Multiple Regression Analysis for Food Truck Case Study - SCMA 3300
VerifiedAdded on 2022/08/29
|9
|1106
|21
Homework Assignment
AI Summary
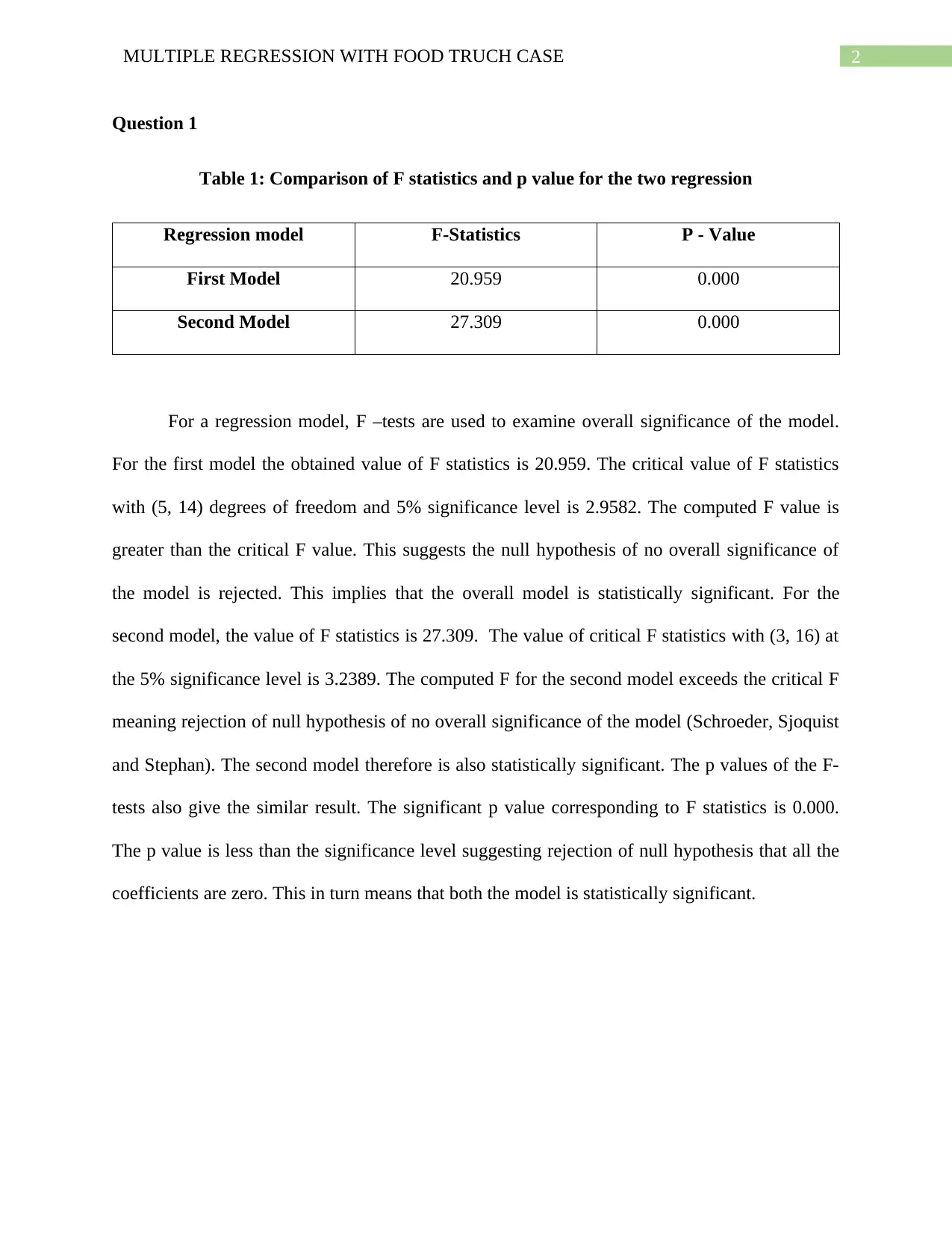
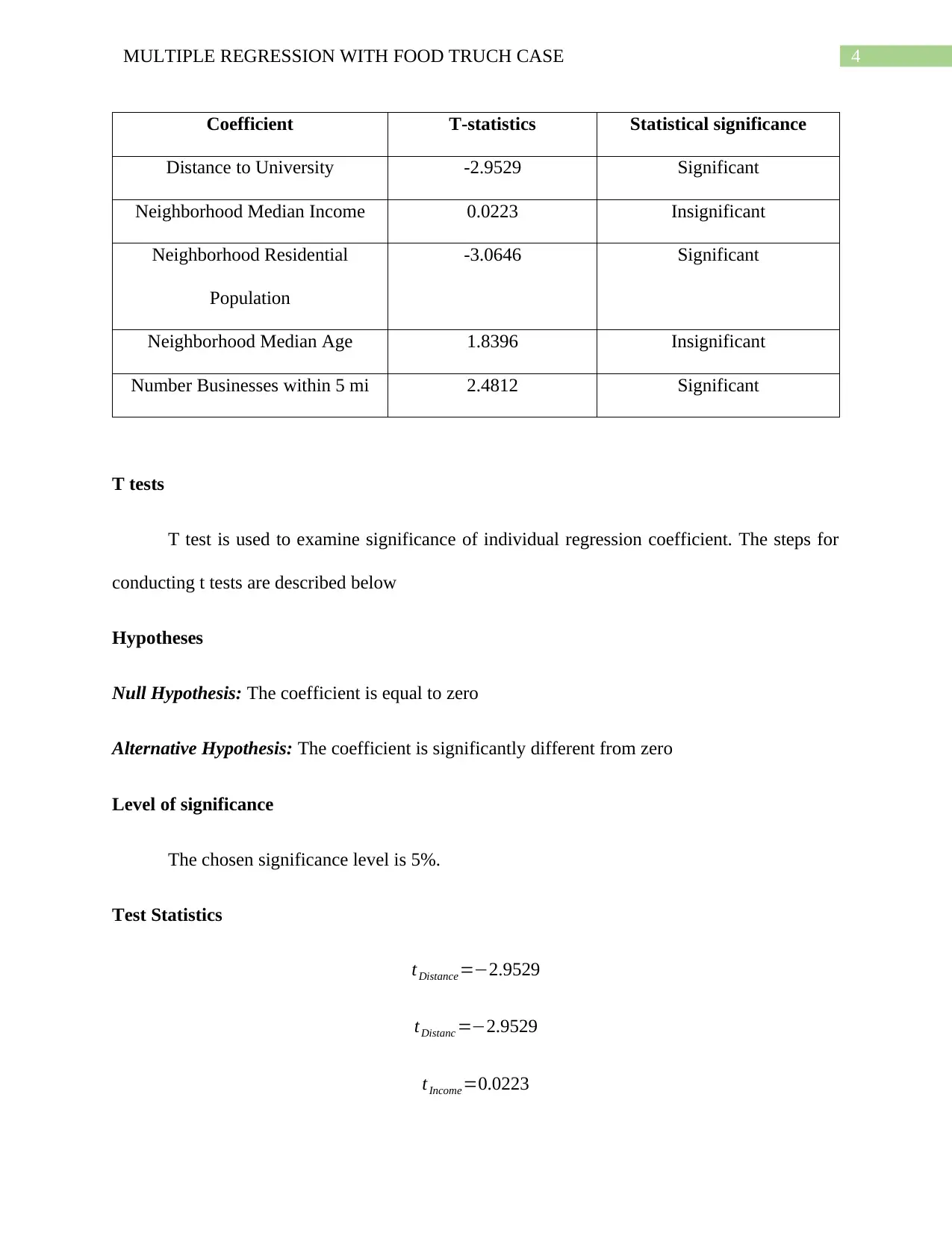
This document presents a comprehensive analysis of a food truck case study using multiple regression techniques. The assignment involves two regression models, examining the significance of various location-based factors on the food truck's daily sales. The student conducts F-tests to assess the overall significance of each model, comparing computed F-statistics with critical values and p-values. Furthermore, t-tests are performed to evaluate the significance of individual regression coefficients, identifying which variables significantly influence daily sales. The analysis includes the interpretation of adjusted R-squared values to compare the explanatory power of the two models and selection of the most suitable model based on statistical significance of predictor variables. The student concludes by selecting the second model due to the statistical significance of all its variables, making it a better predictor of profitability. The document includes tables summarizing the statistical results and references to relevant academic literature.







1 out of 9
Related Documents






Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Copyright © 2020–2026 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.