Econometrics Report: R-squared Interpretation and Regression Models
VerifiedAdded on 2023/06/14
|7
|1090
|329
Report
AI Summary
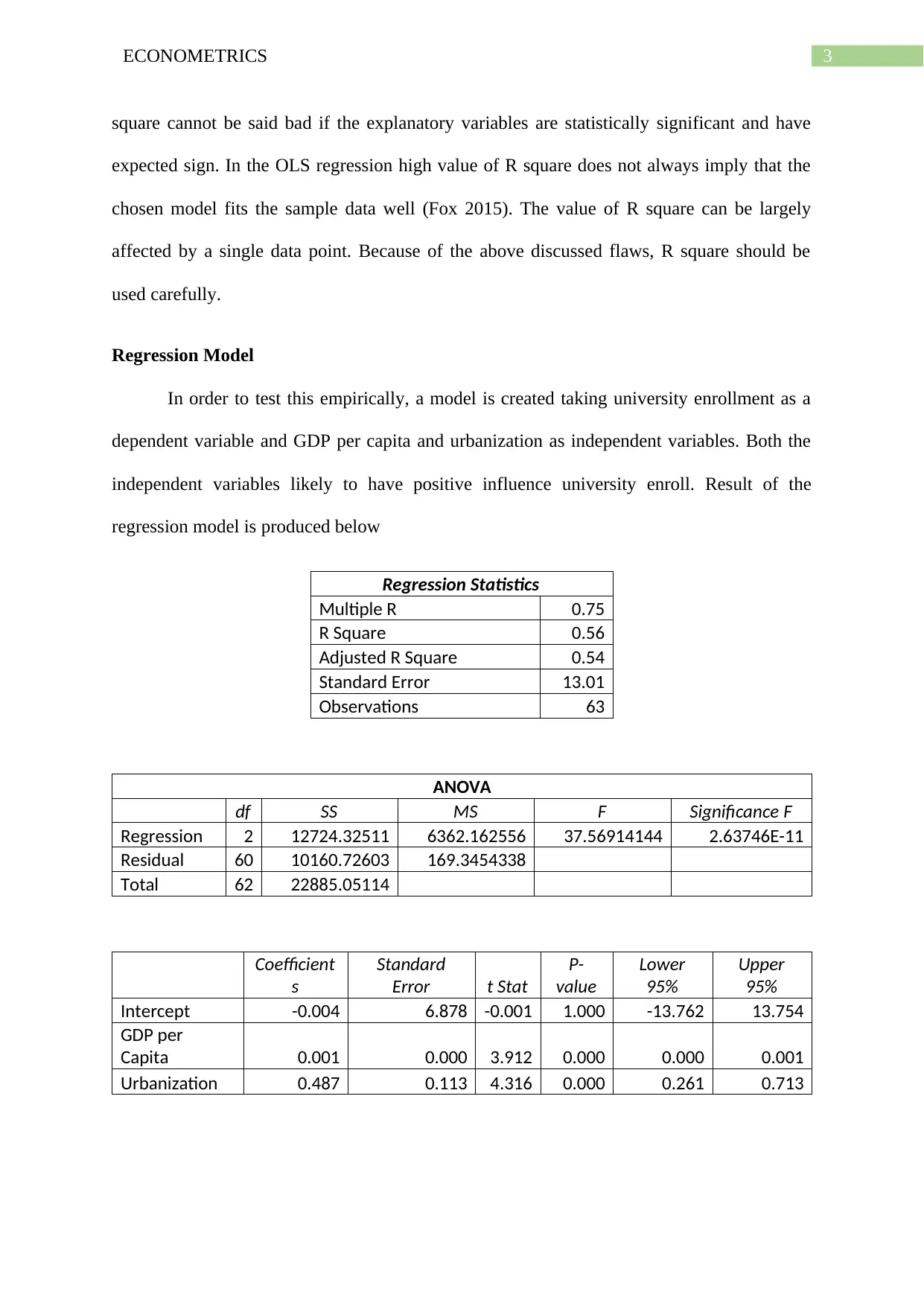
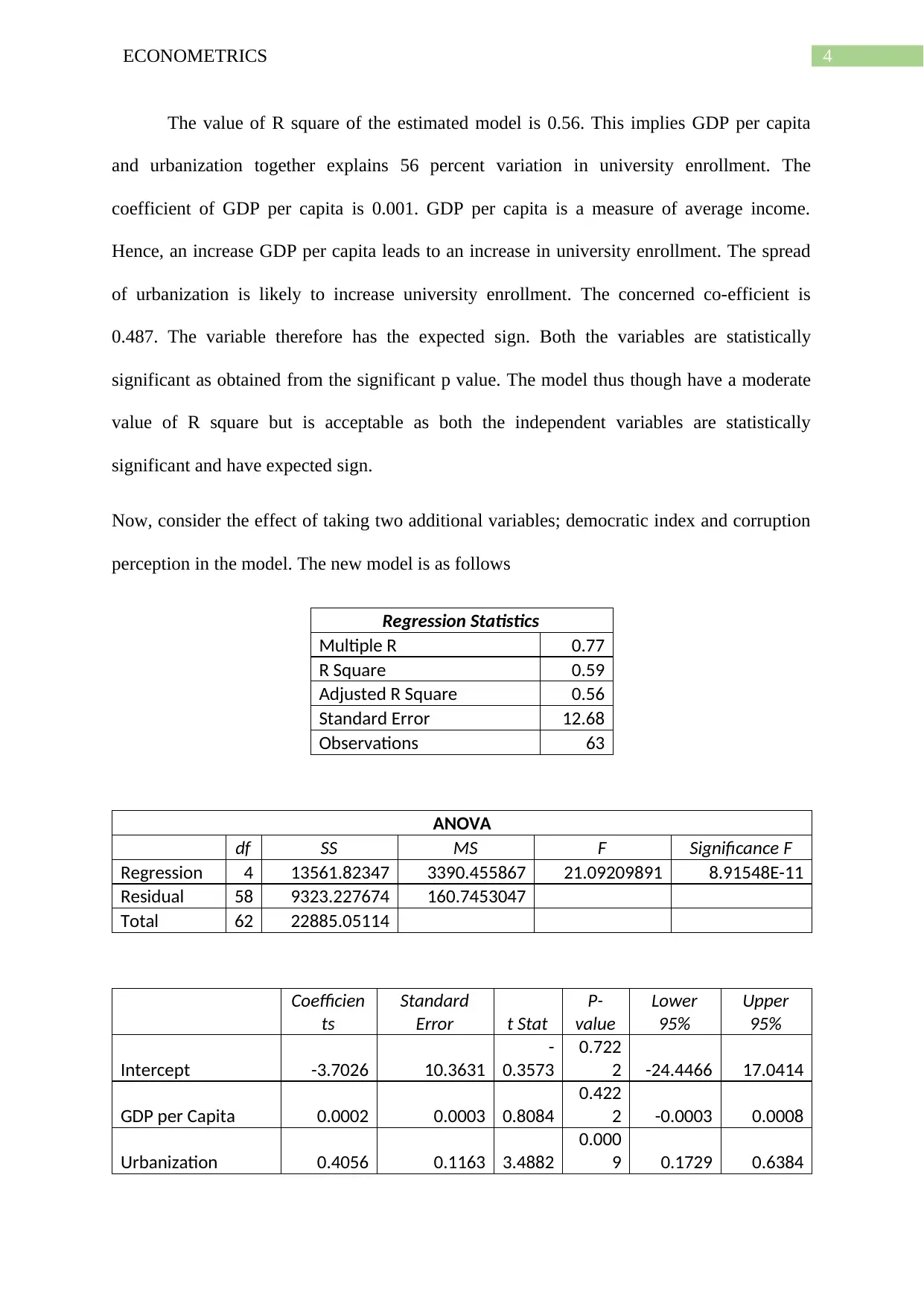
This report provides an analysis of R-squared statistics and their application in econometrics, emphasizing the importance of careful interpretation and avoiding misuse. It discusses how researchers often attempt to maximize R-squared values by adding independent variables, which can lead to models with high R-squared but low statistical significance. The report includes a regression model using university enrollment as the dependent variable and GDP per capita and urbanization as independent variables, demonstrating the impact of adding democratic index and corruption perception variables. It concludes that a model with a moderate R-squared but statistically significant and theoretically relevant variables is preferable to a model with a high R-squared but insignificant variables. Desklib offers a range of past papers and solved assignments for students seeking further assistance.





1 out of 7
Related Documents






Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Copyright © 2020–2026 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.