Distributed Systems Project: Retail Company Globalization Strategy
VerifiedAdded on 2022/08/17
|43
|9700
|236
Project
AI Summary
This project addresses the design and analysis of a distributed system for a retail enterprise undergoing global expansion. The assignment requires the student to model a distributed system, considering architectural models like client-server and peer-to-peer, and addressing requirements such as employee access to catalogs, shared files, and corporate resources. The project also involves identifying hardware components like printers and routers. The second part of the assignment focuses on updating the initial design to incorporate additional requirements, including support for autonomous agents, distributed system states, and a centralized service for user management. The project also emphasizes the importance of system robustness, fault tolerance, and the implementation of database, email, and file-sharing servers. The student is expected to identify potential system slowdowns and implement solutions such as hardware and software backups. The assignment requires the use of diagramming software to visualize the distributed system, and the student is expected to cite scholarly resources to support their analysis and design choices.

Running head: DISTRIBUTED SYSTEMS
DISTRIBUTED SYSTEMS
Name of the Student
Name of the University
Author Note
DISTRIBUTED SYSTEMS
Name of the Student
Name of the University
Author Note
Paraphrase This Document
Need a fresh take? Get an instant paraphrase of this document with our AI Paraphraser

1DISTRIBUTED SYSTEMS
Discussions
Case Scenario
There is a retail enterprise whose task is to manufacture and distribute three lines of
clothing to 30 stores in the United States and this enterprise is launching a globalization
strategy. Their plan of strategy is maximizing their online presence and expanding the
distribution channels of the company.
The total number of employees in the company includes 3000. The headquarters of the
company is in South Carolina and their primary manufacturing units are in Maine and Seattle.
The wish of the company is to open three international stores in New Zealand, England and
Spain. The infrastructure of computing of the company includes roughly 500 computers, 200
terminals those are connected to servers in South Carolina, Maine and Seattle and 300
printers.
Answer 1
A distributed system is a system whose components are situated on various computers those
are networked and that coordinates and communicates their activities by transmitting
messages to each other (Abadi et al.,2016). The components interact with each other to
accomplish common objectives.
There are various types of models of distributed systems. The models are as follows:
Architectural models
Interaction models
Fault model
Discussions
Case Scenario
There is a retail enterprise whose task is to manufacture and distribute three lines of
clothing to 30 stores in the United States and this enterprise is launching a globalization
strategy. Their plan of strategy is maximizing their online presence and expanding the
distribution channels of the company.
The total number of employees in the company includes 3000. The headquarters of the
company is in South Carolina and their primary manufacturing units are in Maine and Seattle.
The wish of the company is to open three international stores in New Zealand, England and
Spain. The infrastructure of computing of the company includes roughly 500 computers, 200
terminals those are connected to servers in South Carolina, Maine and Seattle and 300
printers.
Answer 1
A distributed system is a system whose components are situated on various computers those
are networked and that coordinates and communicates their activities by transmitting
messages to each other (Abadi et al.,2016). The components interact with each other to
accomplish common objectives.
There are various types of models of distributed systems. The models are as follows:
Architectural models
Interaction models
Fault model

2DISTRIBUTED SYSTEMS
Architectural models: the model of architecture refers to the responsibilities those are
distributed between the components of the system and the way these components are placed
(Van Steen & Tanenbaum, 2017).
There are two types of architectural models. These include client-server model and the
peer-to-peer model.
Client-server model: the system is structured as a sequence of procedures known as
servers that provide services to the various servers known as clients.
The model of client-server is based on a simple requested that is deployed with the
primitives of send/receive or utilising procedure calls those are remote.
The client first sends a message request to the server in order to ask for some of the
services that the server can provide.
The server then does the work and then returns an output or a code that is erroneous if the
work cannot be executed.
Peer-to-peer: All the procedures play the same role
The procedures interact without a specific distinction between the servers and the clients.
The communication pattern depends on the specific application
A large number of objects of data are shared; any computer holds a very small part of the
database of application.
Interaction models:
The models of interaction are for time handling that is for the execution of
procedures, delivery of messages, drifts of clocks and many more. There are two types of
models of interaction (Aldin et al.,2019). These include Synchronous and asynchronous
distributed systems.
Architectural models: the model of architecture refers to the responsibilities those are
distributed between the components of the system and the way these components are placed
(Van Steen & Tanenbaum, 2017).
There are two types of architectural models. These include client-server model and the
peer-to-peer model.
Client-server model: the system is structured as a sequence of procedures known as
servers that provide services to the various servers known as clients.
The model of client-server is based on a simple requested that is deployed with the
primitives of send/receive or utilising procedure calls those are remote.
The client first sends a message request to the server in order to ask for some of the
services that the server can provide.
The server then does the work and then returns an output or a code that is erroneous if the
work cannot be executed.
Peer-to-peer: All the procedures play the same role
The procedures interact without a specific distinction between the servers and the clients.
The communication pattern depends on the specific application
A large number of objects of data are shared; any computer holds a very small part of the
database of application.
Interaction models:
The models of interaction are for time handling that is for the execution of
procedures, delivery of messages, drifts of clocks and many more. There are two types of
models of interaction (Aldin et al.,2019). These include Synchronous and asynchronous
distributed systems.
⊘ This is a preview!⊘
Do you want full access?
Subscribe today to unlock all pages.
Trusted by 1+ million students worldwide

3DISTRIBUTED SYSTEMS
Synchronous distributed systems: The features of the synchronous distributed systems are
as follows:
The upper and the lower bounds on the procedures of execution time can be easily set
The messages transmitted are received within a known time that is bounded.
The rates of drift between the local clocks have a known bound.
Asynchronous distributed Systems: there are different distributed systems those are
asynchronous. They don’t have bound on procedure time of execution, no bound on delays of
transmission of messages and no bound on rates of drift between the local clocks.
Fault models: in the fault models, failure can occur both in the channels of communication
and in the procedures. The reason can be faults of both hardwares and softwares. The faults
model are required to create systems with a behaviour that is predictive in case of some faults
(Rouland, Hamid & Jaskolka, 2018). Such a type of system will according to the predictions
as long the faults those are real behave as defined by the model of fault.
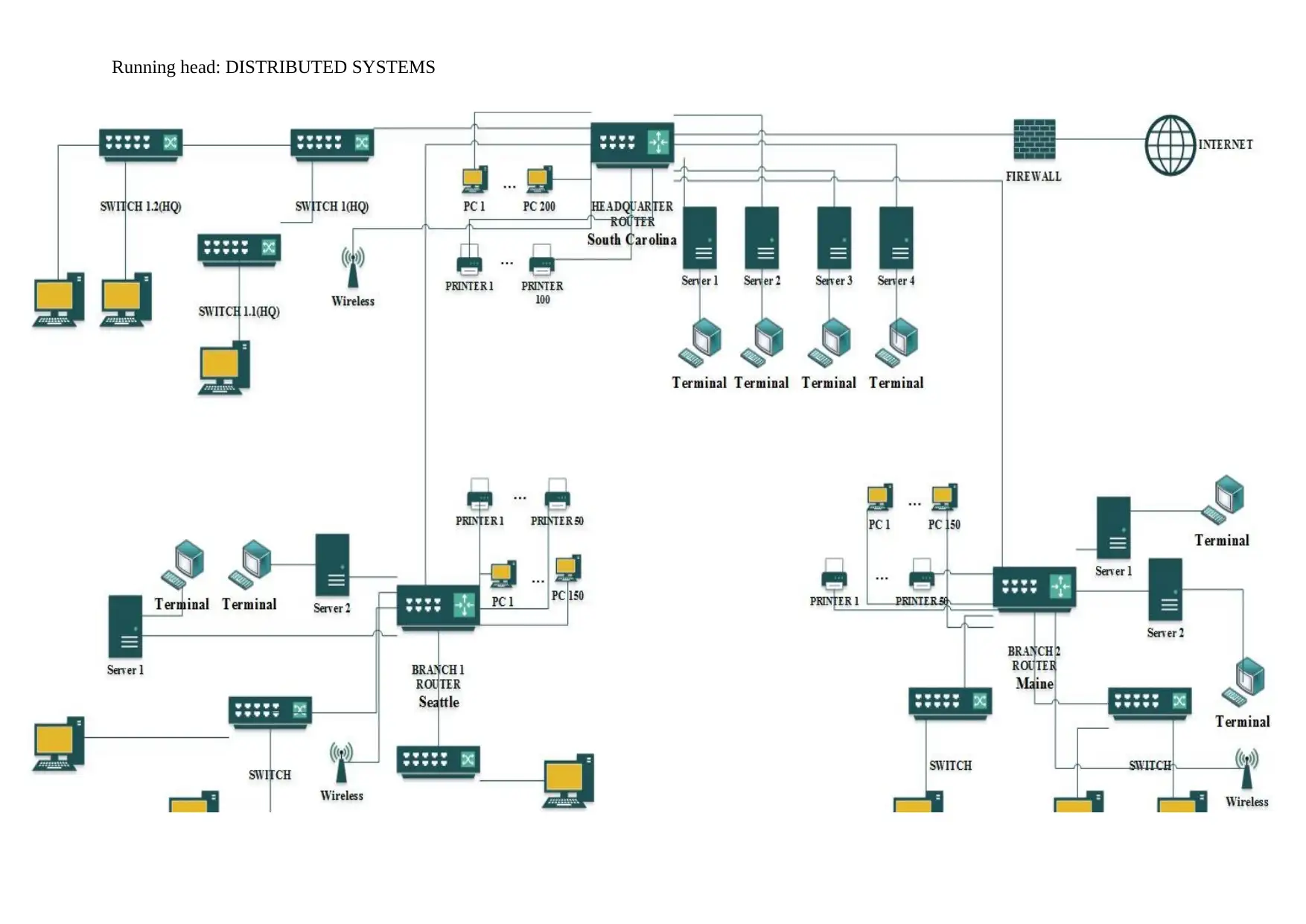
The model of the distributed systems that will be identified in this diagram include
Everyone in the company’s headquarters should have admittance to the catalog of
clothing line, files those are shared and the assets of the company.
The hardwares of the company such as the printers, scanners and the routers will be
recognised
All the employees of the company will be able to access the webpage that is corporate
and the corporate intranet for shipping, sales, processing and the tasks of internal
administrative.
The company has 3000 employees, the headquarters of the company is in South Carolina, and
the units of manufacturing are in Seattle and Maine. The company wants to open three
international stores in England, Spain and New Zealand. The computing infrastructure of the
Synchronous distributed systems: The features of the synchronous distributed systems are
as follows:
The upper and the lower bounds on the procedures of execution time can be easily set
The messages transmitted are received within a known time that is bounded.
The rates of drift between the local clocks have a known bound.
Asynchronous distributed Systems: there are different distributed systems those are
asynchronous. They don’t have bound on procedure time of execution, no bound on delays of
transmission of messages and no bound on rates of drift between the local clocks.
Fault models: in the fault models, failure can occur both in the channels of communication
and in the procedures. The reason can be faults of both hardwares and softwares. The faults
model are required to create systems with a behaviour that is predictive in case of some faults
(Rouland, Hamid & Jaskolka, 2018). Such a type of system will according to the predictions
as long the faults those are real behave as defined by the model of fault.
The model of the distributed systems that will be identified in this diagram include
Everyone in the company’s headquarters should have admittance to the catalog of
clothing line, files those are shared and the assets of the company.
The hardwares of the company such as the printers, scanners and the routers will be
recognised
All the employees of the company will be able to access the webpage that is corporate
and the corporate intranet for shipping, sales, processing and the tasks of internal
administrative.
The company has 3000 employees, the headquarters of the company is in South Carolina, and
the units of manufacturing are in Seattle and Maine. The company wants to open three
international stores in England, Spain and New Zealand. The computing infrastructure of the
Paraphrase This Document
Need a fresh take? Get an instant paraphrase of this document with our AI Paraphraser

4DISTRIBUTED SYSTEMS
company has 300 computers of which 200 computers are in the headquarters and 150
computers both in the manufacturing units. There are 300 printers of which 150 printers are
in the headquarters and 125 printers both in the manufacturing units. There are 200 point-of-
sale terminals of which 100 terminals are in the headquarters and 50 terminals both in the
manufacturing units.
company has 300 computers of which 200 computers are in the headquarters and 150
computers both in the manufacturing units. There are 300 printers of which 150 printers are
in the headquarters and 125 printers both in the manufacturing units. There are 200 point-of-
sale terminals of which 100 terminals are in the headquarters and 50 terminals both in the
manufacturing units.
Running head: DISTRIBUTED SYSTEMS
⊘ This is a preview!⊘
Do you want full access?
Subscribe today to unlock all pages.
Trusted by 1+ million students worldwide

Running head: DISTRIBUTED SYSTEMS
References
Abadi, M., Agarwal, A., Barham, P., Brevdo, E., Chen, Z., Citro, C., ... & Ghemawat, S.
(2016). Tensorflow: Large-scale machine learning on heterogeneous distributed
systems. arXiv preprint arXiv:1603.04467.
Aldin, H. N. S., Deldari, H., Moattar, M. H., & Ghods, M. R. (2019). Consistency models in
distributed systems: A survey on definitions, disciplines, challenges and
applications. arXiv preprint arXiv:1902.03305.
Rouland, Q., Hamid, B., & Jaskolka, J. (2018, October). Formalizing reusable
communication models for distributed systems architecture. In International
Conference on Model and Data Engineering (pp. 198-216). Springer, Cham.
Van Steen, M., & Tanenbaum, A. S. (2017). Distributed systems. Leiden, The Netherlands:
Maarten van Steen.
References
Abadi, M., Agarwal, A., Barham, P., Brevdo, E., Chen, Z., Citro, C., ... & Ghemawat, S.
(2016). Tensorflow: Large-scale machine learning on heterogeneous distributed
systems. arXiv preprint arXiv:1603.04467.
Aldin, H. N. S., Deldari, H., Moattar, M. H., & Ghods, M. R. (2019). Consistency models in
distributed systems: A survey on definitions, disciplines, challenges and
applications. arXiv preprint arXiv:1902.03305.
Rouland, Q., Hamid, B., & Jaskolka, J. (2018, October). Formalizing reusable
communication models for distributed systems architecture. In International
Conference on Model and Data Engineering (pp. 198-216). Springer, Cham.
Van Steen, M., & Tanenbaum, A. S. (2017). Distributed systems. Leiden, The Netherlands:
Maarten van Steen.
Paraphrase This Document
Need a fresh take? Get an instant paraphrase of this document with our AI Paraphraser

1DISTRIBUTED SYSTEMS
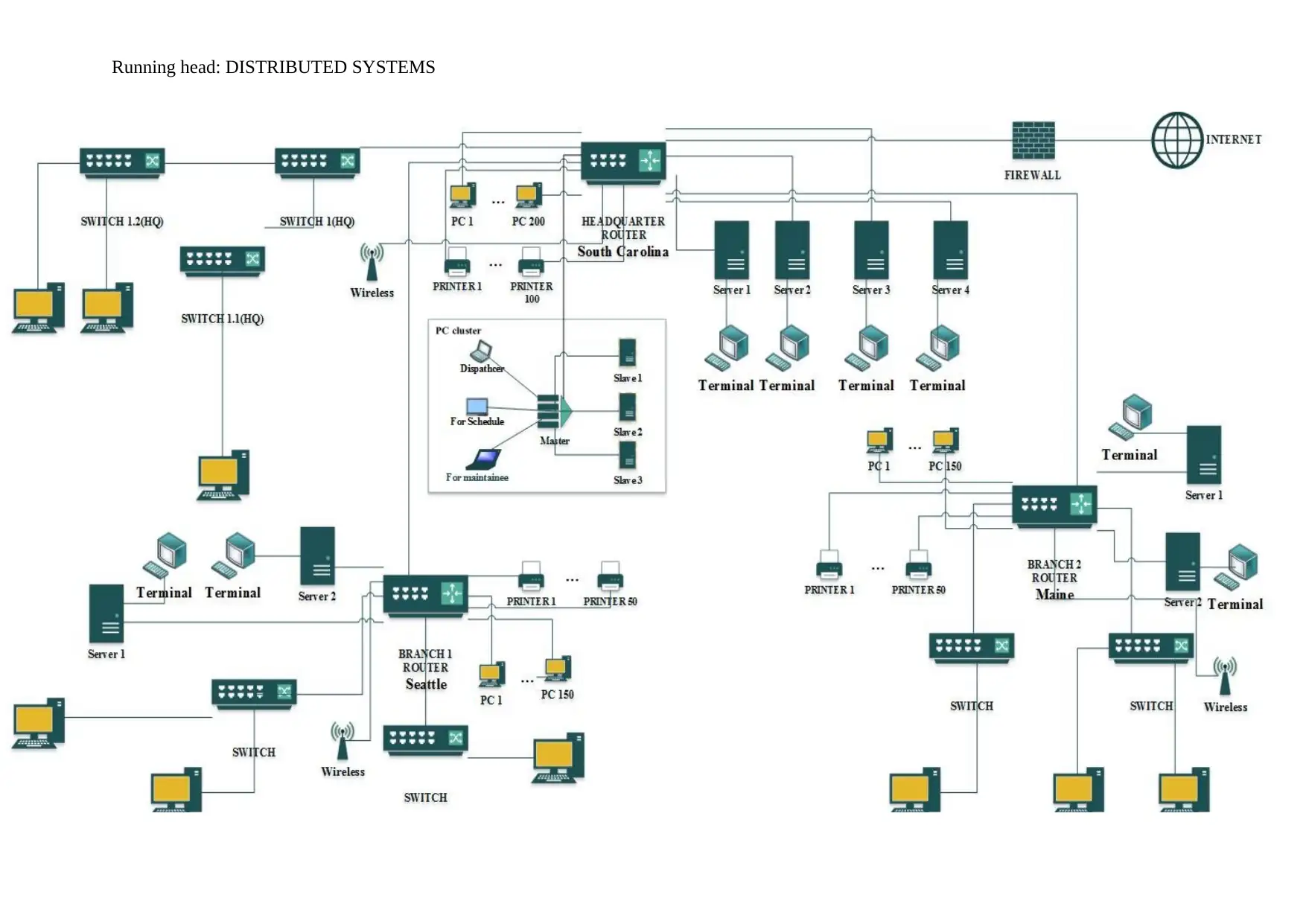
Answer 2
In this, the above diagram is to replaced with the following requirements. The requirements
include:
The system should support more than one agent those are autonomous for the shared
assets while accessing the shared states in order to execute the updates those are based on
real-time.
The state of the system should be distributed across more than one nodes of client or
server
There should be only one service that is centralized that will support the users. It should
support the user to log on, addition of clients or servers, deletion of servers or clients and
perform any other tasks in order to keep the system organized
The system should be robust and it should consist of provisions in order to manage the
fault-tolerance or the gaps in communication.
The server can sometimes become slow when huge amount of work is done and this may
result in slow internet and the work will be done slowly in the company. The server can slow
down due to the large amount of usage of memory (Mirhosseini, Sriraman & Wenisch, 2019).
The server can become slow due to some of the problems of CPU that is high time of
response of services or unavailability. Increase utilisation of the hard disk that includes
increase in the number of logs and loss of data. Increase in network adapter and it is due to
unstable bandwidth, poor time of response and poor application or the performance of service
(Misra et al.,2019).
A robust system or a computer system with robustness means is the capability of a system of
computer to cope up with the errors during the execution and then cope up with the input that
Answer 2
In this, the above diagram is to replaced with the following requirements. The requirements
include:
The system should support more than one agent those are autonomous for the shared
assets while accessing the shared states in order to execute the updates those are based on
real-time.
The state of the system should be distributed across more than one nodes of client or
server
There should be only one service that is centralized that will support the users. It should
support the user to log on, addition of clients or servers, deletion of servers or clients and
perform any other tasks in order to keep the system organized
The system should be robust and it should consist of provisions in order to manage the
fault-tolerance or the gaps in communication.
The server can sometimes become slow when huge amount of work is done and this may
result in slow internet and the work will be done slowly in the company. The server can slow
down due to the large amount of usage of memory (Mirhosseini, Sriraman & Wenisch, 2019).
The server can become slow due to some of the problems of CPU that is high time of
response of services or unavailability. Increase utilisation of the hard disk that includes
increase in the number of logs and loss of data. Increase in network adapter and it is due to
unstable bandwidth, poor time of response and poor application or the performance of service
(Misra et al.,2019).
A robust system or a computer system with robustness means is the capability of a system of
computer to cope up with the errors during the execution and then cope up with the input that

2DISTRIBUTED SYSTEMS
is erroneous (Tran et al.,2017). Robustness can include various areas of computer science
such as the robust programming, robust machine learning, and robust security network.
Fault tolerance refers to the capability of a system to continue operating without any
interruption when one or more than one components of the system fail. The main aim of a
fault tolerant system is to prevent the disruption that is arising from a point of failure that is
single making sure the continuity of business of the company and the high availability of the
applications and the systems those are critical (Abdi et al.,2017). The systems those are fault
tolerant use the backup components that take the place of the components those are failed
making sure that there is no loss of service. These include:
Hardware systems: The systems those are backed up by the systems those are same. Like
example, a server can be made fault tolerant by utilising an equivalent server that is
running in parallel and with all the operations those are always mirrored to the backup
server
The software systems: The systems those are backed by the instances of other software.
For example, a database with the information of the customers can be replicated
continuously to other machine. If the database that is primary does not work, the
operations can be redirected to the second database automatically.
Power sources: The sources of power those are made fault tolerant using the sources those
are alternative. For example, various organizations have various generators of power that
can take over in case when the main line electricity falls.
Fault tolerance can play an important role in the strategy of recovery of disaster (Ganesan et
al.,2017). For example, a system that has the fault-tolerance with the components of backup
in the cloud can easily restore the critical systems quickly even if the disaster that is induced
by the humans or nature destroys the infrastructure of the company.
is erroneous (Tran et al.,2017). Robustness can include various areas of computer science
such as the robust programming, robust machine learning, and robust security network.
Fault tolerance refers to the capability of a system to continue operating without any
interruption when one or more than one components of the system fail. The main aim of a
fault tolerant system is to prevent the disruption that is arising from a point of failure that is
single making sure the continuity of business of the company and the high availability of the
applications and the systems those are critical (Abdi et al.,2017). The systems those are fault
tolerant use the backup components that take the place of the components those are failed
making sure that there is no loss of service. These include:
Hardware systems: The systems those are backed up by the systems those are same. Like
example, a server can be made fault tolerant by utilising an equivalent server that is
running in parallel and with all the operations those are always mirrored to the backup
server
The software systems: The systems those are backed by the instances of other software.
For example, a database with the information of the customers can be replicated
continuously to other machine. If the database that is primary does not work, the
operations can be redirected to the second database automatically.
Power sources: The sources of power those are made fault tolerant using the sources those
are alternative. For example, various organizations have various generators of power that
can take over in case when the main line electricity falls.
Fault tolerance can play an important role in the strategy of recovery of disaster (Ganesan et
al.,2017). For example, a system that has the fault-tolerance with the components of backup
in the cloud can easily restore the critical systems quickly even if the disaster that is induced
by the humans or nature destroys the infrastructure of the company.
⊘ This is a preview!⊘
Do you want full access?
Subscribe today to unlock all pages.
Trusted by 1+ million students worldwide
Running head: DISTRIBUTED SYSTEMS
Paraphrase This Document
Need a fresh take? Get an instant paraphrase of this document with our AI Paraphraser

Running head: DISTRIBUTED SYSTEMS
References
Abdi, F., Tabish, R., Rungger, M., Zamani, M., & Caccamo, M. (2017, April). Application
and system-level software fault tolerance through full system restarts. In 2017
ACM/IEEE 8th International Conference on Cyber-Physical Systems (ICCPS) (pp.
197-206). IEEE.
Ganesan, A., Alagappan, R., Arpaci-Dusseau, A. C., & Arpaci-Dusseau, R. H. (2017).
Redundancy does not imply fault tolerance: Analysis of distributed storage reactions
to single errors and corruptions. In 15th {USENIX} Conference on File and Storage
Technologies ({FAST} 17) (pp. 149-166).
Mirhosseini, A., Sriraman, A., & Wenisch, T. F. (2019, February). Enhancing server
efficiency in the face of killer microseconds. In 2019 IEEE International Symposium
on High Performance Computer Architecture (HPCA) (pp. 185-198). IEEE.
Misra, P. A., Borge, M. F., Goiri, Í., Lebeck, A. R., Zwaenepoel, W., & Bianchini, R. (2019,
March). Managing tail latency in datacenter-scale file systems under production
constraints. In Proceedings of the Fourteenth EuroSys Conference 2019 (pp. 1-15).
Tran, T. A., Oh, K., Na, I. S., Lee, G. S., Yang, H. J., & Kim, S. H. (2017). A robust system
for document layout analysis using multilevel homogeneity structure. Expert Systems
With Applications, 85, 99-113.
References
Abdi, F., Tabish, R., Rungger, M., Zamani, M., & Caccamo, M. (2017, April). Application
and system-level software fault tolerance through full system restarts. In 2017
ACM/IEEE 8th International Conference on Cyber-Physical Systems (ICCPS) (pp.
197-206). IEEE.
Ganesan, A., Alagappan, R., Arpaci-Dusseau, A. C., & Arpaci-Dusseau, R. H. (2017).
Redundancy does not imply fault tolerance: Analysis of distributed storage reactions
to single errors and corruptions. In 15th {USENIX} Conference on File and Storage
Technologies ({FAST} 17) (pp. 149-166).
Mirhosseini, A., Sriraman, A., & Wenisch, T. F. (2019, February). Enhancing server
efficiency in the face of killer microseconds. In 2019 IEEE International Symposium
on High Performance Computer Architecture (HPCA) (pp. 185-198). IEEE.
Misra, P. A., Borge, M. F., Goiri, Í., Lebeck, A. R., Zwaenepoel, W., & Bianchini, R. (2019,
March). Managing tail latency in datacenter-scale file systems under production
constraints. In Proceedings of the Fourteenth EuroSys Conference 2019 (pp. 1-15).
Tran, T. A., Oh, K., Na, I. S., Lee, G. S., Yang, H. J., & Kim, S. H. (2017). A robust system
for document layout analysis using multilevel homogeneity structure. Expert Systems
With Applications, 85, 99-113.

1DISTRIBUTED SYSTEMS
Answer 3:
The servers that will be implemented to the company include the database server,
email server and a file sharing system. These protocols will help in to handle the
communications between the various entities.
A database server is the portion that is at the backend of an application of database
that follows the tradition of the model of client-server. The portion of back-end is called the
instance (Fadhilah, Tulloh & Novianto, 2018). It can also refer to the physical computer that
is utilised in order to host the database. The database server is a higher-end computer that is
used in order to host the database. The server of database is independent of the architecture of
the database. The databases those are relational, flat files and the databases those are non-
relational. All of these databases can be accommodated on the servers of database. In the
model of client server, there is always a dedicated host that is used in order to execute and
server up the assets, typically multiple applications of software (Gunawan et al.,2016). There
are also various clients that can connect to the server and then utilise the resources those are
provided and hosted by the server. When the databases are considered in the model of client
server, the server of database can be at the backend of the application of database or it can be
the hardware of the computer that is used in order to host the instance. Sometimes, it can also
refer to the combination of the both softwares and the hardwares (Jawad, 2020).
A file does not normally execute the tasks of computational or execute the programs
on behalf of the workstations of the client. The file server is usually found in the schools and
the offices where various users use the local area network in order to connect their client
computers. A file server can be non-dedicated or dedicated (Amrutha, & Revathy, 2017). A
file server that is dedicated is particularly designed for the utilisation as the file server, with
the various workstations those are attached in order to read and write the files and the
Answer 3:
The servers that will be implemented to the company include the database server,
email server and a file sharing system. These protocols will help in to handle the
communications between the various entities.
A database server is the portion that is at the backend of an application of database
that follows the tradition of the model of client-server. The portion of back-end is called the
instance (Fadhilah, Tulloh & Novianto, 2018). It can also refer to the physical computer that
is utilised in order to host the database. The database server is a higher-end computer that is
used in order to host the database. The server of database is independent of the architecture of
the database. The databases those are relational, flat files and the databases those are non-
relational. All of these databases can be accommodated on the servers of database. In the
model of client server, there is always a dedicated host that is used in order to execute and
server up the assets, typically multiple applications of software (Gunawan et al.,2016). There
are also various clients that can connect to the server and then utilise the resources those are
provided and hosted by the server. When the databases are considered in the model of client
server, the server of database can be at the backend of the application of database or it can be
the hardware of the computer that is used in order to host the instance. Sometimes, it can also
refer to the combination of the both softwares and the hardwares (Jawad, 2020).
A file does not normally execute the tasks of computational or execute the programs
on behalf of the workstations of the client. The file server is usually found in the schools and
the offices where various users use the local area network in order to connect their client
computers. A file server can be non-dedicated or dedicated (Amrutha, & Revathy, 2017). A
file server that is dedicated is particularly designed for the utilisation as the file server, with
the various workstations those are attached in order to read and write the files and the
⊘ This is a preview!⊘
Do you want full access?
Subscribe today to unlock all pages.
Trusted by 1+ million students worldwide
1 out of 43


Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Unlock your academic potential
Copyright © 2020–2026 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.