FIT1043 Assignment 2: Data Science Project - Ocean Atmosphere Analysis
VerifiedAdded on 2022/11/09
|9
|921
|62
Project
AI Summary
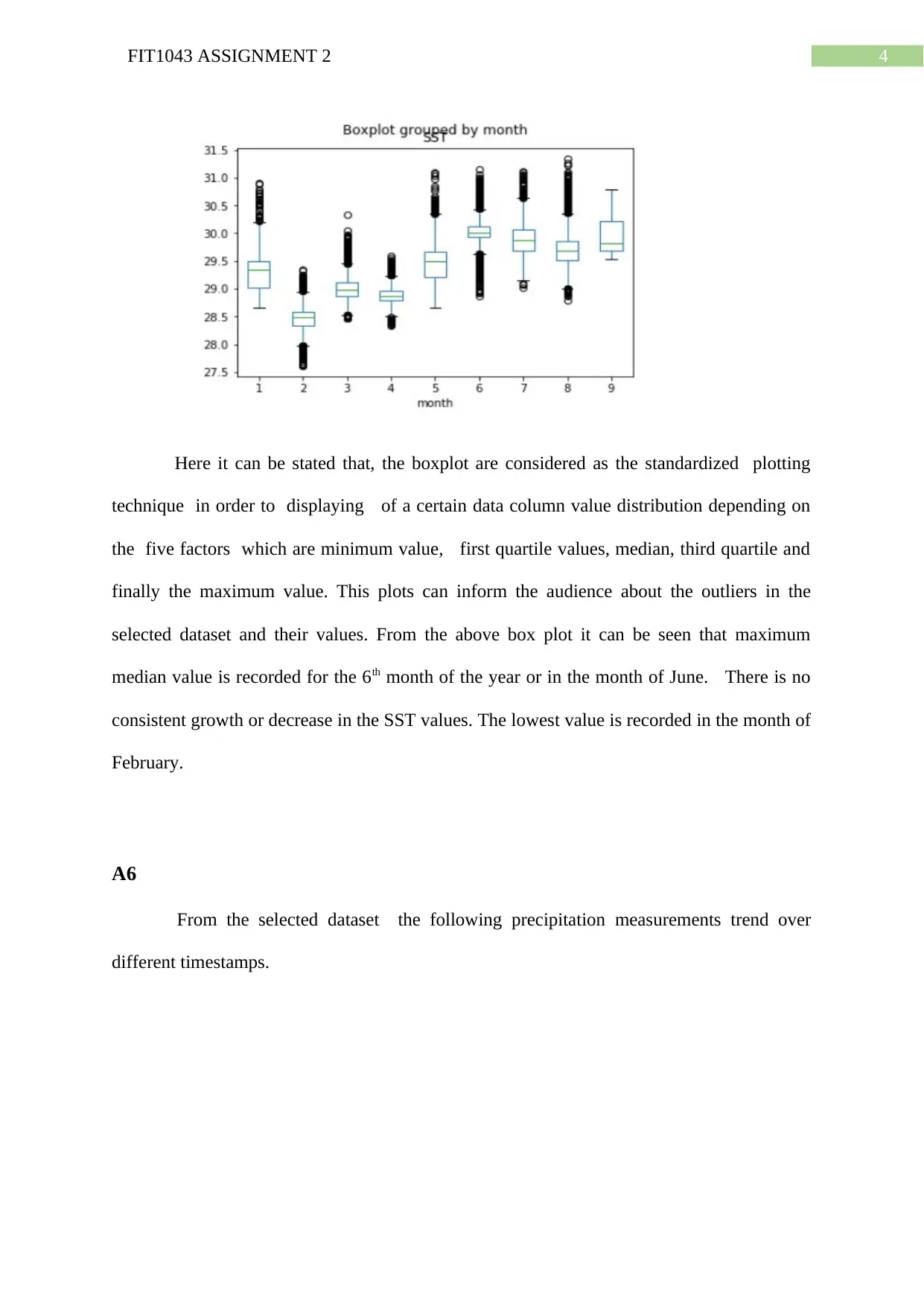
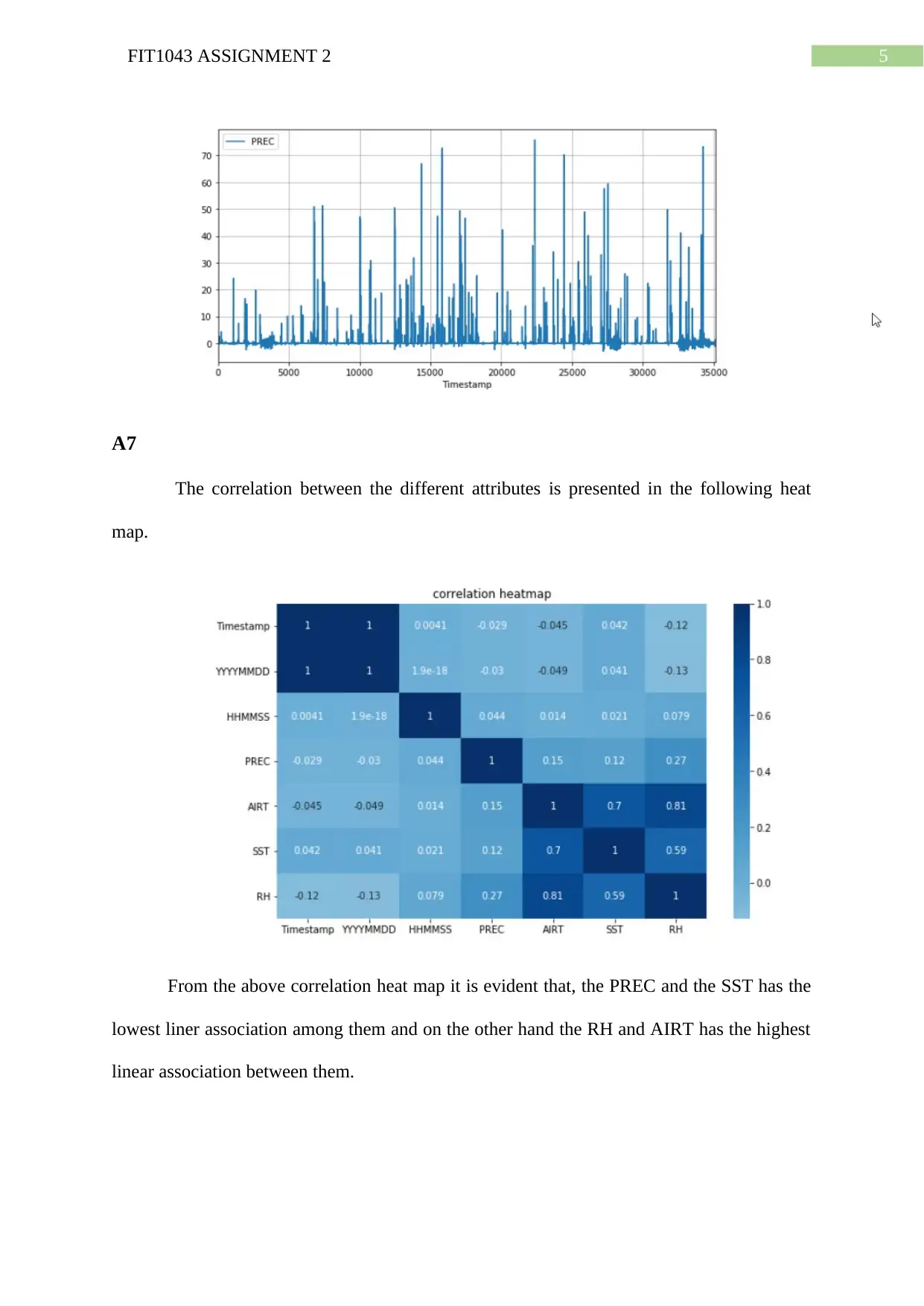
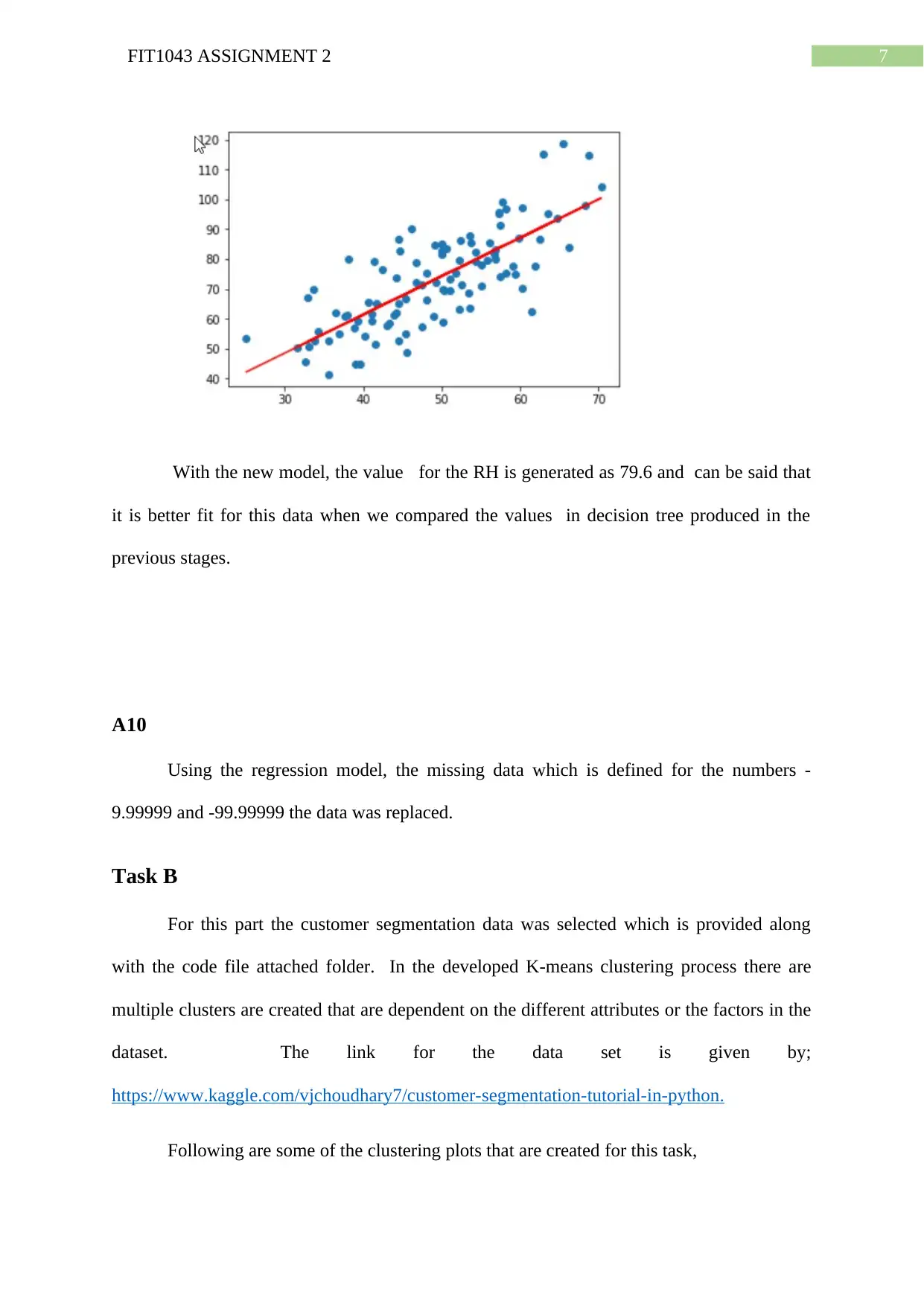
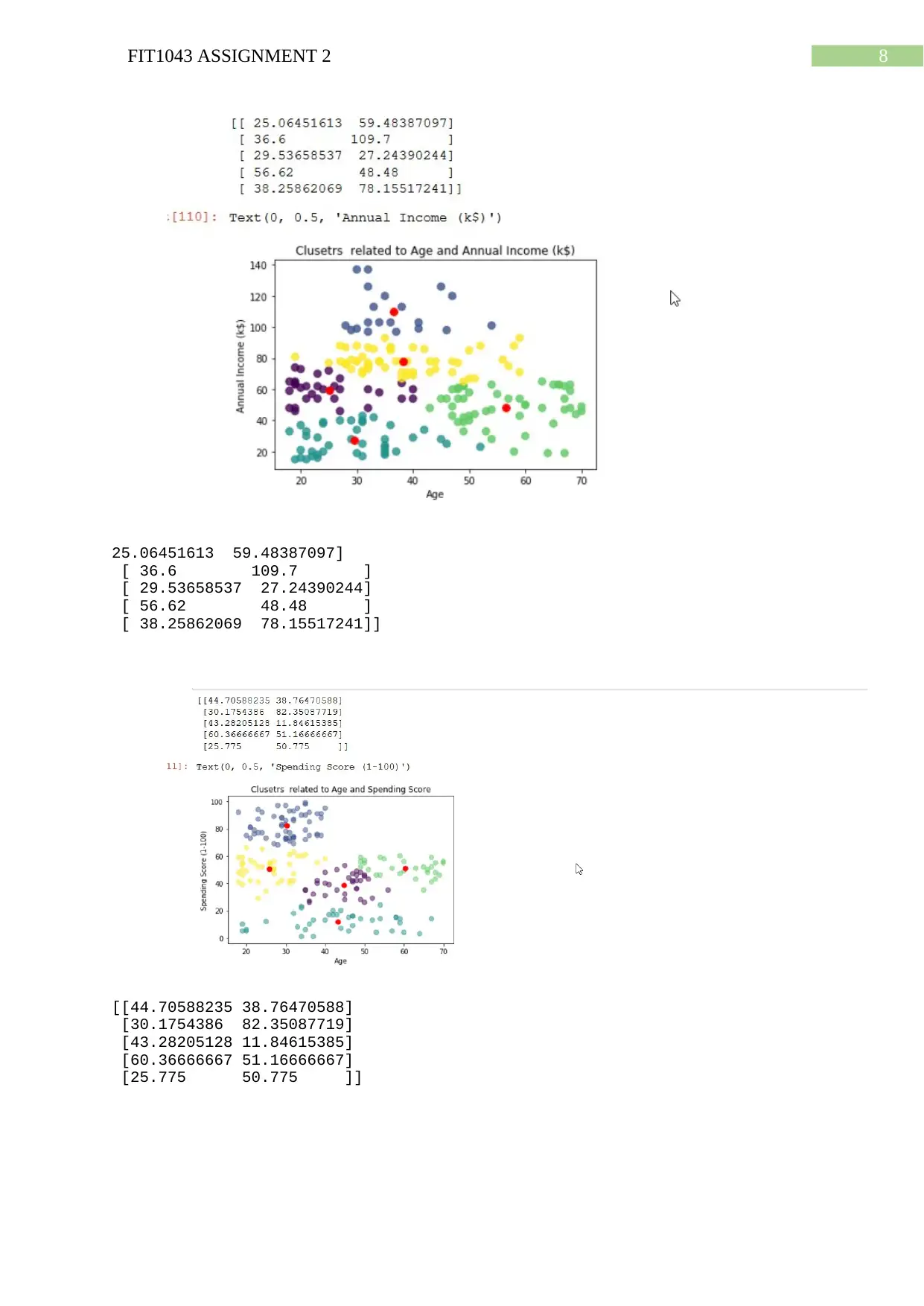
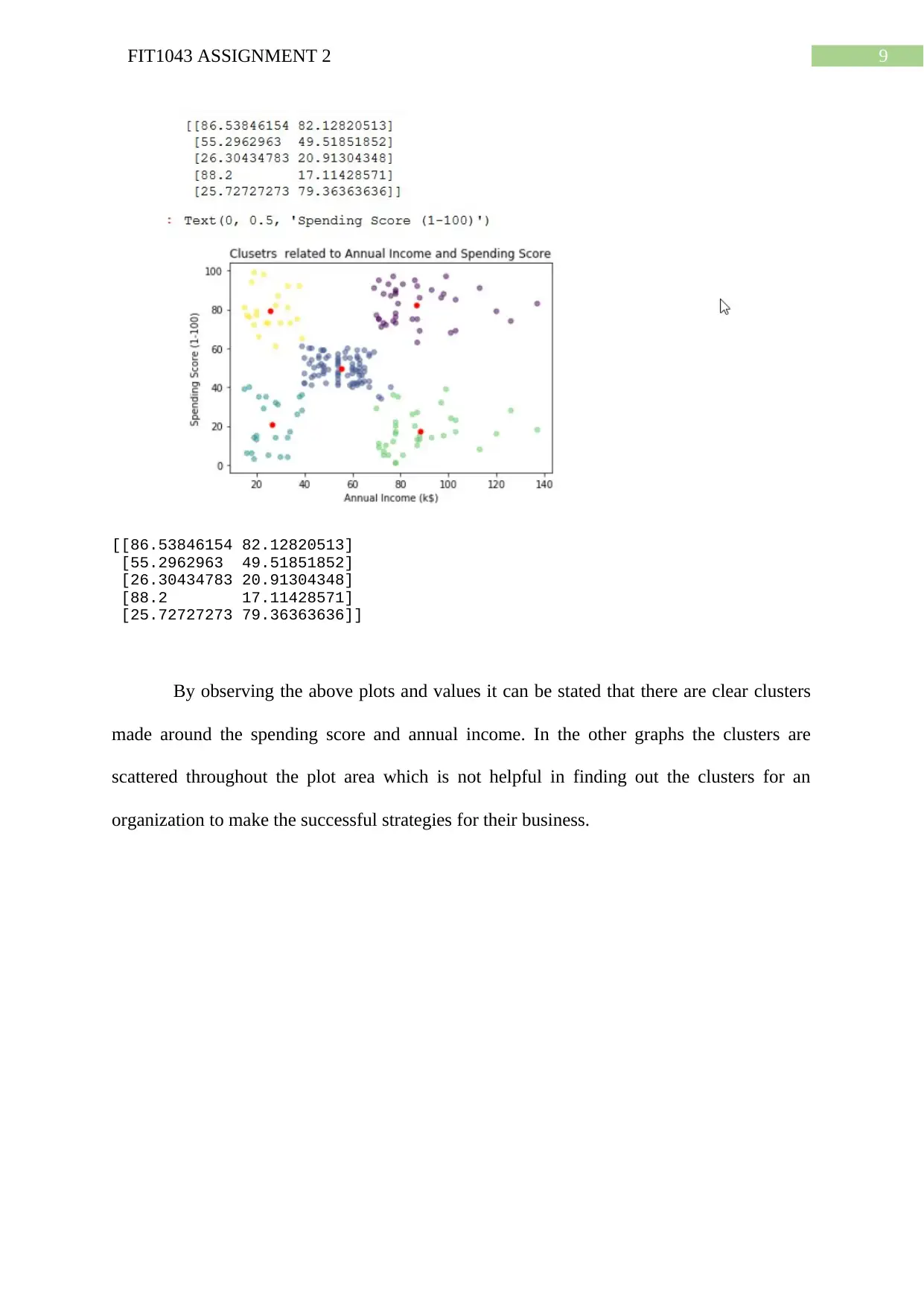
This document presents a comprehensive solution for FIT1043 Assignment 2, a data science project focused on analyzing the Tropical Atmosphere Ocean (TAO) dataset using Python. The assignment involves reading and extracting data, performing data exploration, data wrangling, and analysis. The solution includes calculating descriptive statistics (minimum and maximum values), data type conversions, handling missing values, and generating visualizations such as box plots and heatmaps to depict sea surface temperature trends, precipitation measurements, and attribute correlations. Furthermore, the solution implements decision tree and regression models for prediction and also provides the analysis of customer segmentation data using K-means clustering. The accuracy of the decision tree model is evaluated, and the predicted values are compared with the original data. The assignment demonstrates the application of Python libraries like pandas, matplotlib, and scikit-learn for data manipulation, analysis, and machine learning tasks. The solution also discusses the creation of clusters based on annual income and spending scores.




1 out of 9
Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Copyright © 2020–2026 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.