivery and leverages RapidMiner's capabilities for data mining and model building.
MIS772 Predictive Analytics (2019 T2) Individual Assignment A1 / Workshops M1T1-M1T3
Assignment A1-LP2: Classification
Student
Name
(as per record) Student No Student number
My other group members A1
Group No
As per CloudDeakin group
number
Team
Names
(as per record) Student Nos Student number
(as per record) Student number
(as per record) Student number
Exceptional Meets expectations Issues noted Improve Unacceptable
Exec
Report
Use this area to self-assess your submission
Explore
Attributes
Be realistic as we will find problems in your work that you may not be aware of
Discover
Relationships
Create
Models
Evaluate &
Improve
Provide
Solution
Research &
Extend
Brief
Comments
Read these notes as we are really trying to help you out!
Remember: If it is not in this report, it does not exist and does not get marked!
Assume that markers could miss some important aspects of your submission unless presented clearly, or when
you deviate from the structure of this template (for which you will be penalised). So be clear, number tables,
charts and screen shots used as evidence, annotate all visuals, cross-reference your analysis with evidence.
Use the A1 Word template to prepare this report. Submit it in PDFformat to avoid its accidental
reformatting.Submit all RM processes (.RMP files only – not the whole project directory or data) in a separate
ZIParchive. Only work submitted via CloudDeakin assignment box will be marked (not via email or any other
way).
Ensure that the report is readable and the font is no smaller than Arial 10 points. Include only the most relevant
and significant results for your analysis and recommendations.
You will be able to submit your work as many times until deadline. We will mark the last complete submission,
i.e. the report in PDF and the ZIP-pedRapidMiner processes.
Go over this checklist: Is this your document? Does it report your work and your work only? Is this the correct
unit, assignment, year and trimester? Is your name entered above? Is the group number included and is it
correct? Are names of your group members entered as well? Are all pages included? Are all report sections
within the required page limit?
Then after the submission – check these: Was it lodged on time? Has the PDF report been submitted? Has the
Zip archive of RMP files been submitted? Can you retrieve and reopen both back from your submission folder?
We will be checking your work for plagiarism! If any parts of your work(report, screen shots or RM
processes) bear any resemblance to another students’ work, or by you for another unit, or anything
written by others without acknowledgement (e.g. on the web), it will be treated as plagiarism.
Total
Executive summary (one page)’
1 of 12
Assignment A1-LP2: Classification
Student
Name
(as per record) Student No Student number
My other group members A1
Group No
As per CloudDeakin group
number
Team
Names
(as per record) Student Nos Student number
(as per record) Student number
(as per record) Student number
Exceptional Meets expectations Issues noted Improve Unacceptable
Exec
Report
Use this area to self-assess your submission
Explore
Attributes
Be realistic as we will find problems in your work that you may not be aware of
Discover
Relationships
Create
Models
Evaluate &
Improve
Provide
Solution
Research &
Extend
Brief
Comments
Read these notes as we are really trying to help you out!
Remember: If it is not in this report, it does not exist and does not get marked!
Assume that markers could miss some important aspects of your submission unless presented clearly, or when
you deviate from the structure of this template (for which you will be penalised). So be clear, number tables,
charts and screen shots used as evidence, annotate all visuals, cross-reference your analysis with evidence.
Use the A1 Word template to prepare this report. Submit it in PDFformat to avoid its accidental
reformatting.Submit all RM processes (.RMP files only – not the whole project directory or data) in a separate
ZIParchive. Only work submitted via CloudDeakin assignment box will be marked (not via email or any other
way).
Ensure that the report is readable and the font is no smaller than Arial 10 points. Include only the most relevant
and significant results for your analysis and recommendations.
You will be able to submit your work as many times until deadline. We will mark the last complete submission,
i.e. the report in PDF and the ZIP-pedRapidMiner processes.
Go over this checklist: Is this your document? Does it report your work and your work only? Is this the correct
unit, assignment, year and trimester? Is your name entered above? Is the group number included and is it
correct? Are names of your group members entered as well? Are all pages included? Are all report sections
within the required page limit?
Then after the submission – check these: Was it lodged on time? Has the PDF report been submitted? Has the
Zip archive of RMP files been submitted? Can you retrieve and reopen both back from your submission folder?
We will be checking your work for plagiarism! If any parts of your work(report, screen shots or RM
processes) bear any resemblance to another students’ work, or by you for another unit, or anything
written by others without acknowledgement (e.g. on the web), it will be treated as plagiarism.
Total
Executive summary (one page)’
1 of 12
Paraphrase This Document
Need a fresh take? Get an instant paraphrase of this document with our AI Paraphraser

MIS772 Predictive Analytics (2019 T2) Individual Assignment A1 / Workshops M1T1-M1T3
The main purpose of this assignment paper is to explore a data mining method;
that helps the restaurants in taking decision whether it should add couple of services in its current
services portfolio. The company; Bangloare Food Assist (BFA) is aim to discover the data by taking the
sample reviews from different restaurants located in entire Banglore which is nearly about 45000
restaurants and collect the different attributes. BFA is planning to add other services like acceptance of
online meal order as well as pre-booking of the customer’s order in restaurants in different location of
the restaurants. The company is also associated with other online food delivering organizations
accepting orders from various locations like Zomato and Swiggy online food ordering apps. BFA is
planning to have following attributes in its this project:
1) Name of the restaurant
2) Type of restaurant
3) Contact number of restaurant
4) Location of the restaurant
5) Address of the restaurant
6) Neighborhood
7) Menu and type of foods
8) Rate of the foods
9) Average cost of meal for a couple of persons
10) Number of votes cast
11) Mostly liked dishes
12) Reviews of the customers
The main aim of the company is to take a survey of restaurants operating in Bangalore
and to explore the additional data and reviews from the customers so that restaurant’s table classifier can
be more cleaned and additional provision of services can be offered to the customers. The analysis of the
project can also provide synergies to restaurants in providing best quality services to their customers and
to explore the range of services in their menu. Here in this project; a data mining tool is used in order to
gather information and analyze it. Rapid Miner tool has been used by the company to explore the data
information that provides a highly qualitative assurance for the project. The data and information
collected from the restaurants will be explored and cleaned up with the help of this tool.
Here in this project; for new service of advance booking of table and online ordering of
the food; a classifier will be developed that basically works on two classifications namely KNN
classifications and decision tree; that ultimately helps BFA in lowering of risk of the wrong
classifications.
2 of 12
The main purpose of this assignment paper is to explore a data mining method;
that helps the restaurants in taking decision whether it should add couple of services in its current
services portfolio. The company; Bangloare Food Assist (BFA) is aim to discover the data by taking the
sample reviews from different restaurants located in entire Banglore which is nearly about 45000
restaurants and collect the different attributes. BFA is planning to add other services like acceptance of
online meal order as well as pre-booking of the customer’s order in restaurants in different location of
the restaurants. The company is also associated with other online food delivering organizations
accepting orders from various locations like Zomato and Swiggy online food ordering apps. BFA is
planning to have following attributes in its this project:
1) Name of the restaurant
2) Type of restaurant
3) Contact number of restaurant
4) Location of the restaurant
5) Address of the restaurant
6) Neighborhood
7) Menu and type of foods
8) Rate of the foods
9) Average cost of meal for a couple of persons
10) Number of votes cast
11) Mostly liked dishes
12) Reviews of the customers
The main aim of the company is to take a survey of restaurants operating in Bangalore
and to explore the additional data and reviews from the customers so that restaurant’s table classifier can
be more cleaned and additional provision of services can be offered to the customers. The analysis of the
project can also provide synergies to restaurants in providing best quality services to their customers and
to explore the range of services in their menu. Here in this project; a data mining tool is used in order to
gather information and analyze it. Rapid Miner tool has been used by the company to explore the data
information that provides a highly qualitative assurance for the project. The data and information
collected from the restaurants will be explored and cleaned up with the help of this tool.
Here in this project; for new service of advance booking of table and online ordering of
the food; a classifier will be developed that basically works on two classifications namely KNN
classifications and decision tree; that ultimately helps BFA in lowering of risk of the wrong
classifications.
2 of 12

MIS772 Predictive Analytics (2019 T2) Individual Assignment A1 / Workshops M1T1-M1T3
Data exploration and preparation in RapidMiner (one page)
With the used of Rapid Miner; the collected data and information have been
explored and required report has been completed. In this project; the main sources of data information is
the Zomato Restaurants and it contains data information about 45000 restaurants including the reviews
of the customers.
The collected data and information from the Zomato; are further cleaned up by removal
of the useless attributes and missing information; and in order to revalue the data information; some
information has been replaced by new information that covers up the missing information in the data
base. With the use of this analyzed data; the data mining model has been prepared and for this data has
been analyzed based on the pre-defined characteristics. In the organized data information; a couple of
columns have been added; which could utilize online order service and book table service.
Therefore; with the use of these pre-defined attributes; the analysis has been done in order
to design the data mining tool. The analysis done based on these attributes helps BFA to analyze the
working pattern of the Zomato restaurants; and allowing them to add these new attributes for their
customers exploring them opportunities. The following list provided with the different attributes being
used in analysis done:
Name of the restaurant
Type of restaurant
Location of the restaurant
Address of the restaurant
Menu and type of foods
Rate of the foods
Reviews of the customers
Table providing information with respect to data preparation and exploration:
3 of 12
Data exploration and preparation in RapidMiner (one page)
With the used of Rapid Miner; the collected data and information have been
explored and required report has been completed. In this project; the main sources of data information is
the Zomato Restaurants and it contains data information about 45000 restaurants including the reviews
of the customers.
The collected data and information from the Zomato; are further cleaned up by removal
of the useless attributes and missing information; and in order to revalue the data information; some
information has been replaced by new information that covers up the missing information in the data
base. With the use of this analyzed data; the data mining model has been prepared and for this data has
been analyzed based on the pre-defined characteristics. In the organized data information; a couple of
columns have been added; which could utilize online order service and book table service.
Therefore; with the use of these pre-defined attributes; the analysis has been done in order
to design the data mining tool. The analysis done based on these attributes helps BFA to analyze the
working pattern of the Zomato restaurants; and allowing them to add these new attributes for their
customers exploring them opportunities. The following list provided with the different attributes being
used in analysis done:
Name of the restaurant
Type of restaurant
Location of the restaurant
Address of the restaurant
Menu and type of foods
Rate of the foods
Reviews of the customers
Table providing information with respect to data preparation and exploration:
3 of 12
⊘ This is a preview!⊘
Do you want full access?
Subscribe today to unlock all pages.
Trusted by 1+ million students worldwide

MIS772 Predictive Analytics (2019 T2) Individual Assignment A1 / Workshops M1T1-M1T3
4 of 12
4 of 12
Paraphrase This Document
Need a fresh take? Get an instant paraphrase of this document with our AI Paraphraser

MIS772 Predictive Analytics (2019 T2) Individual Assignment A1 / Workshops M1T1-M1T3
Discovering Relationships and Data Transformation in RapidMiner (one page)
In the given analysis; with the use of the Rapid Miner; the data information has
been further analyzed and relationship between the various data information has been analyzed. In order
to identify the relational connection between the data information and its transformation; a correlation
matrix has been prepared. Other operators also used in analysis of data; like filter examples, set roles,
read CSV, correlation matrix and with the above mentioned selected attributes; a correlation matrix is
developed. The below provided table shows the relationships between different data and information:
Based on the label attributes in the case study; a correlation matrix is created showing the
specific new addition of service like booking of table. In this analysis; the recommendations from
different restaurants also being used and correlation matrix designed and provided hereunder:
The below designed chart has been designed for displaying the various attributes that is
arranged according to their inter-related connections:
5 of 12
Discovering Relationships and Data Transformation in RapidMiner (one page)
In the given analysis; with the use of the Rapid Miner; the data information has
been further analyzed and relationship between the various data information has been analyzed. In order
to identify the relational connection between the data information and its transformation; a correlation
matrix has been prepared. Other operators also used in analysis of data; like filter examples, set roles,
read CSV, correlation matrix and with the above mentioned selected attributes; a correlation matrix is
developed. The below provided table shows the relationships between different data and information:
Based on the label attributes in the case study; a correlation matrix is created showing the
specific new addition of service like booking of table. In this analysis; the recommendations from
different restaurants also being used and correlation matrix designed and provided hereunder:
The below designed chart has been designed for displaying the various attributes that is
arranged according to their inter-related connections:
5 of 12

MIS772 Predictive Analytics (2019 T2) Individual Assignment A1 / Workshops M1T1-M1T3
6 of 12
6 of 12
⊘ This is a preview!⊘
Do you want full access?
Subscribe today to unlock all pages.
Trusted by 1+ million students worldwide

MIS772 Predictive Analytics (2019 T2) Individual Assignment A1 / Workshops M1T1-M1T3
Create a Model(s) in RapidMiner (one page limit)
Based on the above made analysis and collected data information from the various
restaurants; the Rapid Miner model has been created. In the given model; specifically two classifications
have been used that is Decision tree and KNN classifications. The below given diagram shows the
creation model based on these two classifications:
In order to create a Rapid Miner model; it is necessary to focus on the read CSV
operator that works basically in reading of the data information provided by Zomato restraurant. In the
next step; the missing value has been replaced by another tool that is normalize operator; and during this
process it is possible that the results of the model might get affected. Then based on the classifications;
KNN classification and decision tree; the label attributes are predicted and its required qualitative
attributes are also selected to make the prediction more perfect. The below given diagram shows the
decision tree used in prediction:
7 of 12
Create a Model(s) in RapidMiner (one page limit)
Based on the above made analysis and collected data information from the various
restaurants; the Rapid Miner model has been created. In the given model; specifically two classifications
have been used that is Decision tree and KNN classifications. The below given diagram shows the
creation model based on these two classifications:
In order to create a Rapid Miner model; it is necessary to focus on the read CSV
operator that works basically in reading of the data information provided by Zomato restraurant. In the
next step; the missing value has been replaced by another tool that is normalize operator; and during this
process it is possible that the results of the model might get affected. Then based on the classifications;
KNN classification and decision tree; the label attributes are predicted and its required qualitative
attributes are also selected to make the prediction more perfect. The below given diagram shows the
decision tree used in prediction:
7 of 12
Paraphrase This Document
Need a fresh take? Get an instant paraphrase of this document with our AI Paraphraser

MIS772 Predictive Analytics (2019 T2) Individual Assignment A1 / Workshops M1T1-M1T3
In designing of the Rapid Miner model; the accuracy parameters also being used
for the selected classifiers that helps in providing accuracy to the prediction process and also improve its
performance. Other parameters and depth are set based on these classifiers and set them as default. In
order to provide an accurate and effective tool to the company; the decision tree has been used here. The
below diagram shows the results of the KNN classifications:
8 of 12
In designing of the Rapid Miner model; the accuracy parameters also being used
for the selected classifiers that helps in providing accuracy to the prediction process and also improve its
performance. Other parameters and depth are set based on these classifiers and set them as default. In
order to provide an accurate and effective tool to the company; the decision tree has been used here. The
below diagram shows the results of the KNN classifications:
8 of 12

MIS772 Predictive Analytics (2019 T2) Individual Assignment A1 / Workshops M1T1-M1T3
Evaluate and Improve the Model(s) in RapidMiner (one page)
Here in this part of the report; the model created on concept of Rapid Miner has been
further evaluated with the use of performance operator. The company will have accurate and better
effective results with the use of this performance operator. This operator has been utilized in the creation
mode; and use in evaluation of the performance of the created model with the help of Kappa values and
accurate information. Additionally; the performance operator also helps in improvisation of overall
performance of the model that can be seen in the below provided illustrations:
With the use of performance operator; the statistical information of the restaurants data
are also assessed in order to improve the performance of the model. So; this performance operator also
provides the performance criteria that are basically related to classification of the task such as accuracy
and Kappa. The main use of this operator is observed only for classification task; where it provides the
input port exporters and it sets deliver the performance vector as a result. However; the use of the
performance vector that is mainly utilized for performance criteria values are analyzed based on the
given data information like Kappa, Accuracy, etc. So; basically it depicts that the results of the
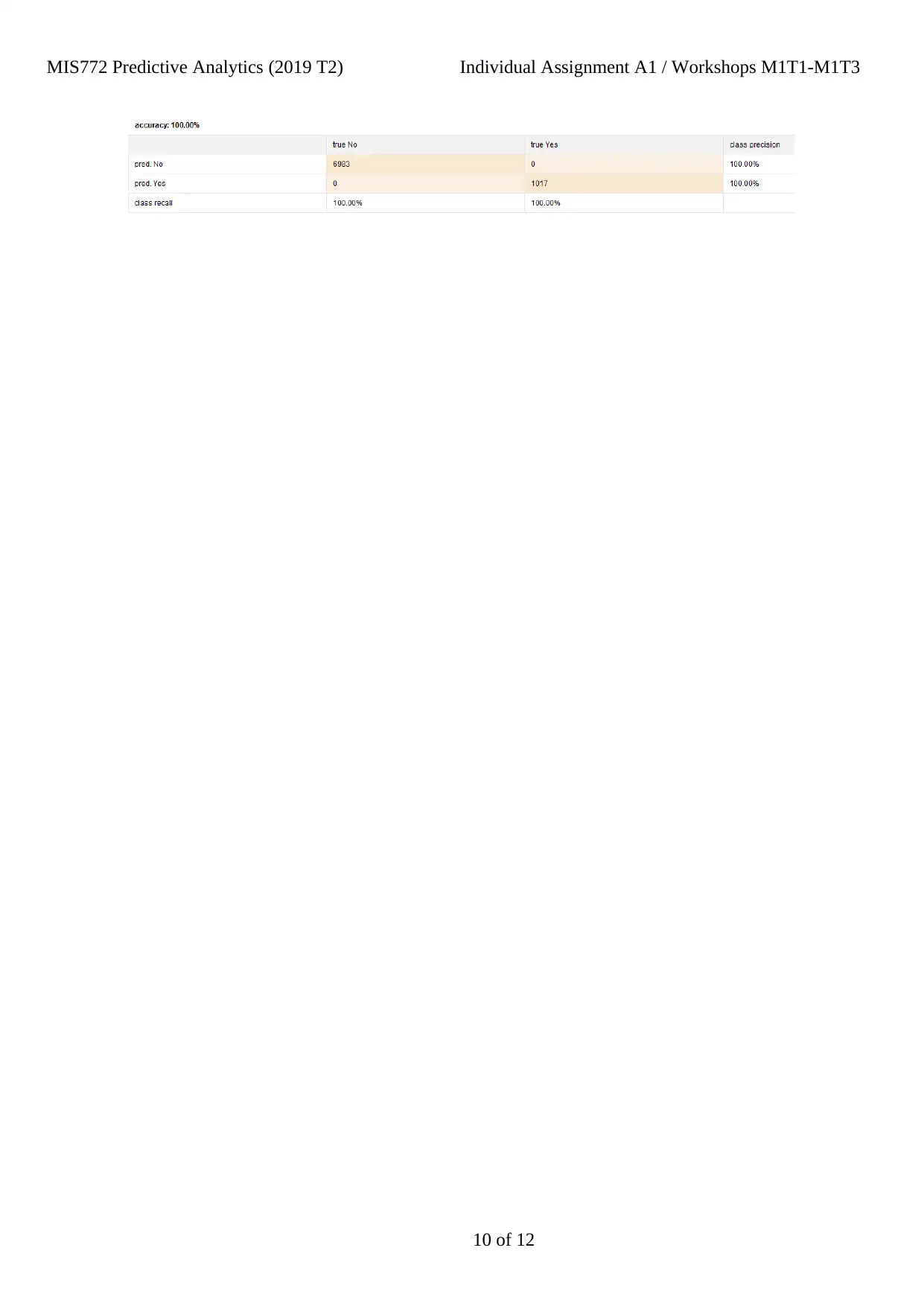
parameters is mainly depend on these data attributes of Kappa and Accuracy.
The accuracy parameter here in this analysis helps in showing the percentage of the
prediction; and use of the Kappa parameter helps in measurement of the simple percentage that
ultimately results into right prediction of the calculation; that can be seen in the below provided
diagram:
9 of 12
Evaluate and Improve the Model(s) in RapidMiner (one page)
Here in this part of the report; the model created on concept of Rapid Miner has been
further evaluated with the use of performance operator. The company will have accurate and better
effective results with the use of this performance operator. This operator has been utilized in the creation
mode; and use in evaluation of the performance of the created model with the help of Kappa values and
accurate information. Additionally; the performance operator also helps in improvisation of overall
performance of the model that can be seen in the below provided illustrations:
With the use of performance operator; the statistical information of the restaurants data
are also assessed in order to improve the performance of the model. So; this performance operator also
provides the performance criteria that are basically related to classification of the task such as accuracy
and Kappa. The main use of this operator is observed only for classification task; where it provides the
input port exporters and it sets deliver the performance vector as a result. However; the use of the
performance vector that is mainly utilized for performance criteria values are analyzed based on the
given data information like Kappa, Accuracy, etc. So; basically it depicts that the results of the
parameters is mainly depend on these data attributes of Kappa and Accuracy.
The accuracy parameter here in this analysis helps in showing the percentage of the
prediction; and use of the Kappa parameter helps in measurement of the simple percentage that
ultimately results into right prediction of the calculation; that can be seen in the below provided
diagram:
9 of 12
⊘ This is a preview!⊘
Do you want full access?
Subscribe today to unlock all pages.
Trusted by 1+ million students worldwide
MIS772 Predictive Analytics (2019 T2) Individual Assignment A1 / Workshops M1T1-M1T3
10 of 12
10 of 12
Paraphrase This Document
Need a fresh take? Get an instant paraphrase of this document with our AI Paraphraser

MIS772 Predictive Analytics (2019 T2) Individual Assignment A1 / Workshops M1T1-M1T3
Deployment in RapidMiner (one page)
The model created based on the concept of Rapid Miner is deployed with the use
of the cross-validation operator. With the use of this operator; the statistical performance of the model
can be determined more accurately. During the process of the cross validation; there has been couple of
sub-processes also being determined namely training processes and testing processes; and these
processes have been used in this operator works as input port and output port and helps in delivering the
output mode accurately in the complete set of examine.
The model that is made uses a few classifiers called the KNN classifier and decision tree
classifier, where the choice tree utilizes four criteria; where the precision criteria is chosen for giving the
model's exact expectation, which is later used for deciding the two administrations, consequently it gives
compelling results for the clients of the BFA organization. This is then connected on the Example sets
with the numerical properties, anyway just on the ostensible characteristics. It conveys the yields like the
choice tree and the model set. So; here in this analysis; the effective outcome of the customers’ services
can be determined with an effective outcome and then it would be applicable to the normal attributes.
So; here in this process; the standard deviation and phenomenal execution estimation that
is part of the designed model made possible with the help of the cross-validation process; that also helps
in senses of the data. The previously mentioned presentation of the eatery information and its estimation
is affected by over fitting. For the arrangement of the information; the Kaggle site is utilized for
categorization of the data information and based on the model has been given the final touch. In the
below diagram; the deployment process of the model is provided:
11 of 12
Deployment in RapidMiner (one page)
The model created based on the concept of Rapid Miner is deployed with the use
of the cross-validation operator. With the use of this operator; the statistical performance of the model
can be determined more accurately. During the process of the cross validation; there has been couple of
sub-processes also being determined namely training processes and testing processes; and these
processes have been used in this operator works as input port and output port and helps in delivering the
output mode accurately in the complete set of examine.
The model that is made uses a few classifiers called the KNN classifier and decision tree
classifier, where the choice tree utilizes four criteria; where the precision criteria is chosen for giving the
model's exact expectation, which is later used for deciding the two administrations, consequently it gives
compelling results for the clients of the BFA organization. This is then connected on the Example sets
with the numerical properties, anyway just on the ostensible characteristics. It conveys the yields like the
choice tree and the model set. So; here in this analysis; the effective outcome of the customers’ services
can be determined with an effective outcome and then it would be applicable to the normal attributes.
So; here in this process; the standard deviation and phenomenal execution estimation that
is part of the designed model made possible with the help of the cross-validation process; that also helps
in senses of the data. The previously mentioned presentation of the eatery information and its estimation
is affected by over fitting. For the arrangement of the information; the Kaggle site is utilized for
categorization of the data information and based on the model has been given the final touch. In the
below diagram; the deployment process of the model is provided:
11 of 12

MIS772 Predictive Analytics (2019 T2) Individual Assignment A1 / Workshops M1T1-M1T3
Further Research and Extensions in RM (one page)
Here in this step of the project; the data is further analyzed based on extension of the
research process and the extensions also being determined for further exploration of the data validation.
Based on the given set of data information of the restaurants; the various missing values; and inadequate
attributes are completed with further research and data validation; and such information are replaced or
further information has been added as the Rapid Miner attributes for further data exploration and
preparation of the selection criteria of the process. Then after; other main characteristics also being
defined and added in the main process that further used in determining and discovering the possible
success of the additional services that is planning by BFA such as online meal ordering and booing of
table in advance. The expected success of these services would be tested and analyzed on the Zomato
restaurants and considering their corresponding review of the customers; medication will be made in the
standard model of the services.
The use of two classifiers KNN classifier and the decision tree helps in more accurate
expected results of the Zomato restaurant’s performance that is planning to adding new two services in
their portfolio. And the success of the classifiers makes it more effective results for development of this
model in this project deployment. The utilization of classifier of decision tree demonstrates the given
information's precision, and it plainly demonstrates that BFA is keen on the two administrations and
gives viable results to the eatery. What's more, this is resolved with the utilization of the performance
operator. For giving the information which shows the BFA is keen on the result of the two
administrations, the KNN order is likewise used, where it demonstrates the profoundly compelling
results for the Zomato restaurants. In the next step; the performance vector determined the additional
attributes value that is determined as 92.70% and 0.062 for the attribute accuracy and for the attribute
kappa value; respectively.
Based on the accuracy of the classification model used in this project, it is used for giving
viable outcomes to the café information. It even gives compelling outcome i.e., service of booking of
table in advance and online food order service are the main area of services on which the company is
focusing on. Such administrations will in general give successful results for any eatery, and it is
recognized by the choice tree model. As per the consequences of the decision tree model, 92.70% of
precision is shown and with an unmistakable choice tree graph containing the two administrations which
are perfect for Zomato restaurants, that is mainly depend on the survey results. So; based on the results
of the performance operator; and cross validation model; the accuracy of the Rapid Miner model is
further improved and expected results become more accurate in the analyzed project.
12 of 12
Further Research and Extensions in RM (one page)
Here in this step of the project; the data is further analyzed based on extension of the
research process and the extensions also being determined for further exploration of the data validation.
Based on the given set of data information of the restaurants; the various missing values; and inadequate
attributes are completed with further research and data validation; and such information are replaced or
further information has been added as the Rapid Miner attributes for further data exploration and
preparation of the selection criteria of the process. Then after; other main characteristics also being
defined and added in the main process that further used in determining and discovering the possible
success of the additional services that is planning by BFA such as online meal ordering and booing of
table in advance. The expected success of these services would be tested and analyzed on the Zomato
restaurants and considering their corresponding review of the customers; medication will be made in the
standard model of the services.
The use of two classifiers KNN classifier and the decision tree helps in more accurate
expected results of the Zomato restaurant’s performance that is planning to adding new two services in
their portfolio. And the success of the classifiers makes it more effective results for development of this
model in this project deployment. The utilization of classifier of decision tree demonstrates the given
information's precision, and it plainly demonstrates that BFA is keen on the two administrations and
gives viable results to the eatery. What's more, this is resolved with the utilization of the performance
operator. For giving the information which shows the BFA is keen on the result of the two
administrations, the KNN order is likewise used, where it demonstrates the profoundly compelling
results for the Zomato restaurants. In the next step; the performance vector determined the additional
attributes value that is determined as 92.70% and 0.062 for the attribute accuracy and for the attribute
kappa value; respectively.
Based on the accuracy of the classification model used in this project, it is used for giving
viable outcomes to the café information. It even gives compelling outcome i.e., service of booking of
table in advance and online food order service are the main area of services on which the company is
focusing on. Such administrations will in general give successful results for any eatery, and it is
recognized by the choice tree model. As per the consequences of the decision tree model, 92.70% of
precision is shown and with an unmistakable choice tree graph containing the two administrations which
are perfect for Zomato restaurants, that is mainly depend on the survey results. So; based on the results
of the performance operator; and cross validation model; the accuracy of the Rapid Miner model is
further improved and expected results become more accurate in the analyzed project.
12 of 12
⊘ This is a preview!⊘
Do you want full access?
Subscribe today to unlock all pages.
Trusted by 1+ million students worldwide
1 out of 12
Related Documents






Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Unlock your academic potential
Copyright © 2020–2026 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.