Project Report: Developing a Cross-Language Plagiarism Detection Tool
VerifiedAdded on 2023/06/05
|16
|2645
|155
Project
AI Summary
This project report details the development of a cross-language plagiarism detection tool designed to identify plagiarism in both English and Hindi texts. The project begins with an introduction and a comprehensive literature review, exploring existing methods and tools like NLTK and Google Translate API for cross-language plagiarism detection. It outlines the project management aspects, including resource allocation and timelines, followed by requirement analysis and software design specifications. The implementation involves using JavaScript for the user interface and Google's Transliterate API to convert text between English and Hindi. The report includes the implementation code and discusses testing, usability, and user design considerations. The project aims to provide an effective solution for identifying plagiarism by comparing the input text with online sources and highlighting similarities. The conclusion summarizes the project's achievements and potential future improvements.

IT Project Management
Student Name: ******
Student ID: ******
Student Name: ******
Student ID: ******
Paraphrase This Document
Need a fresh take? Get an instant paraphrase of this document with our AI Paraphraser

Table of Contents
1 Introduction.......................................................................................................................2
2 Literature Review.............................................................................................................2
3 Project Management.........................................................................................................3
4 Requirement analysis and Specification.........................................................................9
5 Software Design...............................................................................................................10
6 Implementation...............................................................................................................10
7 Testing..............................................................................................................................11
8 Usability and User Design..............................................................................................11
9 Conclusion.......................................................................................................................11
References...............................................................................................................................12
1
1 Introduction.......................................................................................................................2
2 Literature Review.............................................................................................................2
3 Project Management.........................................................................................................3
4 Requirement analysis and Specification.........................................................................9
5 Software Design...............................................................................................................10
6 Implementation...............................................................................................................10
7 Testing..............................................................................................................................11
8 Usability and User Design..............................................................................................11
9 Conclusion.......................................................................................................................11
References...............................................................................................................................12
1

1 Introduction
This application aims to take in an input from a user which would be a text file. The two
languages that can be read from the file should be English and Hindi. The users will be able
to provide the input as an UNICODE file. To achieve this we create a “Hindi representation”
of the sentence in English.The application will then search for similar files on the internet and
provide as with the results that are relevant to the text file that is uploaded. To achieve this
we create a “Hindi representation” of the sentence in English.
2 Literature Review
We went through many articles on the internet’s which were related to the development
of the cross platform plagiarism tool. An article [1] on the stack overflow suggested that we
could develop this application in Python using the NLTK library and GenSem library which
is accomplished by creating the LDA or LSA of the document. We can ultimately use the
Google Search API to search for those words. NTLK [2] is the Natural Language Toolkit for
the natural language processing. This toolkit supports libraries for classification, tokenization,
stemming, tagging, parsing, semantic reasoning etc.
In [5], Chowet. al. mentions about the semantic plagiarism technique. Semantic
plagiarism is where the sentence is reconstructed or some terms are changed into its
corresponding synonyms. Both of these plagiarisms is hardly detected due to the difference in
their fingerprints. Plagiarism detection tools that are available are not capable to detect such
plagiarism cases.
Chow et. al. in [5] proposes a new approach in detecting both cross language and
semantic plagiarism, where , the query document is shortened by utilising fuzzy swarm-based
summarisation approach, the summary will give the most important keywords in the
document. Input summary documents are translated into English using Google Translate
Application Programming Interface (API) before the words are stemmed and the stop words
are removed. Tokenized documents are sent to the Google AJAX Search API to search for
similar documents throughout the World Wide Web. Stanford Parser and Word Net are used
to determine the semantic similarity between the suspected documents with source
documents. Stanford parser assigns each terms in the sentence to their corresponding roles
such as Nouns, Verbs and Adjectives. Each sentence is then represented in a predicate form
and similarity is measured based on those predicates using information from Word Net
2
This application aims to take in an input from a user which would be a text file. The two
languages that can be read from the file should be English and Hindi. The users will be able
to provide the input as an UNICODE file. To achieve this we create a “Hindi representation”
of the sentence in English.The application will then search for similar files on the internet and
provide as with the results that are relevant to the text file that is uploaded. To achieve this
we create a “Hindi representation” of the sentence in English.
2 Literature Review
We went through many articles on the internet’s which were related to the development
of the cross platform plagiarism tool. An article [1] on the stack overflow suggested that we
could develop this application in Python using the NLTK library and GenSem library which
is accomplished by creating the LDA or LSA of the document. We can ultimately use the
Google Search API to search for those words. NTLK [2] is the Natural Language Toolkit for
the natural language processing. This toolkit supports libraries for classification, tokenization,
stemming, tagging, parsing, semantic reasoning etc.
In [5], Chowet. al. mentions about the semantic plagiarism technique. Semantic
plagiarism is where the sentence is reconstructed or some terms are changed into its
corresponding synonyms. Both of these plagiarisms is hardly detected due to the difference in
their fingerprints. Plagiarism detection tools that are available are not capable to detect such
plagiarism cases.
Chow et. al. in [5] proposes a new approach in detecting both cross language and
semantic plagiarism, where , the query document is shortened by utilising fuzzy swarm-based
summarisation approach, the summary will give the most important keywords in the
document. Input summary documents are translated into English using Google Translate
Application Programming Interface (API) before the words are stemmed and the stop words
are removed. Tokenized documents are sent to the Google AJAX Search API to search for
similar documents throughout the World Wide Web. Stanford Parser and Word Net are used
to determine the semantic similarity between the suspected documents with source
documents. Stanford parser assigns each terms in the sentence to their corresponding roles
such as Nouns, Verbs and Adjectives. Each sentence is then represented in a predicate form
and similarity is measured based on those predicates using information from Word Net
2
⊘ This is a preview!⊘
Do you want full access?
Subscribe today to unlock all pages.
Trusted by 1+ million students worldwide

taxonomy. Testing dataset is built up from two sets of input documents which are produced
based on different plagiarism techniques.
Bird et. al. in [3] overs the scope of using the NTLK toolkit for the natural language
processing. We are thinking of using methodology where a Token class is used to represent
of unit a text such as a word, sentence or a piece of document. Kuhn et. al.[4] describes the
use of the application of semantic classification trees for the understanding of natural
language processing. Speech understanding, semantic classification, machine learning,
natural language and decision tree based capabilities for a translator application are covered
up in this paper.
These paragraphs speakabout the speech classification, machine learning based learning
of artificial neural networks, decision trees, tokenization and several other methods.In [6],
Jeremy et. al. talks about different state-of-art methods to detect the plagiarism. Some of the
methods used in the experiment are Cross-Language Character N-Gram (CL-CnG) , Cross-
Language Conceptual Thesaurus-based Similarity (CL-CTS), Cross-Language Alignment-
based Similarity Analysis (CL-ASA), Cross-Language Explicit Semantic Analysis (CL-
ESA), Translation + Monolingual Analysis (T+MA). According to the author, there is a
common behaviour of each method across different language pairs. There is not only a strong
correlation across languages but also across text units that were considered. If a method is
efficient on a particular language pair, it will be similarly efficient on another language pair
as long as enough lexical resources are available for these languages. There was a strong
correlation across types of text when they investigated the behaviour of the methods across
different types of texts on a particular language pair. It was found that a method could be
optimized on a particular collection of text and applied efficiently on another collection.
Finally, it was concluded that methods behave differently in clustering match and
mismatched units, even if they seem similar in performance.
3 Project Management
The Project Activities are shown below(Barrón-Cedeño, Gupta and Rosso, 2013).
Developing a cross-language plagiarism
detection tool
User management
Document management
Translation of input documents
3
based on different plagiarism techniques.
Bird et. al. in [3] overs the scope of using the NTLK toolkit for the natural language
processing. We are thinking of using methodology where a Token class is used to represent
of unit a text such as a word, sentence or a piece of document. Kuhn et. al.[4] describes the
use of the application of semantic classification trees for the understanding of natural
language processing. Speech understanding, semantic classification, machine learning,
natural language and decision tree based capabilities for a translator application are covered
up in this paper.
These paragraphs speakabout the speech classification, machine learning based learning
of artificial neural networks, decision trees, tokenization and several other methods.In [6],
Jeremy et. al. talks about different state-of-art methods to detect the plagiarism. Some of the
methods used in the experiment are Cross-Language Character N-Gram (CL-CnG) , Cross-
Language Conceptual Thesaurus-based Similarity (CL-CTS), Cross-Language Alignment-
based Similarity Analysis (CL-ASA), Cross-Language Explicit Semantic Analysis (CL-
ESA), Translation + Monolingual Analysis (T+MA). According to the author, there is a
common behaviour of each method across different language pairs. There is not only a strong
correlation across languages but also across text units that were considered. If a method is
efficient on a particular language pair, it will be similarly efficient on another language pair
as long as enough lexical resources are available for these languages. There was a strong
correlation across types of text when they investigated the behaviour of the methods across
different types of texts on a particular language pair. It was found that a method could be
optimized on a particular collection of text and applied efficiently on another collection.
Finally, it was concluded that methods behave differently in clustering match and
mismatched units, even if they seem similar in performance.
3 Project Management
The Project Activities are shown below(Barrón-Cedeño, Gupta and Rosso, 2013).
Developing a cross-language plagiarism
detection tool
User management
Document management
Translation of input documents
3
Paraphrase This Document
Need a fresh take? Get an instant paraphrase of this document with our AI Paraphraser

Translate the plagiarized Hindi documents
into English
Improve the effectiveness of the detection
process
Use Google Translate AP
Removing Stop Words
Before passing the translated documents for
comparison through the Internet
Remove the stop words in the translated text
Stemming Words
Remove the affixes
Generate root word
Pattern matching
Text Stemmer and Porter Stemmer
Use of Porter Stemming algorithm
Removing the commoner morphological and
in flexional endings from words in English
Identifying Similar Documents
Collection of documents that located around
the World Wide Web
Enables small and characteristic fragments
translation
Query documents or texts are inserted
Use of Google AJAX Search API
Comparison of Similar Pattern
Detect plagiarism
Represent the sentence uniquely.
Summary of the Result
Gathering the result
Plagiarism detection is displayed
4
into English
Improve the effectiveness of the detection
process
Use Google Translate AP
Removing Stop Words
Before passing the translated documents for
comparison through the Internet
Remove the stop words in the translated text
Stemming Words
Remove the affixes
Generate root word
Pattern matching
Text Stemmer and Porter Stemmer
Use of Porter Stemming algorithm
Removing the commoner morphological and
in flexional endings from words in English
Identifying Similar Documents
Collection of documents that located around
the World Wide Web
Enables small and characteristic fragments
translation
Query documents or texts are inserted
Use of Google AJAX Search API
Comparison of Similar Pattern
Detect plagiarism
Represent the sentence uniquely.
Summary of the Result
Gathering the result
Plagiarism detection is displayed
4
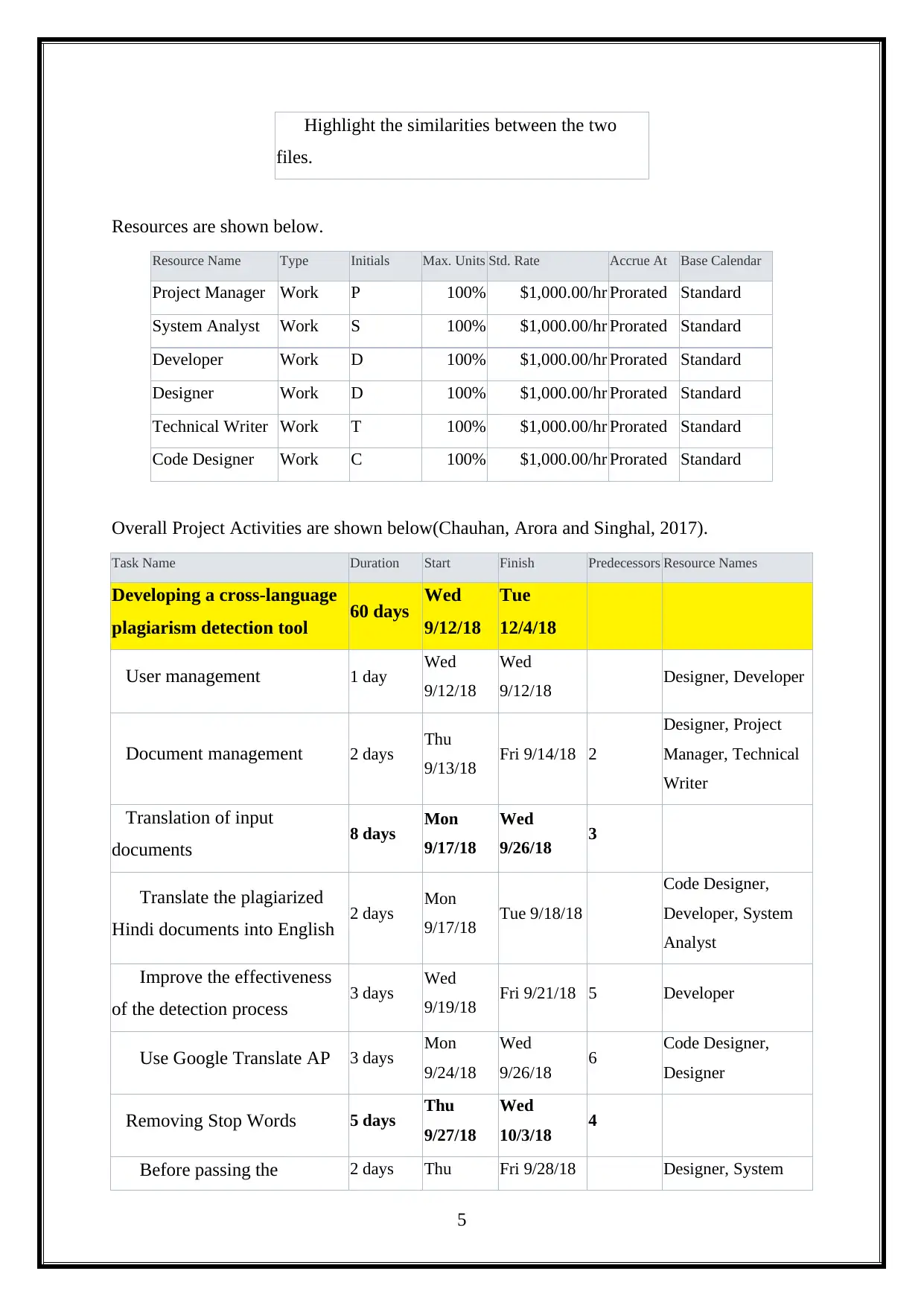
Highlight the similarities between the two
files.
Resources are shown below.
Resource Name Type Initials Max. Units Std. Rate Accrue At Base Calendar
Project Manager Work P 100% $1,000.00/hr Prorated Standard
System Analyst Work S 100% $1,000.00/hr Prorated Standard
Developer Work D 100% $1,000.00/hr Prorated Standard
Designer Work D 100% $1,000.00/hr Prorated Standard
Technical Writer Work T 100% $1,000.00/hr Prorated Standard
Code Designer Work C 100% $1,000.00/hr Prorated Standard
Overall Project Activities are shown below(Chauhan, Arora and Singhal, 2017).
Task Name Duration Start Finish Predecessors Resource Names
Developing a cross-language
plagiarism detection tool 60 days Wed
9/12/18
Tue
12/4/18
User management 1 day Wed
9/12/18
Wed
9/12/18 Designer, Developer
Document management 2 days Thu
9/13/18 Fri 9/14/18 2
Designer, Project
Manager, Technical
Writer
Translation of input
documents 8 days Mon
9/17/18
Wed
9/26/18 3
Translate the plagiarized
Hindi documents into English 2 days Mon
9/17/18 Tue 9/18/18
Code Designer,
Developer, System
Analyst
Improve the effectiveness
of the detection process 3 days Wed
9/19/18 Fri 9/21/18 5 Developer
Use Google Translate AP 3 days Mon
9/24/18
Wed
9/26/18 6 Code Designer,
Designer
Removing Stop Words 5 days Thu
9/27/18
Wed
10/3/18 4
Before passing the 2 days Thu Fri 9/28/18 Designer, System
5
files.
Resources are shown below.
Resource Name Type Initials Max. Units Std. Rate Accrue At Base Calendar
Project Manager Work P 100% $1,000.00/hr Prorated Standard
System Analyst Work S 100% $1,000.00/hr Prorated Standard
Developer Work D 100% $1,000.00/hr Prorated Standard
Designer Work D 100% $1,000.00/hr Prorated Standard
Technical Writer Work T 100% $1,000.00/hr Prorated Standard
Code Designer Work C 100% $1,000.00/hr Prorated Standard
Overall Project Activities are shown below(Chauhan, Arora and Singhal, 2017).
Task Name Duration Start Finish Predecessors Resource Names
Developing a cross-language
plagiarism detection tool 60 days Wed
9/12/18
Tue
12/4/18
User management 1 day Wed
9/12/18
Wed
9/12/18 Designer, Developer
Document management 2 days Thu
9/13/18 Fri 9/14/18 2
Designer, Project
Manager, Technical
Writer
Translation of input
documents 8 days Mon
9/17/18
Wed
9/26/18 3
Translate the plagiarized
Hindi documents into English 2 days Mon
9/17/18 Tue 9/18/18
Code Designer,
Developer, System
Analyst
Improve the effectiveness
of the detection process 3 days Wed
9/19/18 Fri 9/21/18 5 Developer
Use Google Translate AP 3 days Mon
9/24/18
Wed
9/26/18 6 Code Designer,
Designer
Removing Stop Words 5 days Thu
9/27/18
Wed
10/3/18 4
Before passing the 2 days Thu Fri 9/28/18 Designer, System
5
⊘ This is a preview!⊘
Do you want full access?
Subscribe today to unlock all pages.
Trusted by 1+ million students worldwide
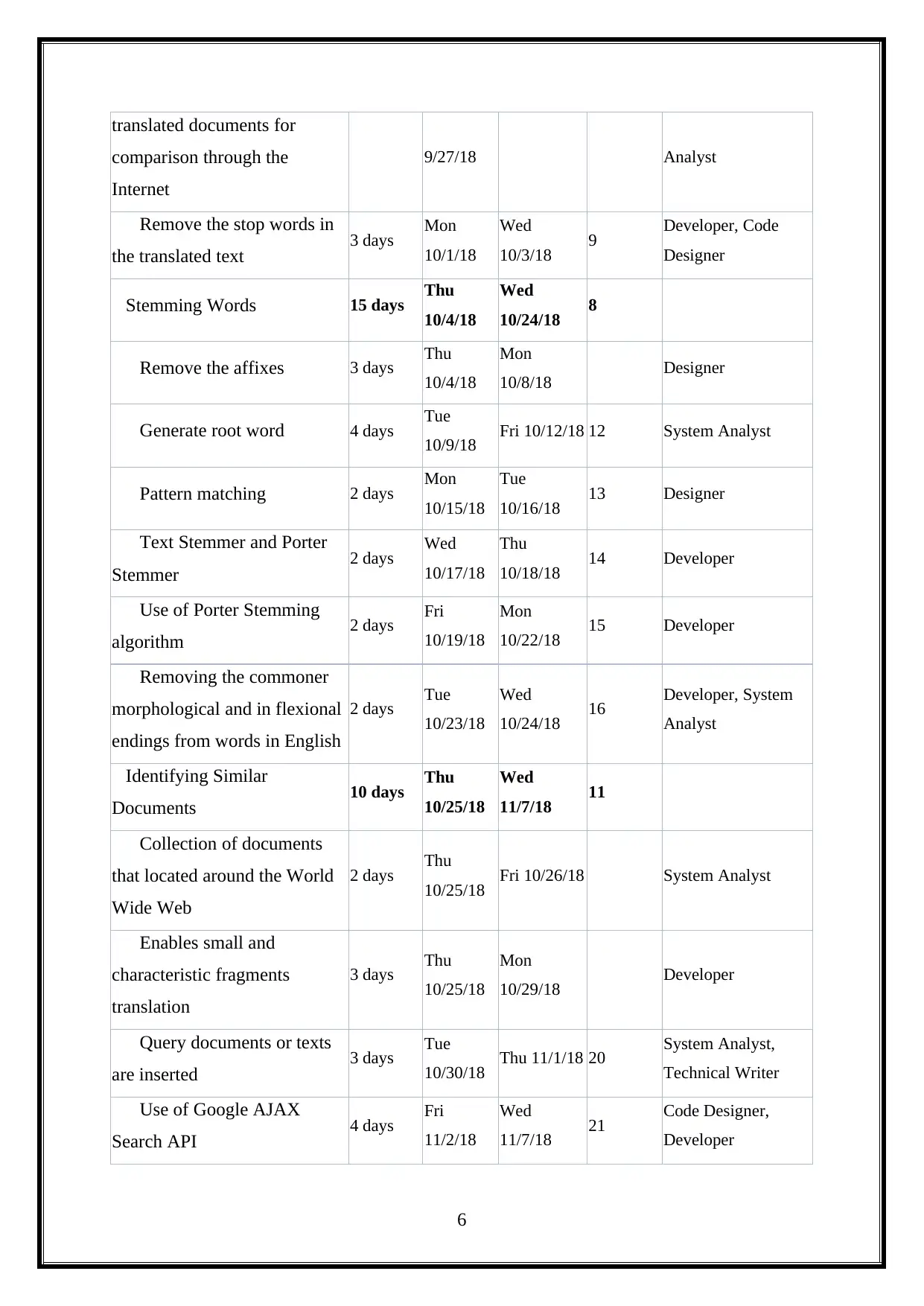
translated documents for
comparison through the
Internet
9/27/18 Analyst
Remove the stop words in
the translated text 3 days Mon
10/1/18
Wed
10/3/18 9 Developer, Code
Designer
Stemming Words 15 days Thu
10/4/18
Wed
10/24/18 8
Remove the affixes 3 days Thu
10/4/18
Mon
10/8/18 Designer
Generate root word 4 days Tue
10/9/18 Fri 10/12/18 12 System Analyst
Pattern matching 2 days Mon
10/15/18
Tue
10/16/18 13 Designer
Text Stemmer and Porter
Stemmer 2 days Wed
10/17/18
Thu
10/18/18 14 Developer
Use of Porter Stemming
algorithm 2 days Fri
10/19/18
Mon
10/22/18 15 Developer
Removing the commoner
morphological and in flexional
endings from words in English
2 days Tue
10/23/18
Wed
10/24/18 16 Developer, System
Analyst
Identifying Similar
Documents 10 days Thu
10/25/18
Wed
11/7/18 11
Collection of documents
that located around the World
Wide Web
2 days Thu
10/25/18 Fri 10/26/18 System Analyst
Enables small and
characteristic fragments
translation
3 days Thu
10/25/18
Mon
10/29/18 Developer
Query documents or texts
are inserted 3 days Tue
10/30/18 Thu 11/1/18 20 System Analyst,
Technical Writer
Use of Google AJAX
Search API 4 days Fri
11/2/18
Wed
11/7/18 21 Code Designer,
Developer
6
comparison through the
Internet
9/27/18 Analyst
Remove the stop words in
the translated text 3 days Mon
10/1/18
Wed
10/3/18 9 Developer, Code
Designer
Stemming Words 15 days Thu
10/4/18
Wed
10/24/18 8
Remove the affixes 3 days Thu
10/4/18
Mon
10/8/18 Designer
Generate root word 4 days Tue
10/9/18 Fri 10/12/18 12 System Analyst
Pattern matching 2 days Mon
10/15/18
Tue
10/16/18 13 Designer
Text Stemmer and Porter
Stemmer 2 days Wed
10/17/18
Thu
10/18/18 14 Developer
Use of Porter Stemming
algorithm 2 days Fri
10/19/18
Mon
10/22/18 15 Developer
Removing the commoner
morphological and in flexional
endings from words in English
2 days Tue
10/23/18
Wed
10/24/18 16 Developer, System
Analyst
Identifying Similar
Documents 10 days Thu
10/25/18
Wed
11/7/18 11
Collection of documents
that located around the World
Wide Web
2 days Thu
10/25/18 Fri 10/26/18 System Analyst
Enables small and
characteristic fragments
translation
3 days Thu
10/25/18
Mon
10/29/18 Developer
Query documents or texts
are inserted 3 days Tue
10/30/18 Thu 11/1/18 20 System Analyst,
Technical Writer
Use of Google AJAX
Search API 4 days Fri
11/2/18
Wed
11/7/18 21 Code Designer,
Developer
6
Paraphrase This Document
Need a fresh take? Get an instant paraphrase of this document with our AI Paraphraser
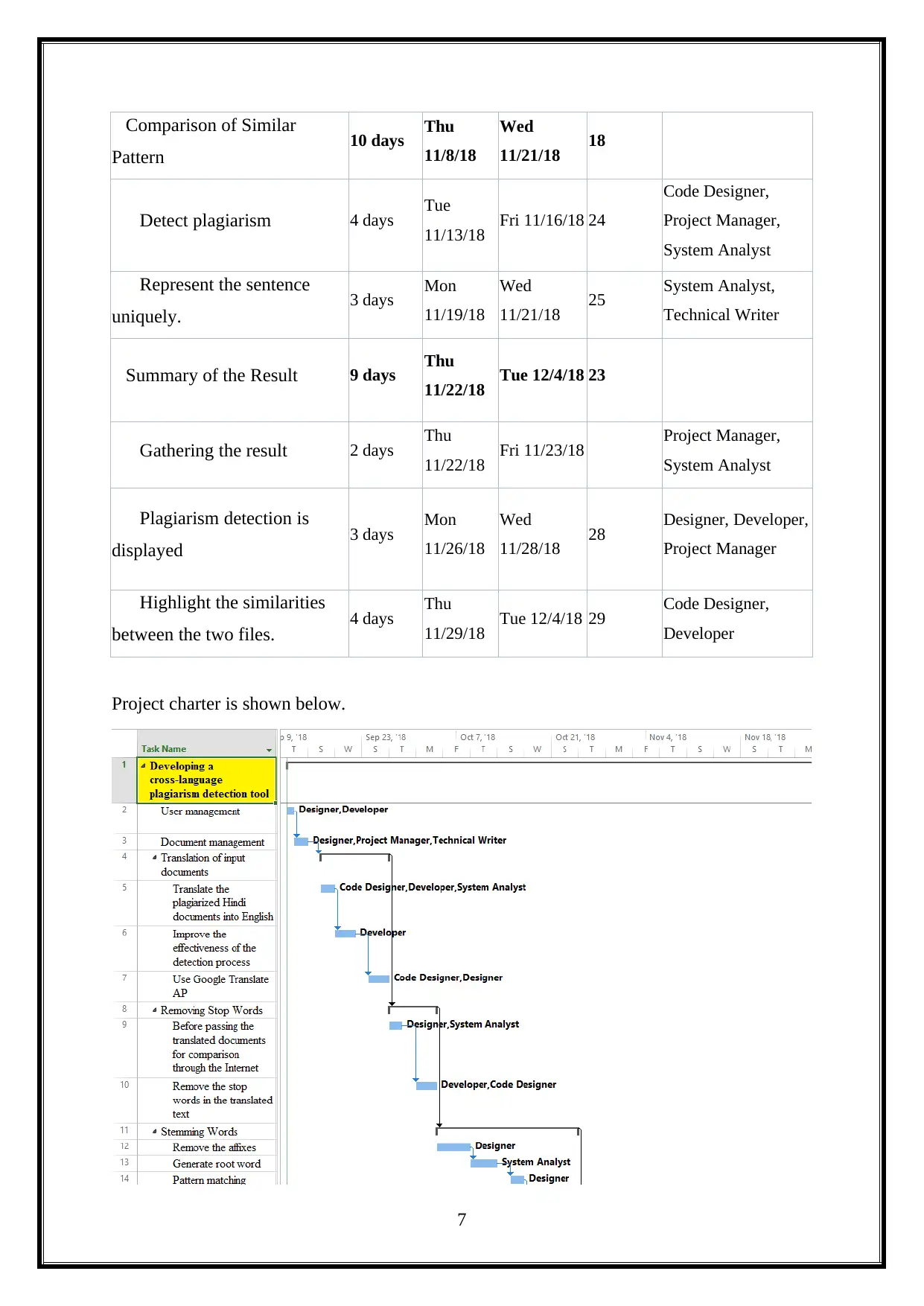
Comparison of Similar
Pattern 10 days Thu
11/8/18
Wed
11/21/18 18
Detect plagiarism 4 days Tue
11/13/18 Fri 11/16/18 24
Code Designer,
Project Manager,
System Analyst
Represent the sentence
uniquely. 3 days Mon
11/19/18
Wed
11/21/18 25 System Analyst,
Technical Writer
Summary of the Result 9 days Thu
11/22/18 Tue 12/4/18 23
Gathering the result 2 days Thu
11/22/18 Fri 11/23/18 Project Manager,
System Analyst
Plagiarism detection is
displayed 3 days Mon
11/26/18
Wed
11/28/18 28 Designer, Developer,
Project Manager
Highlight the similarities
between the two files. 4 days Thu
11/29/18 Tue 12/4/18 29 Code Designer,
Developer
Project charter is shown below.
7
Pattern 10 days Thu
11/8/18
Wed
11/21/18 18
Detect plagiarism 4 days Tue
11/13/18 Fri 11/16/18 24
Code Designer,
Project Manager,
System Analyst
Represent the sentence
uniquely. 3 days Mon
11/19/18
Wed
11/21/18 25 System Analyst,
Technical Writer
Summary of the Result 9 days Thu
11/22/18 Tue 12/4/18 23
Gathering the result 2 days Thu
11/22/18 Fri 11/23/18 Project Manager,
System Analyst
Plagiarism detection is
displayed 3 days Mon
11/26/18
Wed
11/28/18 28 Designer, Developer,
Project Manager
Highlight the similarities
between the two files. 4 days Thu
11/29/18 Tue 12/4/18 29 Code Designer,
Developer
Project charter is shown below.
7
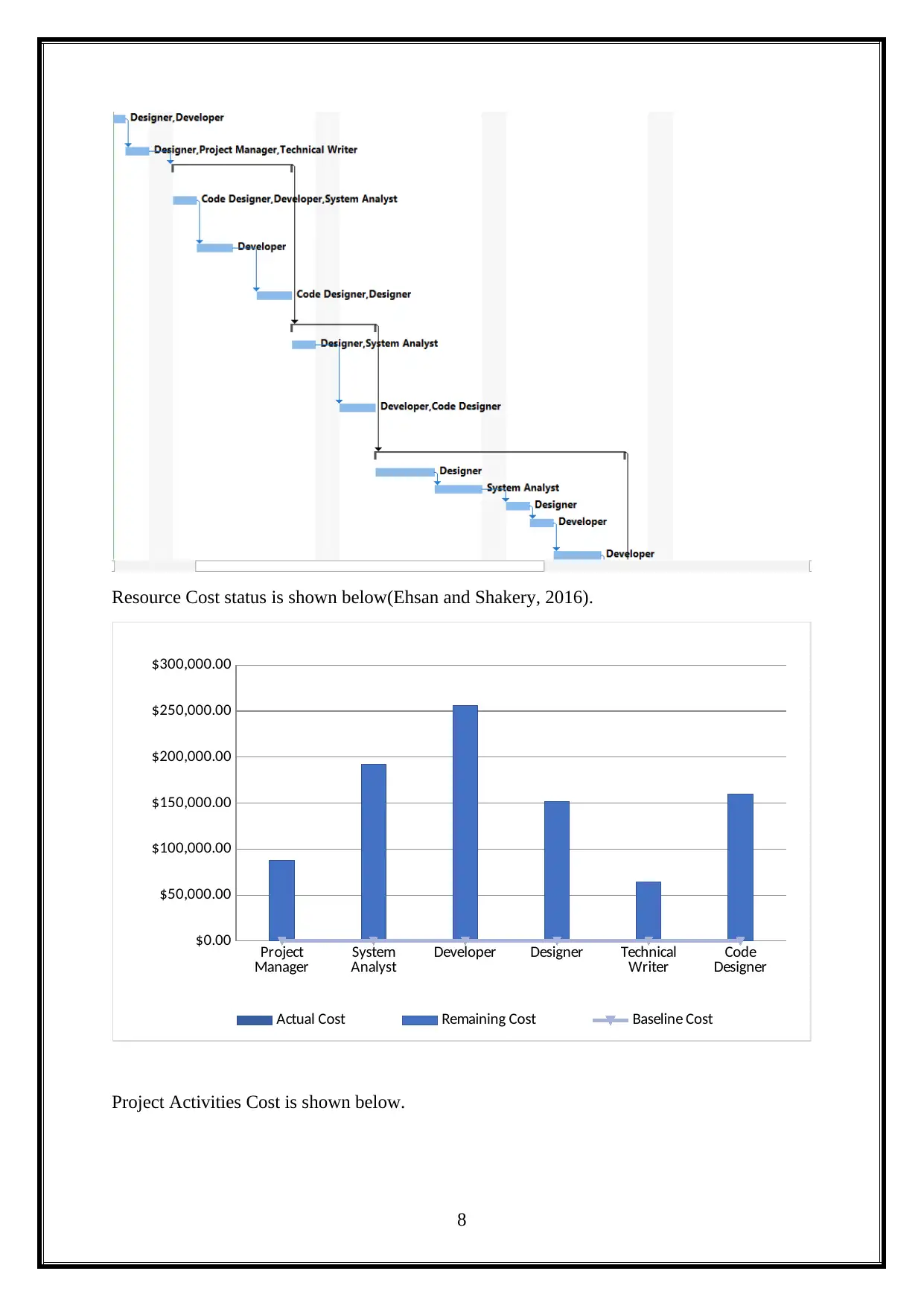
Resource Cost status is shown below(Ehsan and Shakery, 2016).
Project
Manager System
Analyst Developer Designer Technical
Writer Code
Designer
$0.00
$50,000.00
$100,000.00
$150,000.00
$200,000.00
$250,000.00
$300,000.00
Actual Cost Remaining Cost Baseline Cost
Project Activities Cost is shown below.
8
Project
Manager System
Analyst Developer Designer Technical
Writer Code
Designer
$0.00
$50,000.00
$100,000.00
$150,000.00
$200,000.00
$250,000.00
$300,000.00
Actual Cost Remaining Cost Baseline Cost
Project Activities Cost is shown below.
8
⊘ This is a preview!⊘
Do you want full access?
Subscribe today to unlock all pages.
Trusted by 1+ million students worldwide
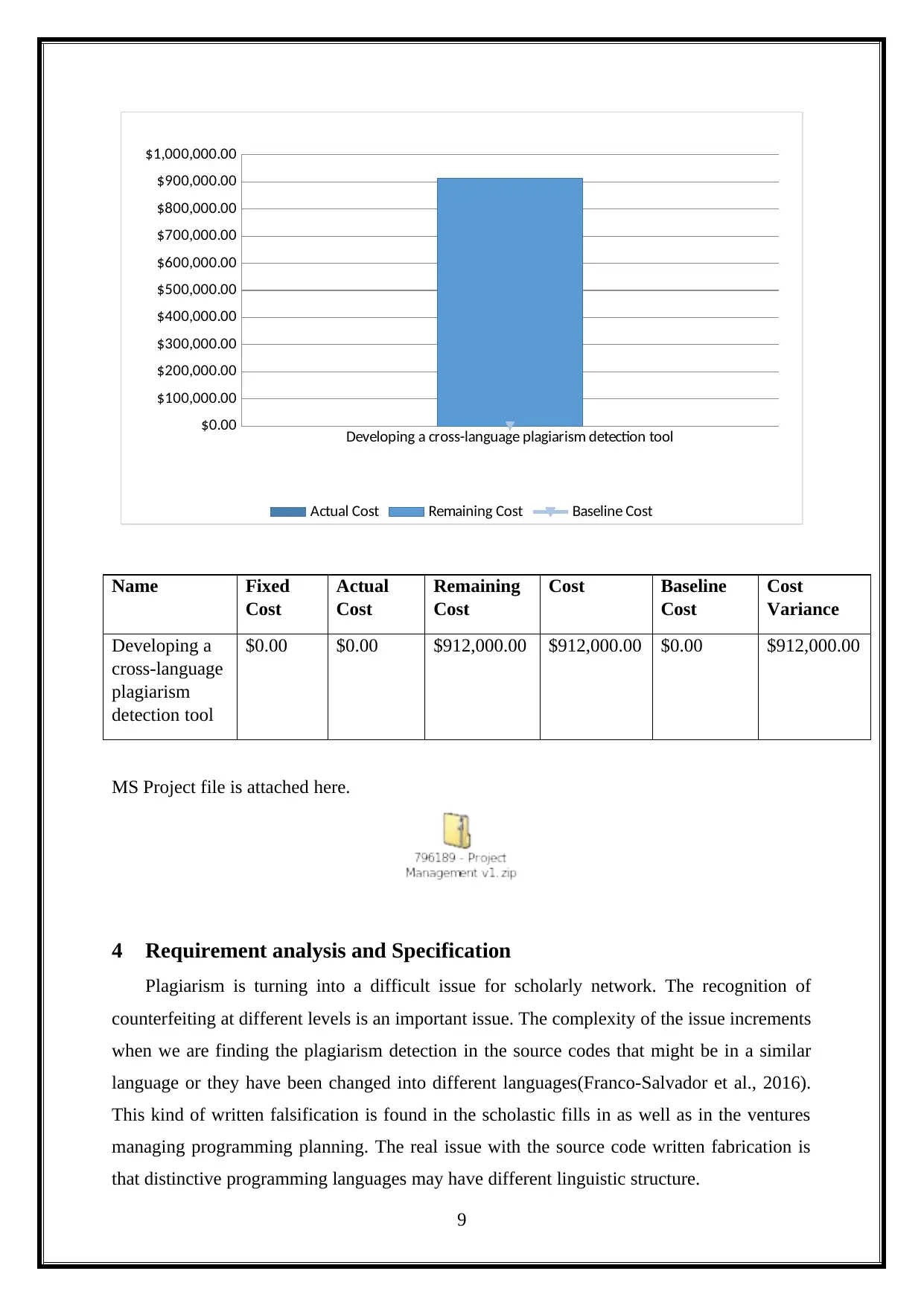
Developing a cross-language plagiarism detection tool
$0.00
$100,000.00
$200,000.00
$300,000.00
$400,000.00
$500,000.00
$600,000.00
$700,000.00
$800,000.00
$900,000.00
$1,000,000.00
Actual Cost Remaining Cost Baseline Cost
Name Fixed
Cost
Actual
Cost
Remaining
Cost
Cost Baseline
Cost
Cost
Variance
Developing a
cross-language
plagiarism
detection tool
$0.00 $0.00 $912,000.00 $912,000.00 $0.00 $912,000.00
MS Project file is attached here.
4 Requirement analysis and Specification
Plagiarism is turning into a difficult issue for scholarly network. The recognition of
counterfeiting at different levels is an important issue. The complexity of the issue increments
when we are finding the plagiarism detection in the source codes that might be in a similar
language or they have been changed into different languages(Franco-Salvador et al., 2016).
This kind of written falsification is found in the scholastic fills in as well as in the ventures
managing programming planning. The real issue with the source code written fabrication is
that distinctive programming languages may have different linguistic structure.
9
$0.00
$100,000.00
$200,000.00
$300,000.00
$400,000.00
$500,000.00
$600,000.00
$700,000.00
$800,000.00
$900,000.00
$1,000,000.00
Actual Cost Remaining Cost Baseline Cost
Name Fixed
Cost
Actual
Cost
Remaining
Cost
Cost Baseline
Cost
Cost
Variance
Developing a
cross-language
plagiarism
detection tool
$0.00 $0.00 $912,000.00 $912,000.00 $0.00 $912,000.00
MS Project file is attached here.
4 Requirement analysis and Specification
Plagiarism is turning into a difficult issue for scholarly network. The recognition of
counterfeiting at different levels is an important issue. The complexity of the issue increments
when we are finding the plagiarism detection in the source codes that might be in a similar
language or they have been changed into different languages(Franco-Salvador et al., 2016).
This kind of written falsification is found in the scholastic fills in as well as in the ventures
managing programming planning. The real issue with the source code written fabrication is
that distinctive programming languages may have different linguistic structure.
9
Paraphrase This Document
Need a fresh take? Get an instant paraphrase of this document with our AI Paraphraser

In view of language homogeneity or heterogeneity of the writings being looked at,
plagiarism detection discovery can be characterized into monolingual and cross-lingual. The
cross-language written misrepresentation recognition process is like the outside plagiarism
detection identification assignment with a few alterations in heuristic recovery and itemized
investigation stages(Gelbukh, 2009). In cross-language heuristic recovery, this stage expects
to recover the accumulation of source hopeful archives from the informational index.
Deciphering the info archive from the inquiry language to the source language might be
required in this stage. The cross-language point by point examination level estimates the
cross-language likeness between segments of the suspicious record and segments of the
hopeful reports which recovered in the past stage(Kashkur, Parshutin and Borisov, 2010).
Language used : Java script.
5 Software Design
Software Design for Cross language plagiarism detection tool is illustrated
below(Kasprowicz and Wada, 2014).
6 Implementation
Implementation code is attached here.(Lee, 2012)
<head>
<meta http-equiv="Content-Type" content="text/html; charset=utf-8"/>
<script type="text/javascript" src="https://www.google.com/jsapi">
</script>
10
plagiarism detection discovery can be characterized into monolingual and cross-lingual. The
cross-language written misrepresentation recognition process is like the outside plagiarism
detection identification assignment with a few alterations in heuristic recovery and itemized
investigation stages(Gelbukh, 2009). In cross-language heuristic recovery, this stage expects
to recover the accumulation of source hopeful archives from the informational index.
Deciphering the info archive from the inquiry language to the source language might be
required in this stage. The cross-language point by point examination level estimates the
cross-language likeness between segments of the suspicious record and segments of the
hopeful reports which recovered in the past stage(Kashkur, Parshutin and Borisov, 2010).
Language used : Java script.
5 Software Design
Software Design for Cross language plagiarism detection tool is illustrated
below(Kasprowicz and Wada, 2014).
6 Implementation
Implementation code is attached here.(Lee, 2012)
<head>
<meta http-equiv="Content-Type" content="text/html; charset=utf-8"/>
<script type="text/javascript" src="https://www.google.com/jsapi">
</script>
10

<script type="text/javascript">
// Load the Google Transliterate API
google.load("elements", "1", {
packages: "transliteration"
});
function onLoad() {
var options = {
sourceLanguage:
google.elements.transliteration.LanguageCode.ENGLISH,
destinationLanguage:
[google.elements.transliteration.LanguageCode.HINDI],
shortcutKey: 'ctrl+g',
transliterationEnabled: true
};
// Create an instance on TransliterationControl with the required
// options.
var control =
new google.elements.transliteration.TransliterationControl(options);
// Enable transliteration in the textbox with id
// 'transliterateTextarea'.
control.makeTransliteratable(['transliterateTextarea']);
}
google.setOnLoadCallback(onLoad);
</script>
</head>
<body>
11
// Load the Google Transliterate API
google.load("elements", "1", {
packages: "transliteration"
});
function onLoad() {
var options = {
sourceLanguage:
google.elements.transliteration.LanguageCode.ENGLISH,
destinationLanguage:
[google.elements.transliteration.LanguageCode.HINDI],
shortcutKey: 'ctrl+g',
transliterationEnabled: true
};
// Create an instance on TransliterationControl with the required
// options.
var control =
new google.elements.transliteration.TransliterationControl(options);
// Enable transliteration in the textbox with id
// 'transliterateTextarea'.
control.makeTransliteratable(['transliterateTextarea']);
}
google.setOnLoadCallback(onLoad);
</script>
</head>
<body>
11
⊘ This is a preview!⊘
Do you want full access?
Subscribe today to unlock all pages.
Trusted by 1+ million students worldwide
1 out of 16
Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Unlock your academic potential
Copyright © 2020–2026 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.