Hadoop File System: Forensic Investigation and Architecture Report
VerifiedAdded on 2022/11/13
|10
|1804
|404
Report
AI Summary
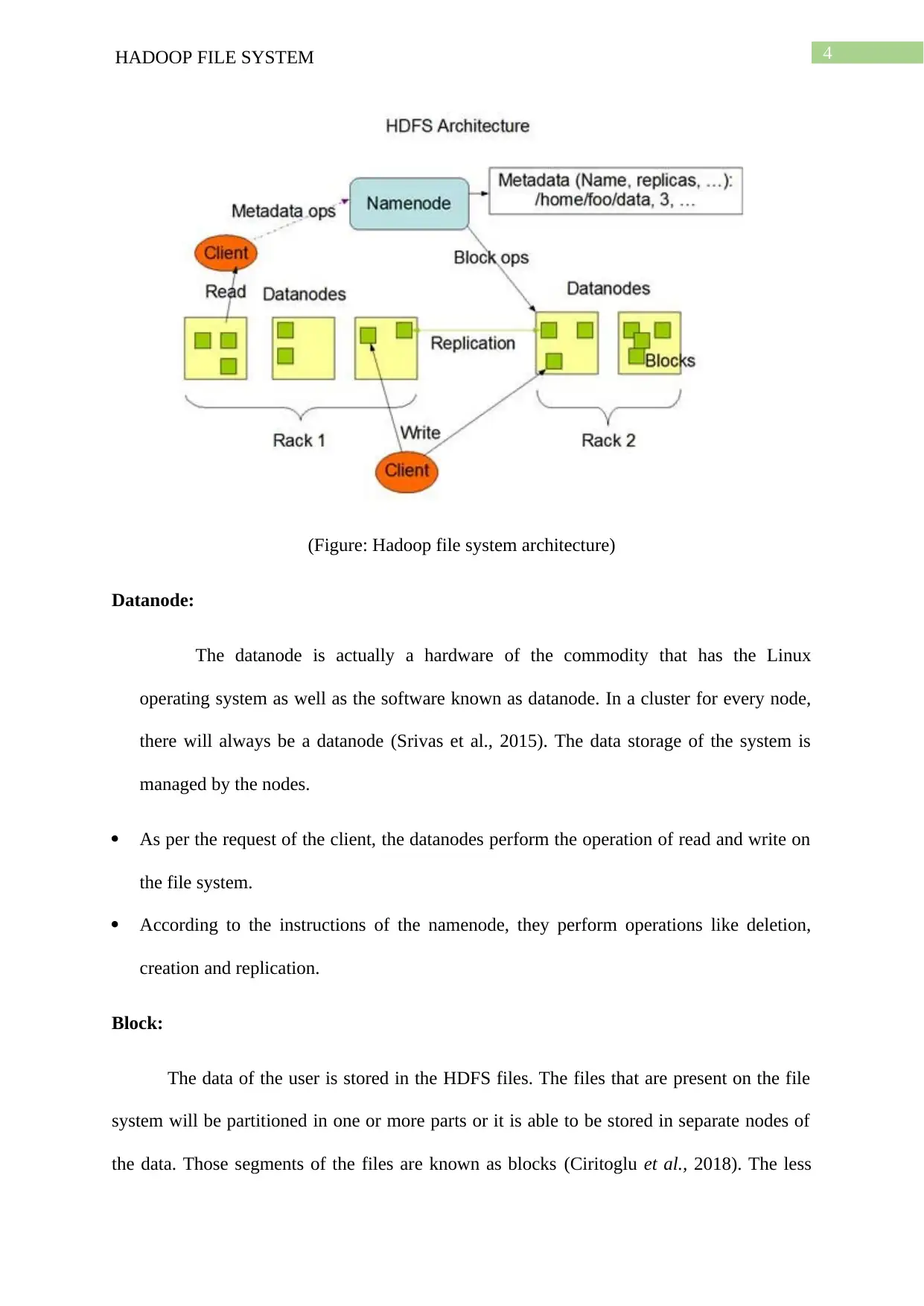
This report provides a comprehensive overview of the Hadoop File System (HDFS), its internal architecture, and its application in forensic investigations. It begins with an executive summary and introduction to Hadoop, emphasizing its role in big data storage and processing. The report details the core components of the Hadoop architecture, including the namenode, datanode, and blocks, explaining their functions and interactions within the HDFS. Furthermore, it delves into the structures of the HDFS, such as CheckpointNode, BackupNode, and file system snapshots, elucidating their roles in data management and system recovery. The report then focuses on HDFS forensic investigation, outlining different categories of forensic data within Hadoop, including information support, evidence of record, and application/user evidence, which can be useful in digital forensic investigations. The report concludes by summarizing the key findings, emphasizing the importance of HDFS in storing large amounts of data and its relevance to forensic analysis.









1 out of 10
Related Documents






Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Copyright © 2020–2026 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.