University of Hertfordshire: Data Classification Project 7COM1073
VerifiedAdded on 2022/09/02
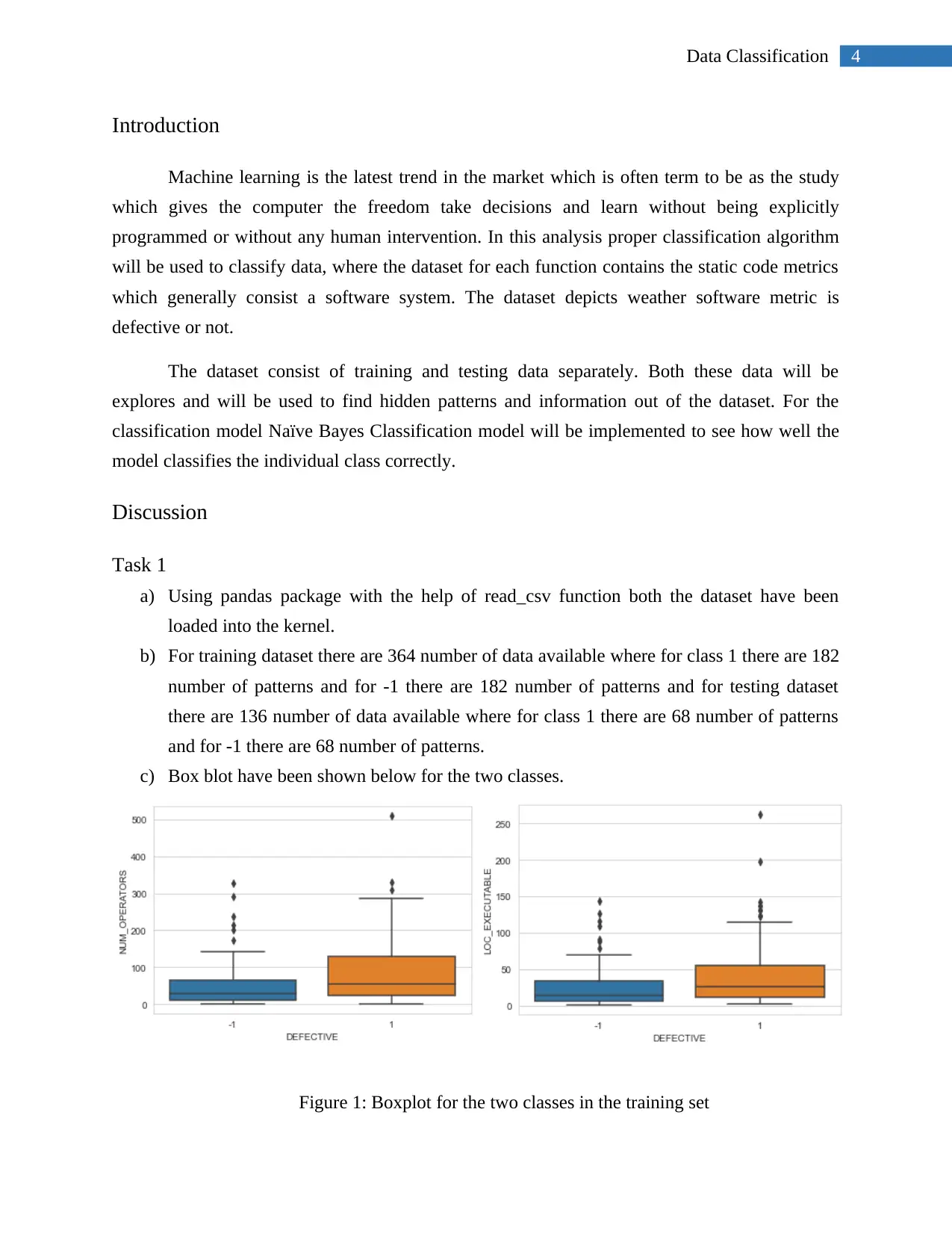
|10
|1341
|18
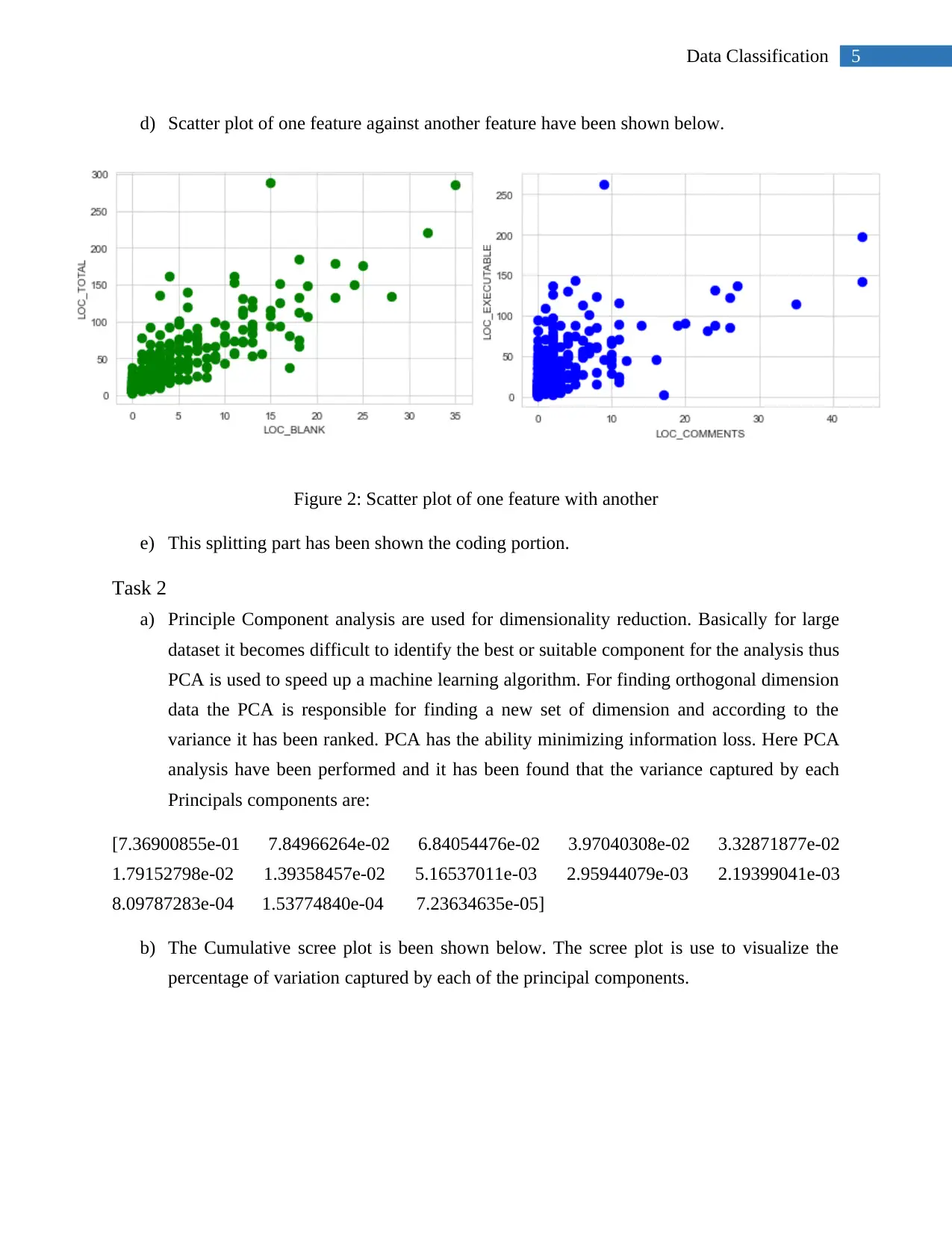
Project
AI Summary
This project focuses on data classification using machine learning techniques to predict software defects. The student utilized a dataset containing static code metrics and employed the Naive Bayes classification model to classify the data. The project involved data exploration, visualization using box plots and scatter plots, and dimensionality reduction using Principal Component Analysis (PCA). The student implemented and evaluated the Naive Bayes classifier, analyzing its performance through accuracy, classification reports, and confusion matrices. Different features were tested to determine the optimal feature set for the model. The conclusion indicates that the Naive Bayes model was not a good fit for this particular dataset. The student suggested exploring other algorithms for future reference. The project follows the guidelines provided by the University of Hertfordshire for the Foundations of Data Science module (7COM1073).



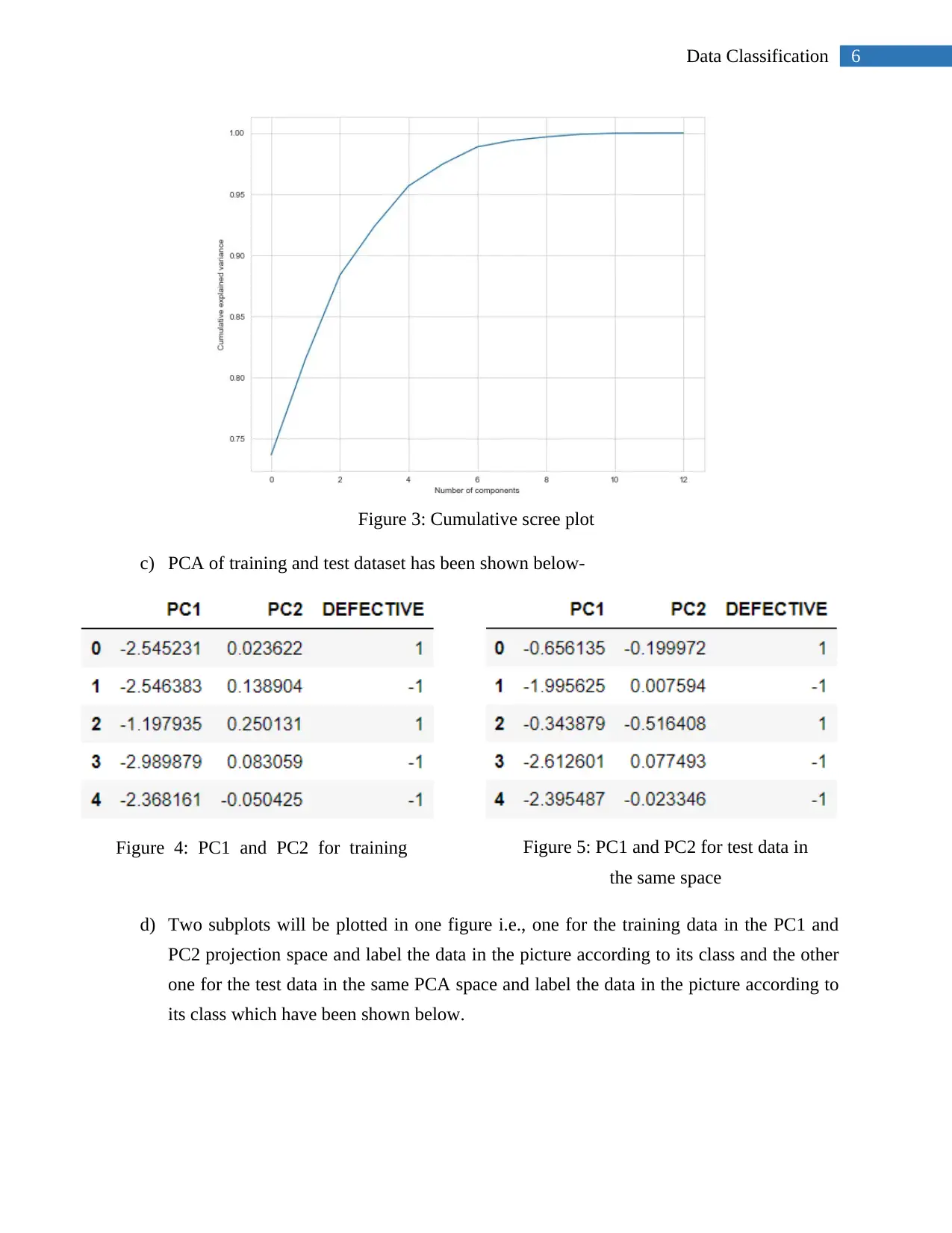


1 out of 10
Related Documents






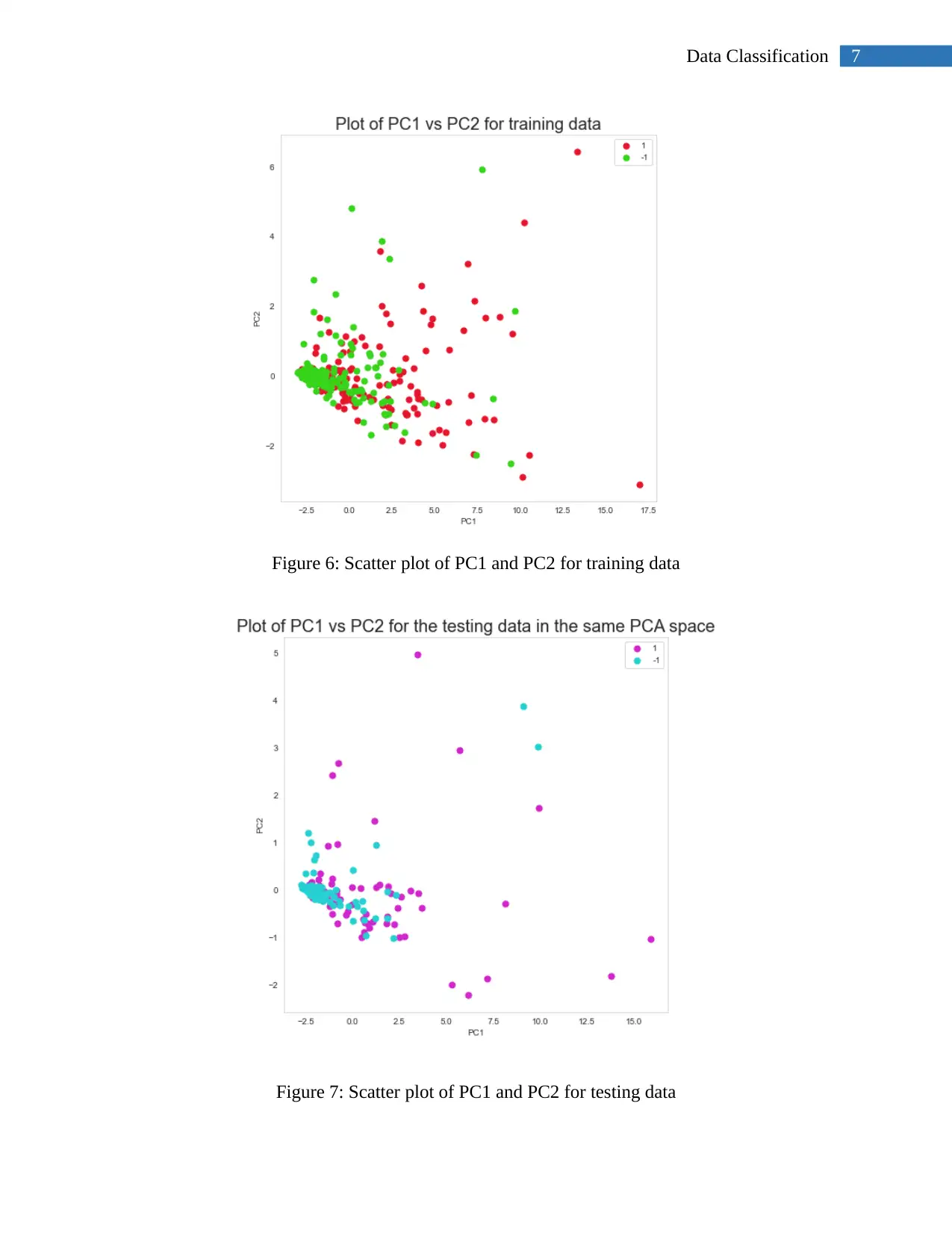
Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Copyright © 2020–2026 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.