Financial Performance Analysis: Community Spending and Company Value
VerifiedAdded on 2023/06/07
|16
|3224
|455
Report
AI Summary
This report delves into the financial implications of community spending for selected companies, employing a quantitative research methodology. The study utilizes secondary data and employs SPSS for data analysis, focusing on regression and correlation analysis to determine relationships between variables. Key financial metrics, including Return on Assets (ROA), market value, and dividend per share, are examined in relation to community spending. The analysis reveals a significant impact of community spending on both ROA and market value. Regression analysis indicates a low correlation between community spending and ROA, but a high degree of correlation between community spending and market value. The study also explores the impact of community spending on dividend per share, providing valuable insights into the financial performance implications of corporate social responsibility initiatives. The report concludes with interpretations of the statistical findings, highlighting the significance of community spending on the financial health of the analyzed companies.

Finance and
Accounting
Accounting
Paraphrase This Document
Need a fresh take? Get an instant paraphrase of this document with our AI Paraphraser

Table of Contents
RESEARCH METHODOLOGY.........................................................................................................................3
DATA ANALYSIS USING SPSS........................................................................................................................4
REGRESSION ANALYSIS OF RETURN ON ASSETS......................................................................................4
REGRESSION VALUE OF MARKET VALUE.................................................................................................7
REGRESSION VALUE OF DIVIDEND PER SHARE........................................................................................9
REGRESSION VALUE OF OPERATING MARGIN.......................................................................................11
REGRESSION VALUE OF NET INCOME....................................................................................................13
RESEARCH METHODOLOGY.........................................................................................................................3
DATA ANALYSIS USING SPSS........................................................................................................................4
REGRESSION ANALYSIS OF RETURN ON ASSETS......................................................................................4
REGRESSION VALUE OF MARKET VALUE.................................................................................................7
REGRESSION VALUE OF DIVIDEND PER SHARE........................................................................................9
REGRESSION VALUE OF OPERATING MARGIN.......................................................................................11
REGRESSION VALUE OF NET INCOME....................................................................................................13

RESEARCH METHODOLOGY
It is that part in the research which helps in gathering right kind of data for the study. It is
the systematic and scientific procedure through which accurate data for the study is gathered and
analysed. This section also helps in attaining aim and objective in right manner by inspecting the
hypothesis and theories. In this part research problem is also being addressed effectively with the
help of collected and evaluated information. The readers of the study are also interested to know
the type of data used so that overall validity and reliability of the study can be maintained
appropriately.
Research philosophy: There are two types of research philosophies which are as
positivism and interpretivism. According to the current investigation, investigator has selected
positivism philosophy. This is because using this objective data is gathered that helps in
understanding the social world in effective way. The positivism philosophy also helps in
identifying the correct trend and pattern prevailing in the society.
Research approach: Research approach is that part in the research which helps in
addressing the research problem in effective way. This sub parts are further divided into types
that are deductive and inductive approach. According to the present research, investigator has
opted for deductive research approach. This is because it helps in testing the existing hypothesis
which is formulated after the research problem is identified. Using this existing hypothesis is
being addressed using quantitative data.
Research strategy: It is that part in the methodology which helps in providing the path
to the thought and idea of the investigation. This is that layer through which data is gathered in
right way. Survey, case study, experimental research, action research and many more are some
kinds of research strategies. As per the existing investigation, investigator has chosen case study
research strategy. The main reason is empirical study in depth manner is done with the help of
numerical data.
Research choice: There are three types of research method which are quantitative,
qualitative and mixed method. In the current investigation investigator has selected quantitative
research method. The main advantage to use this method is that numerical information is
It is that part in the research which helps in gathering right kind of data for the study. It is
the systematic and scientific procedure through which accurate data for the study is gathered and
analysed. This section also helps in attaining aim and objective in right manner by inspecting the
hypothesis and theories. In this part research problem is also being addressed effectively with the
help of collected and evaluated information. The readers of the study are also interested to know
the type of data used so that overall validity and reliability of the study can be maintained
appropriately.
Research philosophy: There are two types of research philosophies which are as
positivism and interpretivism. According to the current investigation, investigator has selected
positivism philosophy. This is because using this objective data is gathered that helps in
understanding the social world in effective way. The positivism philosophy also helps in
identifying the correct trend and pattern prevailing in the society.
Research approach: Research approach is that part in the research which helps in
addressing the research problem in effective way. This sub parts are further divided into types
that are deductive and inductive approach. According to the present research, investigator has
opted for deductive research approach. This is because it helps in testing the existing hypothesis
which is formulated after the research problem is identified. Using this existing hypothesis is
being addressed using quantitative data.
Research strategy: It is that part in the methodology which helps in providing the path
to the thought and idea of the investigation. This is that layer through which data is gathered in
right way. Survey, case study, experimental research, action research and many more are some
kinds of research strategies. As per the existing investigation, investigator has chosen case study
research strategy. The main reason is empirical study in depth manner is done with the help of
numerical data.
Research choice: There are three types of research method which are quantitative,
qualitative and mixed method. In the current investigation investigator has selected quantitative
research method. The main advantage to use this method is that numerical information is
⊘ This is a preview!⊘
Do you want full access?
Subscribe today to unlock all pages.
Trusted by 1+ million students worldwide

gathered and analysed. Data is gathered and analysed in numbers and figure that show true
picture. Overall reliability is also maintained with the help of quantitative data.
Time horizon: It is the time framework that helps in knowing the point of time at which
data need to be collected and whole investigation will be completed. There are two-time horizon
that are cross sectional and longitudinal. As per the present research, cross sectional time horizon
is used to gather data in single time and complete the overall investigation in shorter time
duration.
Data collection method: There are two source for collecting data which are primary and
secondary. In the existing investigation, investigator has selected secondary source. This is
because it helps in gathering wider second hand information for the study. The data is collected
using books, journal, magazine and online site.
Data analysis: As per the current investigation the data is being inspected using SPSS
tool. This is because using this numerical data can be gathered accurately as well as hypothesis
can be tested effectively.
DATA ANALYSIS USING SPSS
In the current research investigator has inspected the raw data with the help of SPSS tool so that
useful information can be obtained. In this software the function which is performed by the
researcher is regression and correlation analysis. Regression is a statistical analysis which helps
in determine the relationship between the two variable which are independent and dependent
variable. Using this method researcher will identify the impact of between the two variable in
significant manner.
REGRESSION ANALYSIS OF RETURN ON ASSETS
H0: There is no significant impact of community spending on return on assets on selected companies
H1: There is significant impact of community spending on return on assets on selected companies
Descriptive Statistics
Mean Std. Deviation N
Community spending 15.3106 28.76537 440
Return on Assets 11.0241 34.06348 440
picture. Overall reliability is also maintained with the help of quantitative data.
Time horizon: It is the time framework that helps in knowing the point of time at which
data need to be collected and whole investigation will be completed. There are two-time horizon
that are cross sectional and longitudinal. As per the present research, cross sectional time horizon
is used to gather data in single time and complete the overall investigation in shorter time
duration.
Data collection method: There are two source for collecting data which are primary and
secondary. In the existing investigation, investigator has selected secondary source. This is
because it helps in gathering wider second hand information for the study. The data is collected
using books, journal, magazine and online site.
Data analysis: As per the current investigation the data is being inspected using SPSS
tool. This is because using this numerical data can be gathered accurately as well as hypothesis
can be tested effectively.
DATA ANALYSIS USING SPSS
In the current research investigator has inspected the raw data with the help of SPSS tool so that
useful information can be obtained. In this software the function which is performed by the
researcher is regression and correlation analysis. Regression is a statistical analysis which helps
in determine the relationship between the two variable which are independent and dependent
variable. Using this method researcher will identify the impact of between the two variable in
significant manner.
REGRESSION ANALYSIS OF RETURN ON ASSETS
H0: There is no significant impact of community spending on return on assets on selected companies
H1: There is significant impact of community spending on return on assets on selected companies
Descriptive Statistics
Mean Std. Deviation N
Community spending 15.3106 28.76537 440
Return on Assets 11.0241 34.06348 440
Paraphrase This Document
Need a fresh take? Get an instant paraphrase of this document with our AI Paraphraser
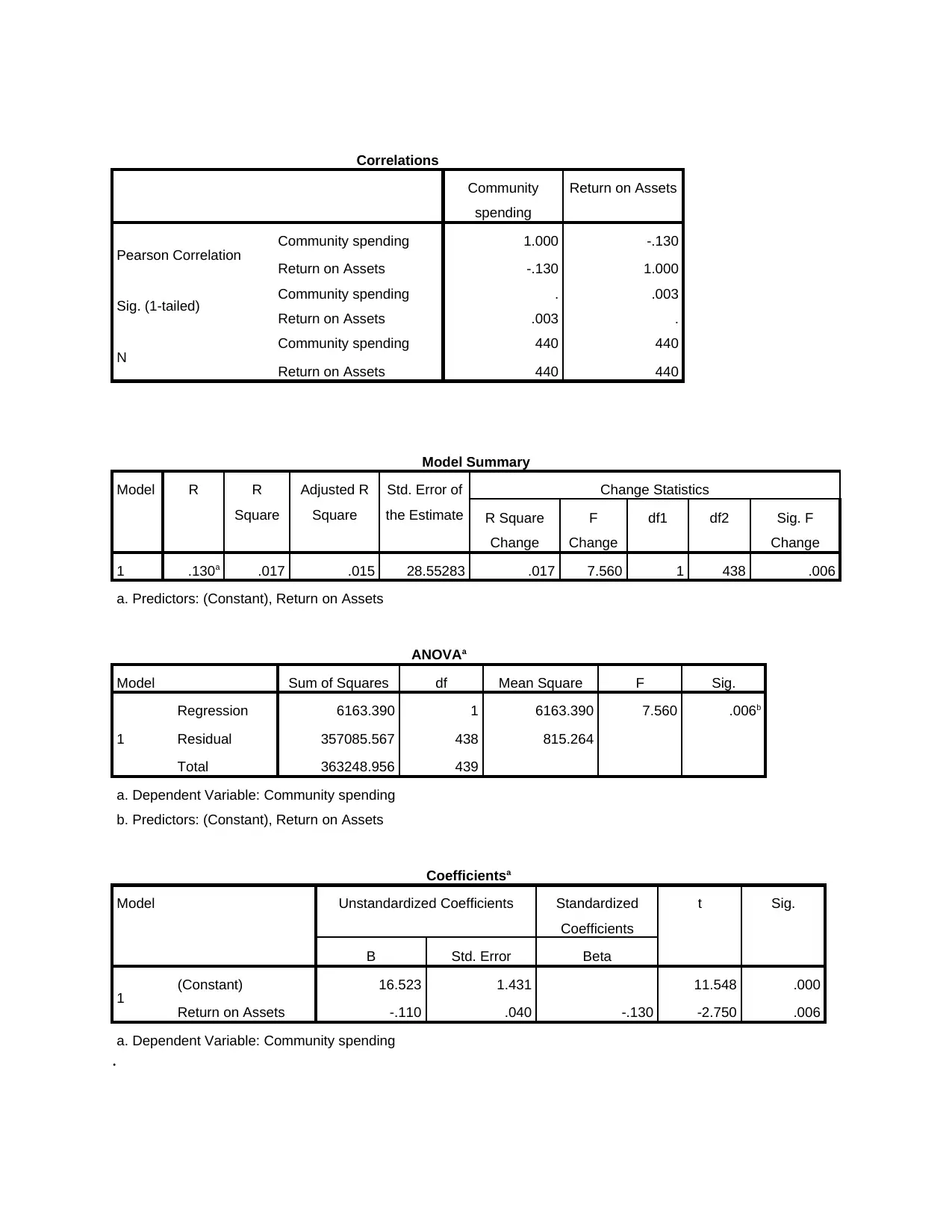
Correlations
Community
spending
Return on Assets
Pearson Correlation Community spending 1.000 -.130
Return on Assets -.130 1.000
Sig. (1-tailed) Community spending . .003
Return on Assets .003 .
N Community spending 440 440
Return on Assets 440 440
Model Summary
Model R R
Square
Adjusted R
Square
Std. Error of
the Estimate
Change Statistics
R Square
Change
F
Change
df1 df2 Sig. F
Change
1 .130a .017 .015 28.55283 .017 7.560 1 438 .006
a. Predictors: (Constant), Return on Assets
ANOVAa
Model Sum of Squares df Mean Square F Sig.
1
Regression 6163.390 1 6163.390 7.560 .006b
Residual 357085.567 438 815.264
Total 363248.956 439
a. Dependent Variable: Community spending
b. Predictors: (Constant), Return on Assets
Coefficientsa
Model Unstandardized Coefficients Standardized
Coefficients
t Sig.
B Std. Error Beta
1 (Constant) 16.523 1.431 11.548 .000
Return on Assets -.110 .040 -.130 -2.750 .006
a. Dependent Variable: Community spending
.
Community
spending
Return on Assets
Pearson Correlation Community spending 1.000 -.130
Return on Assets -.130 1.000
Sig. (1-tailed) Community spending . .003
Return on Assets .003 .
N Community spending 440 440
Return on Assets 440 440
Model Summary
Model R R
Square
Adjusted R
Square
Std. Error of
the Estimate
Change Statistics
R Square
Change
F
Change
df1 df2 Sig. F
Change
1 .130a .017 .015 28.55283 .017 7.560 1 438 .006
a. Predictors: (Constant), Return on Assets
ANOVAa
Model Sum of Squares df Mean Square F Sig.
1
Regression 6163.390 1 6163.390 7.560 .006b
Residual 357085.567 438 815.264
Total 363248.956 439
a. Dependent Variable: Community spending
b. Predictors: (Constant), Return on Assets
Coefficientsa
Model Unstandardized Coefficients Standardized
Coefficients
t Sig.
B Std. Error Beta
1 (Constant) 16.523 1.431 11.548 .000
Return on Assets -.110 .040 -.130 -2.750 .006
a. Dependent Variable: Community spending
.

Interpretation: From of the above table it is being analyses that the average mean on return on
assets of the selected companies is 11.0241 and the average mean for community spending is
15.3106. the standard deviation for community spending can vary up to 28.765 and for return on
investment is 34.06. This means and that the selected 440 companies means can very on return
on assets up to 34.06.
This table helps in providing the value of R and R2. The R value represent the simple correlation
and it is 0.130. This indicate a low degree of correlation between the variables. The R2value
indicate the total variation that that take place in dependent variable which is community
spending. And independent variable that is return on assets. In this the R2 value is 0.017, which is
low.
Next table is ANOVA table which shows the significance value of the regression model. Here
the p value is 0.006 which is less than 0.05. This means that the null hypothesis in this case is
rejected. The sum square of the variable is 6163.390.
From the above table it is predicted that the regression equation for community spending in case
of return on asset is
Community spending = 16.52-0.110
= 16.41
So from the above analysis it is interpreted that there is a significant impact of community
spending on return of assets o0f above selected 440 companies
assets of the selected companies is 11.0241 and the average mean for community spending is
15.3106. the standard deviation for community spending can vary up to 28.765 and for return on
investment is 34.06. This means and that the selected 440 companies means can very on return
on assets up to 34.06.
This table helps in providing the value of R and R2. The R value represent the simple correlation
and it is 0.130. This indicate a low degree of correlation between the variables. The R2value
indicate the total variation that that take place in dependent variable which is community
spending. And independent variable that is return on assets. In this the R2 value is 0.017, which is
low.
Next table is ANOVA table which shows the significance value of the regression model. Here
the p value is 0.006 which is less than 0.05. This means that the null hypothesis in this case is
rejected. The sum square of the variable is 6163.390.
From the above table it is predicted that the regression equation for community spending in case
of return on asset is
Community spending = 16.52-0.110
= 16.41
So from the above analysis it is interpreted that there is a significant impact of community
spending on return of assets o0f above selected 440 companies
⊘ This is a preview!⊘
Do you want full access?
Subscribe today to unlock all pages.
Trusted by 1+ million students worldwide
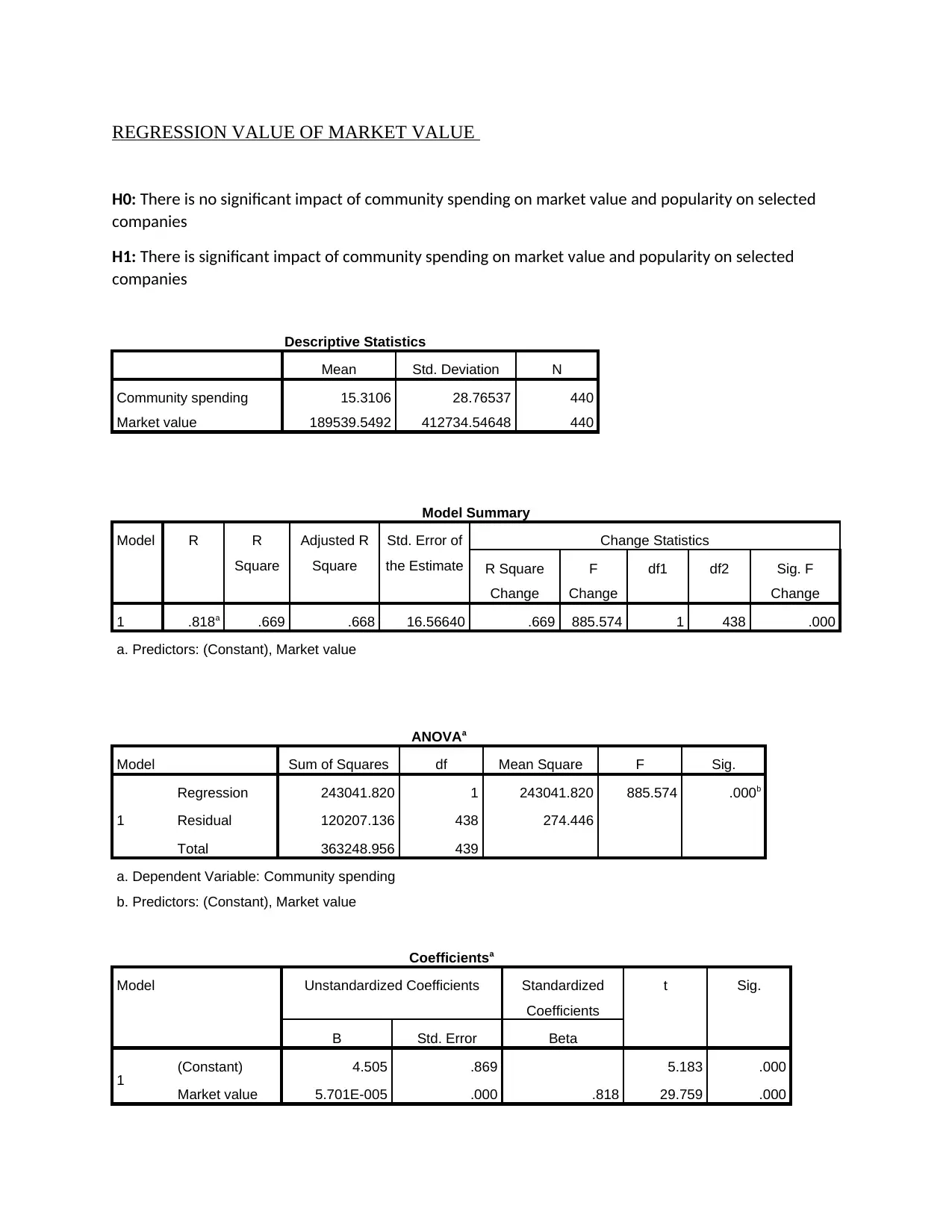
REGRESSION VALUE OF MARKET VALUE
H0: There is no significant impact of community spending on market value and popularity on selected
companies
H1: There is significant impact of community spending on market value and popularity on selected
companies
Descriptive Statistics
Mean Std. Deviation N
Community spending 15.3106 28.76537 440
Market value 189539.5492 412734.54648 440
Model Summary
Model R R
Square
Adjusted R
Square
Std. Error of
the Estimate
Change Statistics
R Square
Change
F
Change
df1 df2 Sig. F
Change
1 .818a .669 .668 16.56640 .669 885.574 1 438 .000
a. Predictors: (Constant), Market value
ANOVAa
Model Sum of Squares df Mean Square F Sig.
1
Regression 243041.820 1 243041.820 885.574 .000b
Residual 120207.136 438 274.446
Total 363248.956 439
a. Dependent Variable: Community spending
b. Predictors: (Constant), Market value
Coefficientsa
Model Unstandardized Coefficients Standardized
Coefficients
t Sig.
B Std. Error Beta
1 (Constant) 4.505 .869 5.183 .000
Market value 5.701E-005 .000 .818 29.759 .000
H0: There is no significant impact of community spending on market value and popularity on selected
companies
H1: There is significant impact of community spending on market value and popularity on selected
companies
Descriptive Statistics
Mean Std. Deviation N
Community spending 15.3106 28.76537 440
Market value 189539.5492 412734.54648 440
Model Summary
Model R R
Square
Adjusted R
Square
Std. Error of
the Estimate
Change Statistics
R Square
Change
F
Change
df1 df2 Sig. F
Change
1 .818a .669 .668 16.56640 .669 885.574 1 438 .000
a. Predictors: (Constant), Market value
ANOVAa
Model Sum of Squares df Mean Square F Sig.
1
Regression 243041.820 1 243041.820 885.574 .000b
Residual 120207.136 438 274.446
Total 363248.956 439
a. Dependent Variable: Community spending
b. Predictors: (Constant), Market value
Coefficientsa
Model Unstandardized Coefficients Standardized
Coefficients
t Sig.
B Std. Error Beta
1 (Constant) 4.505 .869 5.183 .000
Market value 5.701E-005 .000 .818 29.759 .000
Paraphrase This Document
Need a fresh take? Get an instant paraphrase of this document with our AI Paraphraser

a. Dependent Variable: Community spending
Interpretation: With the assemble data it is interpreted that the mean value for community
spending is 15.3106 and the market value it is 189539.5492. the standard deviation for
community spending is 28.76 percent and for market value it is 412734.54. from this table it is
interpreted that the variation between the average means of community spending can vary from
28.76 percent of the selected 440 companies and for market value they can differentiate up to
412734 margin.
The above model summary table represent the R and R square value of the market value of
selected 440 companies. The R value represent the correlation value which in the above case
is .818. This indicate that a high degree of correlation lies between the community spending and
market value. The R2 figure shows the overall difference that took place between the dependent
and independent variable. In this case the R square value is .669. That means the company
market value can vary upto certain amount in order to match with the regression value.
This is the ANNOVA table which predict the significance value of the above regression model.
In this particular table the significance value for market value is 0.000. The calculated P value is
less than the set significant value which is 0.05. So in this case the null hypothesises rejected and
the alternative hypothesis is accepted. According to which it indicates that there is significant
impact of community spending on market value and popularity of the company. The sum square
of the above two dependent and independent variables is 243041.820.
From the above coefficient table, it is interpreted that the regression equation for community
spending in respect of market value is
Community spending = 4.505 + 5.701
= 10.206
So from the overall analysis it is summarized that community spending impact the market value
and popularity of the chosen companies in large manner.
Interpretation: With the assemble data it is interpreted that the mean value for community
spending is 15.3106 and the market value it is 189539.5492. the standard deviation for
community spending is 28.76 percent and for market value it is 412734.54. from this table it is
interpreted that the variation between the average means of community spending can vary from
28.76 percent of the selected 440 companies and for market value they can differentiate up to
412734 margin.
The above model summary table represent the R and R square value of the market value of
selected 440 companies. The R value represent the correlation value which in the above case
is .818. This indicate that a high degree of correlation lies between the community spending and
market value. The R2 figure shows the overall difference that took place between the dependent
and independent variable. In this case the R square value is .669. That means the company
market value can vary upto certain amount in order to match with the regression value.
This is the ANNOVA table which predict the significance value of the above regression model.
In this particular table the significance value for market value is 0.000. The calculated P value is
less than the set significant value which is 0.05. So in this case the null hypothesises rejected and
the alternative hypothesis is accepted. According to which it indicates that there is significant
impact of community spending on market value and popularity of the company. The sum square
of the above two dependent and independent variables is 243041.820.
From the above coefficient table, it is interpreted that the regression equation for community
spending in respect of market value is
Community spending = 4.505 + 5.701
= 10.206
So from the overall analysis it is summarized that community spending impact the market value
and popularity of the chosen companies in large manner.
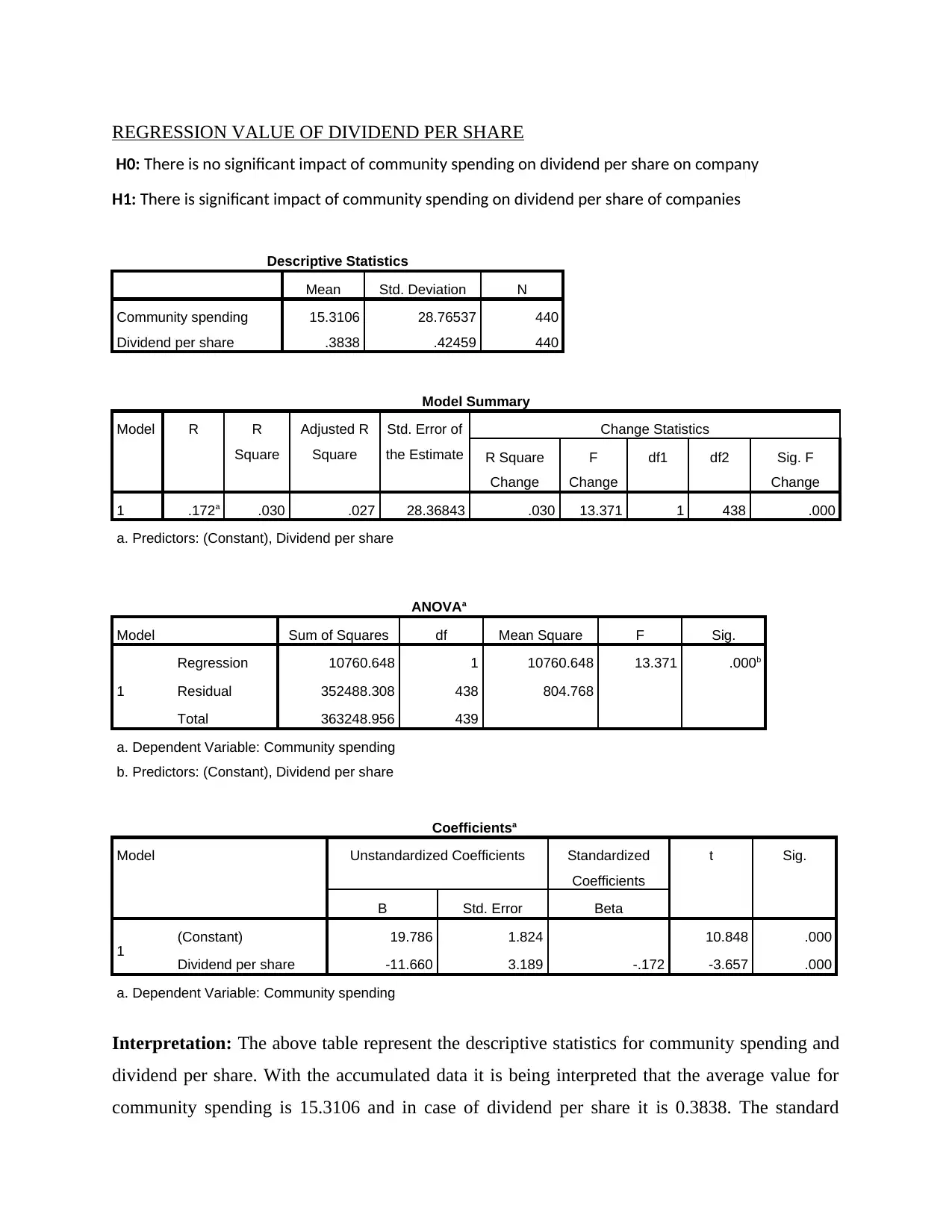
REGRESSION VALUE OF DIVIDEND PER SHARE
H0: There is no significant impact of community spending on dividend per share on company
H1: There is significant impact of community spending on dividend per share of companies
Descriptive Statistics
Mean Std. Deviation N
Community spending 15.3106 28.76537 440
Dividend per share .3838 .42459 440
Model Summary
Model R R
Square
Adjusted R
Square
Std. Error of
the Estimate
Change Statistics
R Square
Change
F
Change
df1 df2 Sig. F
Change
1 .172a .030 .027 28.36843 .030 13.371 1 438 .000
a. Predictors: (Constant), Dividend per share
ANOVAa
Model Sum of Squares df Mean Square F Sig.
1
Regression 10760.648 1 10760.648 13.371 .000b
Residual 352488.308 438 804.768
Total 363248.956 439
a. Dependent Variable: Community spending
b. Predictors: (Constant), Dividend per share
Coefficientsa
Model Unstandardized Coefficients Standardized
Coefficients
t Sig.
B Std. Error Beta
1 (Constant) 19.786 1.824 10.848 .000
Dividend per share -11.660 3.189 -.172 -3.657 .000
a. Dependent Variable: Community spending
Interpretation: The above table represent the descriptive statistics for community spending and
dividend per share. With the accumulated data it is being interpreted that the average value for
community spending is 15.3106 and in case of dividend per share it is 0.3838. The standard
H0: There is no significant impact of community spending on dividend per share on company
H1: There is significant impact of community spending on dividend per share of companies
Descriptive Statistics
Mean Std. Deviation N
Community spending 15.3106 28.76537 440
Dividend per share .3838 .42459 440
Model Summary
Model R R
Square
Adjusted R
Square
Std. Error of
the Estimate
Change Statistics
R Square
Change
F
Change
df1 df2 Sig. F
Change
1 .172a .030 .027 28.36843 .030 13.371 1 438 .000
a. Predictors: (Constant), Dividend per share
ANOVAa
Model Sum of Squares df Mean Square F Sig.
1
Regression 10760.648 1 10760.648 13.371 .000b
Residual 352488.308 438 804.768
Total 363248.956 439
a. Dependent Variable: Community spending
b. Predictors: (Constant), Dividend per share
Coefficientsa
Model Unstandardized Coefficients Standardized
Coefficients
t Sig.
B Std. Error Beta
1 (Constant) 19.786 1.824 10.848 .000
Dividend per share -11.660 3.189 -.172 -3.657 .000
a. Dependent Variable: Community spending
Interpretation: The above table represent the descriptive statistics for community spending and
dividend per share. With the accumulated data it is being interpreted that the average value for
community spending is 15.3106 and in case of dividend per share it is 0.3838. The standard
⊘ This is a preview!⊘
Do you want full access?
Subscribe today to unlock all pages.
Trusted by 1+ million students worldwide

deviation for community spending is 28.76 percent and for dividend per share it is .42459. so
from this table it is analysed that the variation between the mean community can be 28 percent in
the selected companies from Forbes.
The next table after the descriptive statistics is Model summary table which predict the R and R
square value of the dividend per share in context to the dependent variable community spending.
The correlation value is the R value which is .172. This indicate low correlation between the
variable because the range lies below .25. R2 is the sum square of the variable which shows the
variation between the dependent and independent variable. The r square is .030 that indicate the
correlations value can be differentiate upto 0.30.
Another table for dividend per share is ANNOVA table which pays a very significant role in
regression. This is because this table predict whether the null hypothesis will be rejected or
accepted. In the respect of dividend per share the significance value that is p value is 0.000. this
predicted p value is less than 0.005 significant value. So in this case alternative hypothesis will
be accepted and the null hypothesis is rejected. That means that there is significant impact of
community spending on dividend per share of the companies. The sum square of the above two
dependent and independent variables is 10760.648.
One of the important table is coefficient table that interpreted the true regression value of the
dependent variable in terms of independent variable. The regression equation for community
spending in context of dividend per share is
Community spending = 19.786 -11.660
= 8.126
It is summarized that community spending impact the market value and popularity of the chosen
companies in large manner.
from this table it is analysed that the variation between the mean community can be 28 percent in
the selected companies from Forbes.
The next table after the descriptive statistics is Model summary table which predict the R and R
square value of the dividend per share in context to the dependent variable community spending.
The correlation value is the R value which is .172. This indicate low correlation between the
variable because the range lies below .25. R2 is the sum square of the variable which shows the
variation between the dependent and independent variable. The r square is .030 that indicate the
correlations value can be differentiate upto 0.30.
Another table for dividend per share is ANNOVA table which pays a very significant role in
regression. This is because this table predict whether the null hypothesis will be rejected or
accepted. In the respect of dividend per share the significance value that is p value is 0.000. this
predicted p value is less than 0.005 significant value. So in this case alternative hypothesis will
be accepted and the null hypothesis is rejected. That means that there is significant impact of
community spending on dividend per share of the companies. The sum square of the above two
dependent and independent variables is 10760.648.
One of the important table is coefficient table that interpreted the true regression value of the
dependent variable in terms of independent variable. The regression equation for community
spending in context of dividend per share is
Community spending = 19.786 -11.660
= 8.126
It is summarized that community spending impact the market value and popularity of the chosen
companies in large manner.
Paraphrase This Document
Need a fresh take? Get an instant paraphrase of this document with our AI Paraphraser
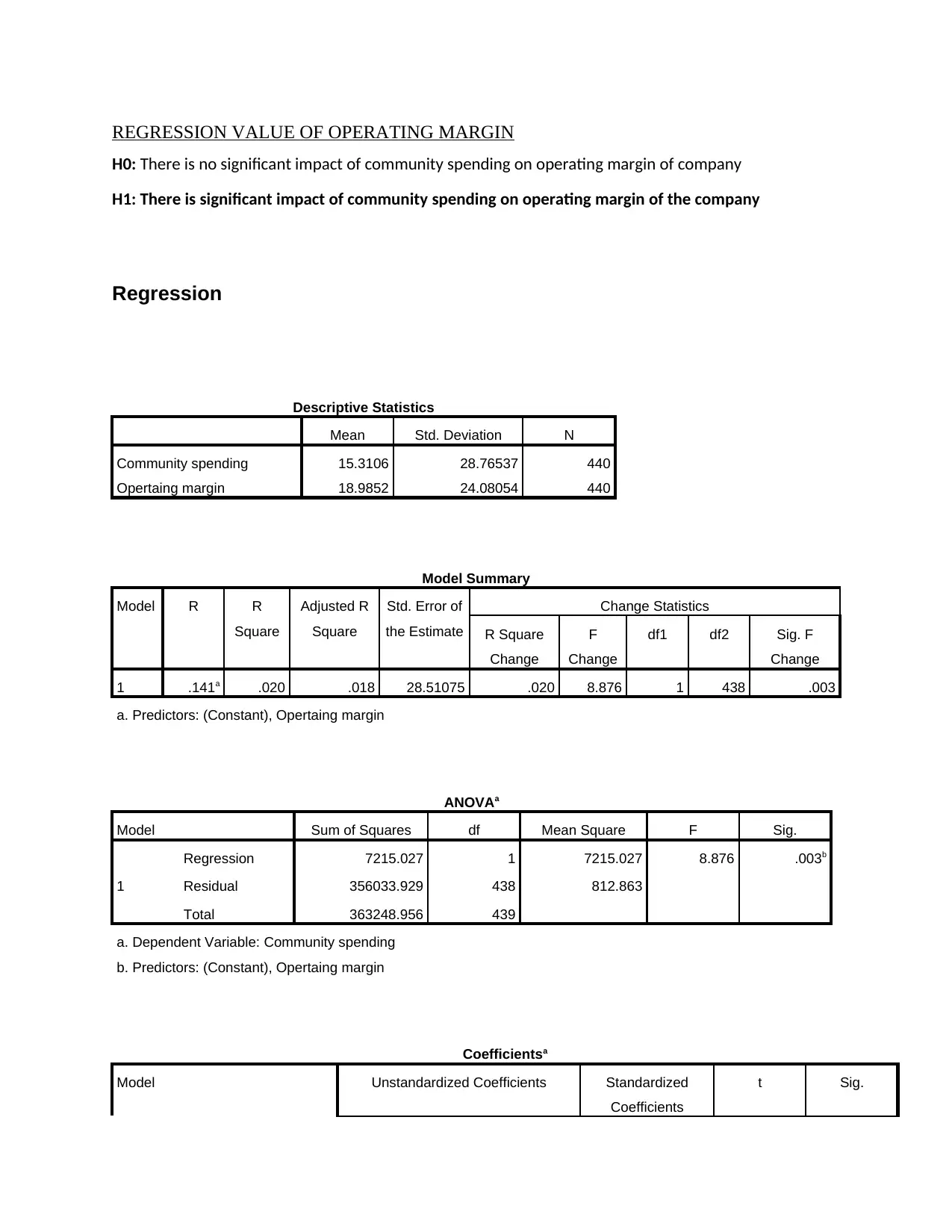
REGRESSION VALUE OF OPERATING MARGIN
H0: There is no significant impact of community spending on operating margin of company
H1: There is significant impact of community spending on operating margin of the company
Regression
Descriptive Statistics
Mean Std. Deviation N
Community spending 15.3106 28.76537 440
Opertaing margin 18.9852 24.08054 440
Model Summary
Model R R
Square
Adjusted R
Square
Std. Error of
the Estimate
Change Statistics
R Square
Change
F
Change
df1 df2 Sig. F
Change
1 .141a .020 .018 28.51075 .020 8.876 1 438 .003
a. Predictors: (Constant), Opertaing margin
ANOVAa
Model Sum of Squares df Mean Square F Sig.
1
Regression 7215.027 1 7215.027 8.876 .003b
Residual 356033.929 438 812.863
Total 363248.956 439
a. Dependent Variable: Community spending
b. Predictors: (Constant), Opertaing margin
Coefficientsa
Model Unstandardized Coefficients Standardized
Coefficients
t Sig.
H0: There is no significant impact of community spending on operating margin of company
H1: There is significant impact of community spending on operating margin of the company
Regression
Descriptive Statistics
Mean Std. Deviation N
Community spending 15.3106 28.76537 440
Opertaing margin 18.9852 24.08054 440
Model Summary
Model R R
Square
Adjusted R
Square
Std. Error of
the Estimate
Change Statistics
R Square
Change
F
Change
df1 df2 Sig. F
Change
1 .141a .020 .018 28.51075 .020 8.876 1 438 .003
a. Predictors: (Constant), Opertaing margin
ANOVAa
Model Sum of Squares df Mean Square F Sig.
1
Regression 7215.027 1 7215.027 8.876 .003b
Residual 356033.929 438 812.863
Total 363248.956 439
a. Dependent Variable: Community spending
b. Predictors: (Constant), Opertaing margin
Coefficientsa
Model Unstandardized Coefficients Standardized
Coefficients
t Sig.
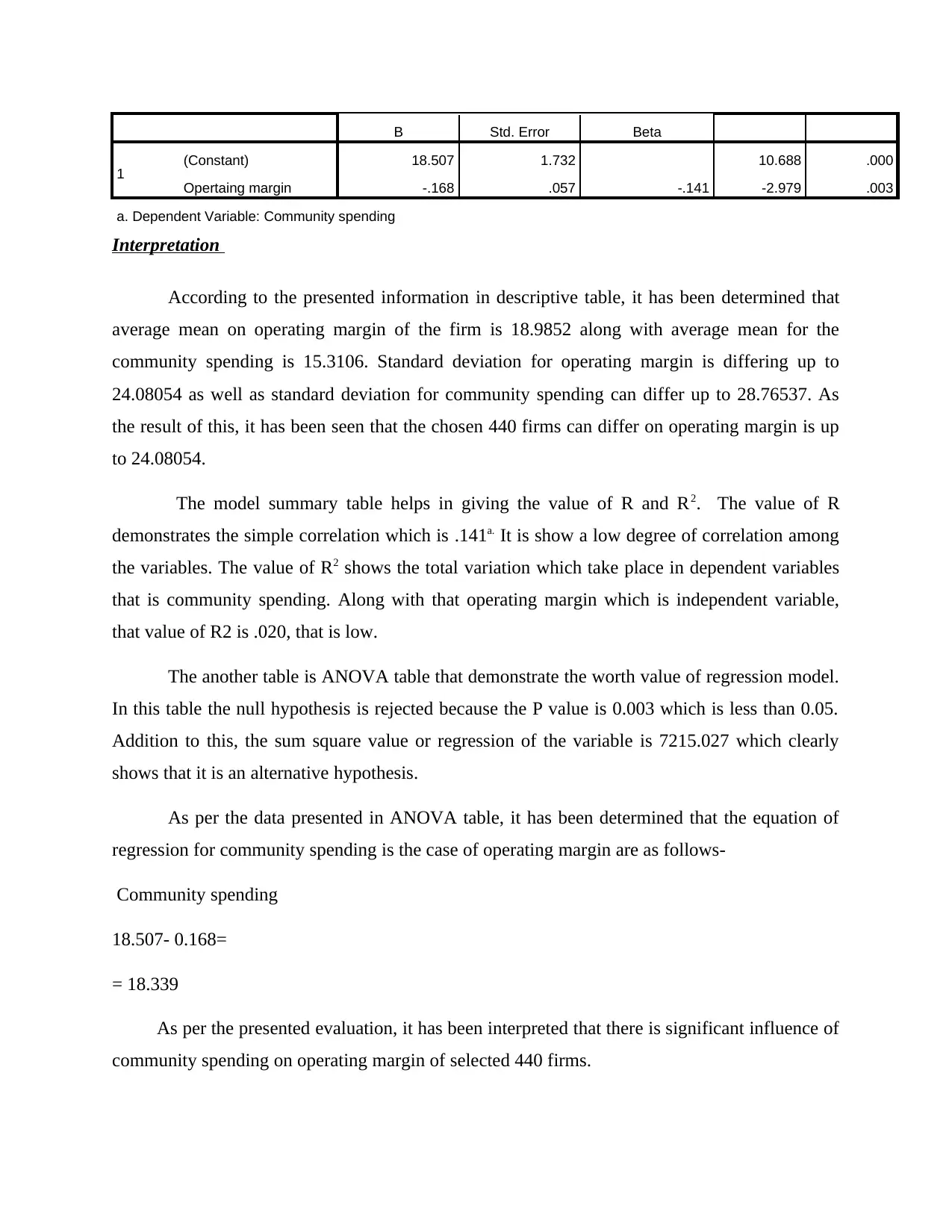
B Std. Error Beta
1 (Constant) 18.507 1.732 10.688 .000
Opertaing margin -.168 .057 -.141 -2.979 .003
a. Dependent Variable: Community spending
Interpretation
According to the presented information in descriptive table, it has been determined that
average mean on operating margin of the firm is 18.9852 along with average mean for the
community spending is 15.3106. Standard deviation for operating margin is differing up to
24.08054 as well as standard deviation for community spending can differ up to 28.76537. As
the result of this, it has been seen that the chosen 440 firms can differ on operating margin is up
to 24.08054.
The model summary table helps in giving the value of R and R2. The value of R
demonstrates the simple correlation which is .141a. It is show a low degree of correlation among
the variables. The value of R2 shows the total variation which take place in dependent variables
that is community spending. Along with that operating margin which is independent variable,
that value of R2 is .020, that is low.
The another table is ANOVA table that demonstrate the worth value of regression model.
In this table the null hypothesis is rejected because the P value is 0.003 which is less than 0.05.
Addition to this, the sum square value or regression of the variable is 7215.027 which clearly
shows that it is an alternative hypothesis.
As per the data presented in ANOVA table, it has been determined that the equation of
regression for community spending is the case of operating margin are as follows-
Community spending
18.507- 0.168=
= 18.339
As per the presented evaluation, it has been interpreted that there is significant influence of
community spending on operating margin of selected 440 firms.
1 (Constant) 18.507 1.732 10.688 .000
Opertaing margin -.168 .057 -.141 -2.979 .003
a. Dependent Variable: Community spending
Interpretation
According to the presented information in descriptive table, it has been determined that
average mean on operating margin of the firm is 18.9852 along with average mean for the
community spending is 15.3106. Standard deviation for operating margin is differing up to
24.08054 as well as standard deviation for community spending can differ up to 28.76537. As
the result of this, it has been seen that the chosen 440 firms can differ on operating margin is up
to 24.08054.
The model summary table helps in giving the value of R and R2. The value of R
demonstrates the simple correlation which is .141a. It is show a low degree of correlation among
the variables. The value of R2 shows the total variation which take place in dependent variables
that is community spending. Along with that operating margin which is independent variable,
that value of R2 is .020, that is low.
The another table is ANOVA table that demonstrate the worth value of regression model.
In this table the null hypothesis is rejected because the P value is 0.003 which is less than 0.05.
Addition to this, the sum square value or regression of the variable is 7215.027 which clearly
shows that it is an alternative hypothesis.
As per the data presented in ANOVA table, it has been determined that the equation of
regression for community spending is the case of operating margin are as follows-
Community spending
18.507- 0.168=
= 18.339
As per the presented evaluation, it has been interpreted that there is significant influence of
community spending on operating margin of selected 440 firms.
⊘ This is a preview!⊘
Do you want full access?
Subscribe today to unlock all pages.
Trusted by 1+ million students worldwide
1 out of 16
Related Documents





Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Unlock your academic potential
Copyright © 2020–2026 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.