BB108 Business Statistics: Employee Satisfaction Report Analysis
VerifiedAdded on 2022/11/13
|9
|1607
|207
Report
AI Summary
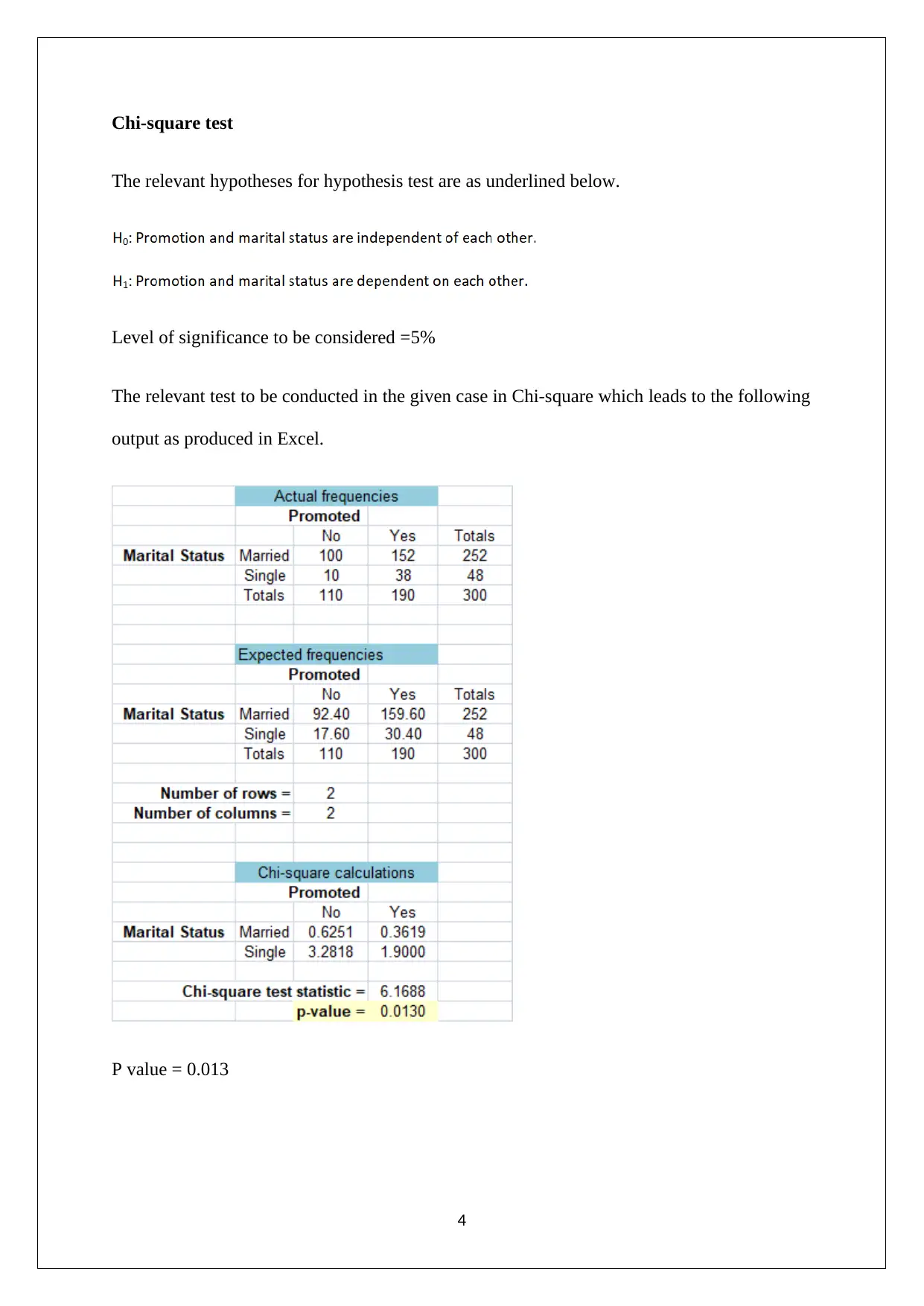
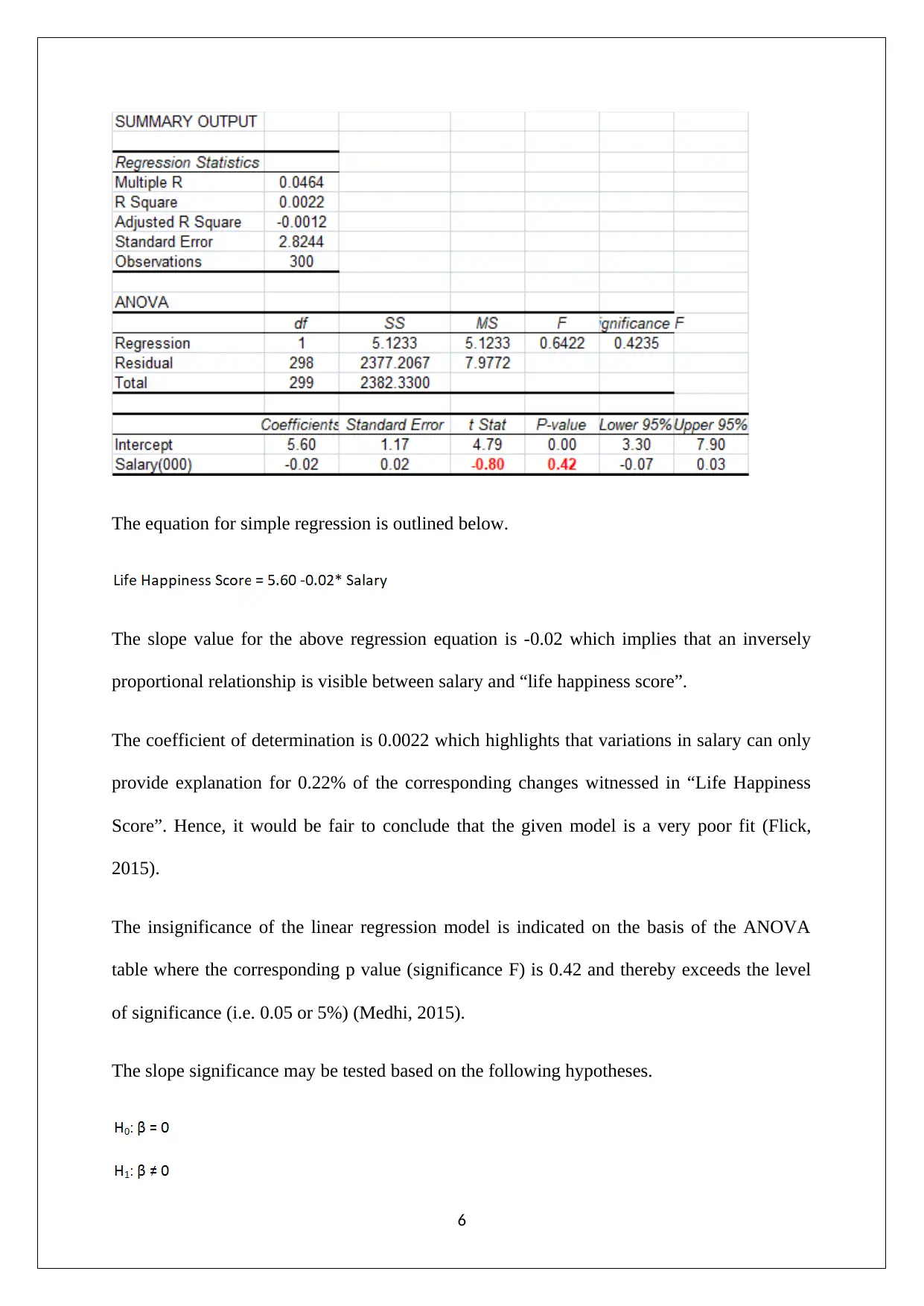
This report provides a statistical analysis of employee satisfaction within a global company facing issues related to low satisfaction levels. The analysis is based on a survey of 300 employees, employing both descriptive and inferential statistical techniques. Key areas explored include variance and standard deviation, covariance between satisfaction and happiness, z-scores for age and salary, a Chi-square test to determine the relationship between marital status and promotion, and correlation and regression analyses to examine the relationships between various factors like experience, salary, and life happiness. The findings reveal insights into the impact of training, the relationship between job satisfaction and life happiness, the dependency between promotion and marital status, and the lack of correlation between salary and experience or happiness. The report concludes with recommendations for the company, suggesting a shift away from salary-driven incentives and a focus on addressing employee needs through intangible rewards like recognition, training, and improved work quality, along with regular feedback collection and analysis to gauge the effectiveness of implemented initiatives. The report uses Excel for calculations and references relevant academic literature.







1 out of 9
Related Documents






Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Copyright © 2020–2026 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.